| |
|
|
| ֪ʶ�� -> ���� -> Ϊʲô4090�Ĺ����4070�Ľ���3��������ȴֻ��2����ƿ�����ģ� -> �����Ķ� |
|
|
[����]Ϊʲô4090�Ĺ����4070�Ľ���3��������ȴֻ��2����ƿ�����ģ� |
| [�ղر���] �����ر��ġ� |
|
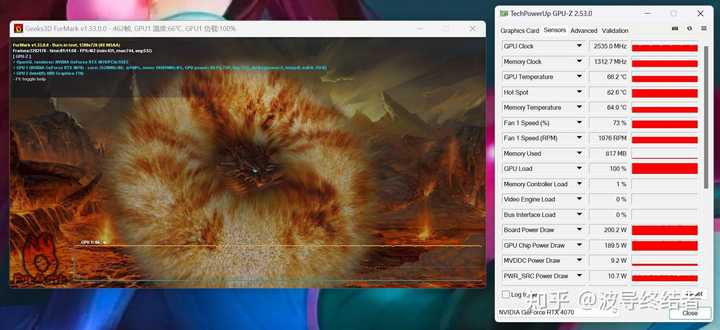
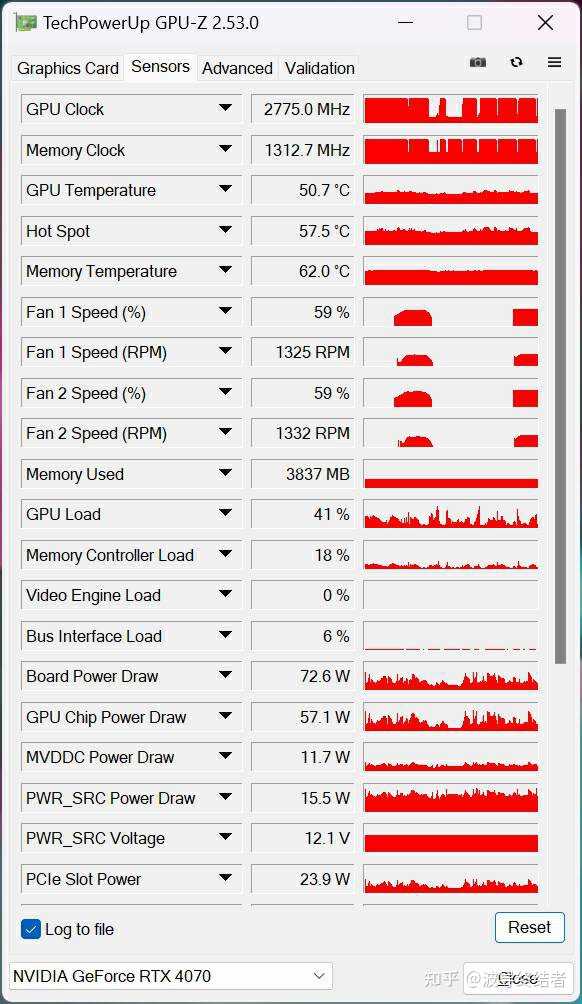
�ο���UserBenchmark; Techpowerup [ͼƬ] [ͼƬ] ���������Ϸ֡�ʵĻ���������϶�������С�ɣ� |
|
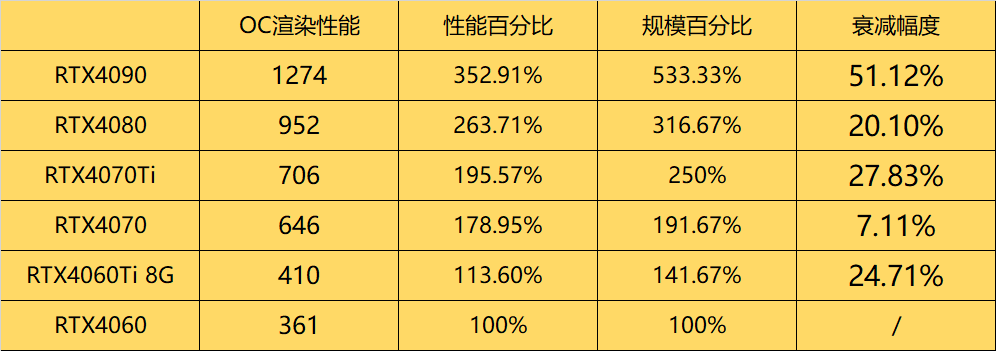
4090�������ͷ������ƺ���ЧӦ�������� ��GPU���ֳ����ģ���м���Ķ������������ֳ����ܲ��ľ���GPU��Ⱦ�����㣬��Ϊ������;��ѹ������ȫ��GPU�ϣ���̫�����������ص�Ӱ�� ��ֱ�Ӵ�OC��Ⱦ��benchmark���ݰ��ϰ�40ϵ�Կ��ijɼ����������δ��RT�ijɼ�����˳����һЩ���� |
|
|
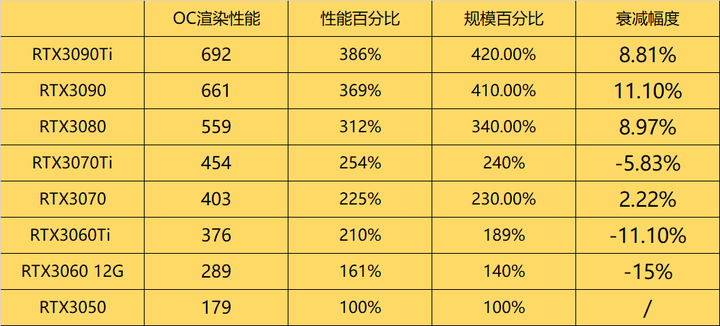
����ɼ����Һ����⣬4090����4070������������Ⱦ�����ˣ���Ϊ����ǰ���Կ����������û�г���������������ӽ������Ĺ�ģ���ܳ�����������Ⱦ���� �����Ҽ�����һ�����˥�����ȣ��ӽ���������������ɻ����Դ�������ܳ�Ϊ��RTX40ϵһ����ƿ�����ڣ���������˵С�����Դ�������RTX40ϵ�ܶ��Կ���δ�ܳ������е����� ����͵ľ���4060Ti 8G�ˣ�������������������4060����41.67%�����Դ�������Ը�һ�㣬���ս��������Ⱦ���ܽ�����13.6% ��4070������������ģ��4060Ti������35.3%������£���Ⱦ����ǿ��57.56%��4070���Դ���192bit 21Gbps�����մ���Ϊ504GB/s������4060Ti��288GB/s����75% �Ҽǵ���ǰ���Կ���OC��Ⱦ��û�п���ȥ��ע�������ģ�����˵RTX30ϵ����� |
|
|
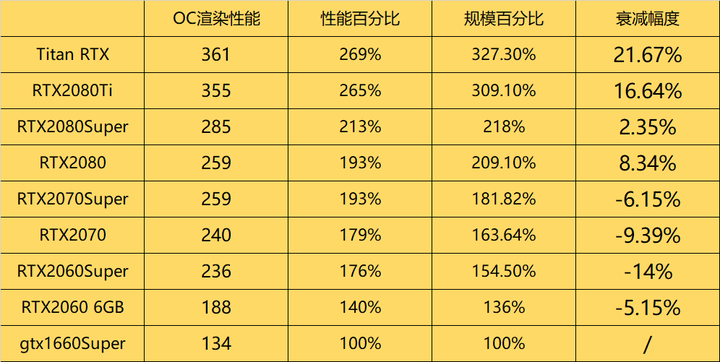
���ָ�˥������ζ�������������ڹ�ģ��������Ϊ�Դ����������������˸������� 30ϵ��˥��������֮����ľͼ����Ǻ��Բ��Ƶ����֣��Դ���������û����ôͻ����������ǰ����GPU��Ⱦ����ͨ��������Ⱦ���ܸ���ģ�ҹ� ������RTX20ϵ |
|
|
GDDR6�Դ滹δ����ʱ���и߶���һ����˥���� �������������ţ�RTX40ϵ�߶˵�ƿ���Ѿ����������ˣ���GPU��Ⱦ��;���Ѿ���ʼ˥���ĺ������ˣ� ���Զ���RTX4090��Ⱦ���ܽ���4070��������������⣬�����ػ����Դ����������һ�������⣬��Ҳ����GDDR7�Դ�û�м�ʱ���й�ϵ ��һ������Ҳ����Ada Lovelace�ܹ��ı�ЧӦ�����Dz��Ǹ��������ˣ���Ϊ��Ŀǰ��֪����Ϣ������Ada Lovelace�ܹ������30ϵ��Ampere�ܹ���˵�����Ǽ�����һЩ�����ԣ�����˵���Ĵ�Tensor Core��������RT Core�Լ���������������L2��Щ��Ȼ����̨����4N���գ������ģ���Ƶ�ʣ������������ ��AD102���ĵ������������������GA102����̫���ˣ�4090����������������3090Ti����52.4%�����Դ������ȫһ��������1008GB/s��Ҳ����˵����SM�Ĺ�դ��Ⱦ�����������ܽ���Ƶ����ߣ�����ܻᵼ�³����ģ��GPU����Ч���½������� ������һ��GPU�ļܹ��Լ�����GDDR7�Դ�֮����ܿ������ֹ�ģ��GPU���е�ʵ���˰� ����˵��Ϸ���棬��Ϸ�������Ⱦ��˵������������Ӱ�����أ�����˵CPU���ڴ棬��϶��������ܲ���һ����С�ġ� |
|
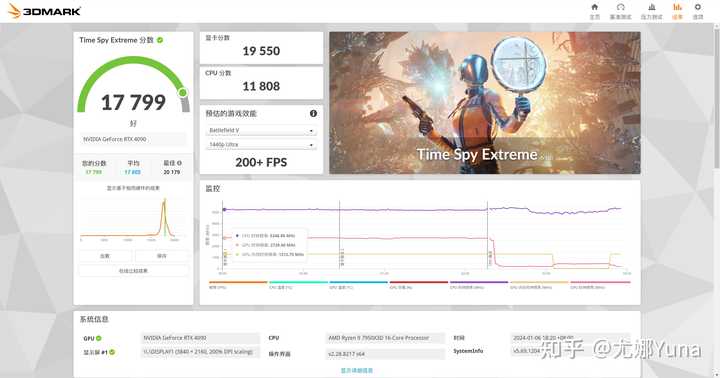
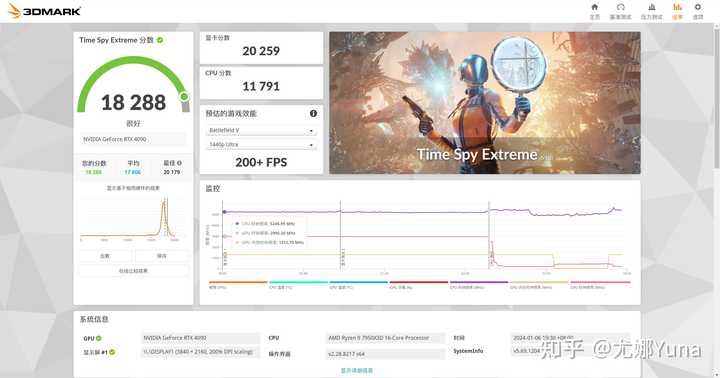
�𰸷���ǰ�棺�Դ������ �����Կ������������һ̨���ֻ������� GPU���Ķ�ӦCPU���������㹤�����Դ��Ӧ�ڴ棬����洢�������ݣ���·���Ӧ���壬�������оƬ/�ڴ沢�ṩ������ɢ������ӦCPUɢ����������ɢ�ȹ����� ��һ�źϸ�ij�Ʒ�Կ����ԣ���·���ɢ������Ȼ�����㹻ʹ�õģ�������Ӱ��������ܷ��ӵģ����ܳ�Ϊ��ƿ�����IJ�ȷ�����أ���Ȼ�ͻ�ʣ���Դ��ˡ� ǡ������������һ̨RTX 4090̨ʽ����һ̨RTX 3060�ʼDZ�����3DMark Time Spy Extreme�����ļ��TSE��������ʵ�飬�����Ŀѹ������Ա�֤�Կ���������100%�� RTX 4090̨ʽ��ĬƵ����TSEʱ��ͼ�η���Ϊ19550��ȡ����һ���ظ�����ʱ���ʱ��㣬�Կ�����������2729.40MHz�� |
|
|
���Կ���Ƶ��ֻ�����ģ������Դ棩��ͼ�η���Ϊ20259������������2995.20MHz����Ƶ��Ƶ�ʽ�֮ĬƵ����������9.7%�����ܷ�ȴֻ������3.6%����Ȼ�����ϱ����� |
|
|
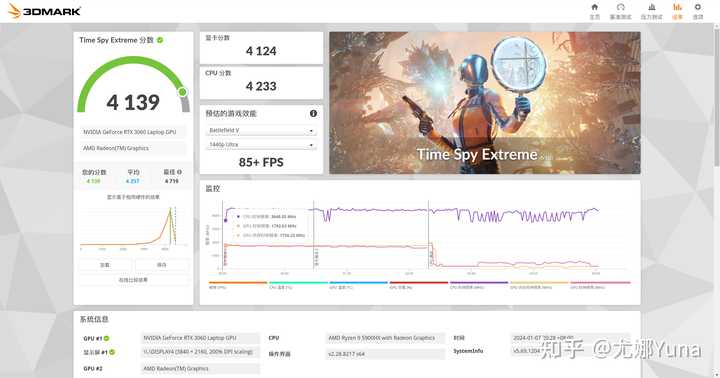
RTX 3060�ʼDZ�ĬƵ����TSEʱ��ͼ�η���Ϊ4124��ͬһ��ʱ��㣬����������1792.63MHz�� |
|
|
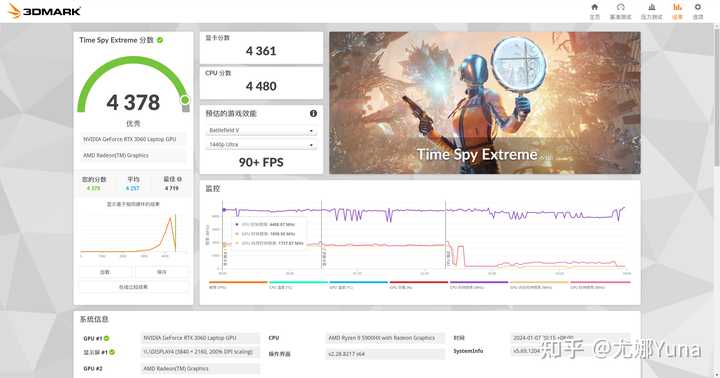
ͬ�����Կ�������Ƶ���ĺ�ͼ�η���Ϊ4361������������1898.50MHz����Ƶ��Ƶ�ʽ�֮ĬƵ������5.9%���ܷ���ӦҲ������5.7%������ͱȽϷ��ϱ����ˡ� |
|
|
Ȼ�������������������� ���۸��������������ȣ���RTX 4090̨ʽ����82.58����λTFLOPS������RTX 3060�ʼDZ���10.94����7.5�����ϡ��Դ������RTX 4090��1008����λGB/s����ֻ��RTX 3060��336����3���� �ɼ�RTX 4090���Դ����ƿ���Ƿdz�֮���صġ����������϶�RTX 3060�Ĵ�����֮���ĺ������ܾ�һ�����ã���RTX 4090���Կ϶������á�������������TSE�ܷ���飬��ĬƵʱ�����������ﵽRTX 3060 7.5��+��RTX 4090���ܷ�ȴֻ��ǰ�ߵ�4.7��+�� �������������ʵ�RTX 4070���� ���۸�������29.15��RTX 4090������2.8��+���Դ����504��RTX 4090������2����TSE�ֲܷο�3DMark������ͳ�ƽ������ֵΪ8484��RTX 4090������Լ2.3���� ���Dz�������ͬ����ʵ���Ͽ�RTX 4070 TiҲ��һ���������������������ﵽ40.09����RTX 4070Ҫǿ37.5%������Ϊ�Դ������ȫһ��������TSE�ܷ־�ֵ10921��ֻǿ28.7%�� ��չ�Ķ����� ����Yuna����������2023.12�ʼDZ�/DIY̨ʽ���Ƽ�����58 ��ͬ �� 8 �������� |

|
|
�����Կ��ͼ����Կ�����ȱ��ֱ���ʲô��154 ��ͬ �� 23 ���ۻش� |

|
|
CPU �ϵ����ܲ����ܷ����ڴ������ֲ���67 ��ͬ �� 3 ���ۻش� |

|
|
�ҵ�rx6400,��Ȼ64bit���Ǵ������Ϸ1080p�л���ûʲôѹ���������bit��ʲô�ã�95 ��ͬ �� 11 ���ۻش� |
|
|
|
|
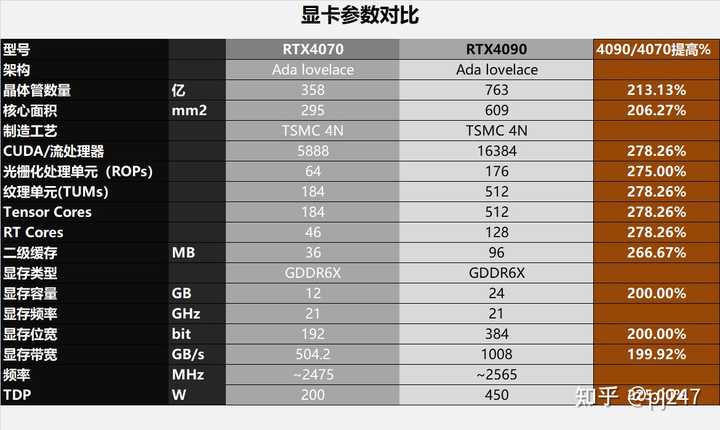
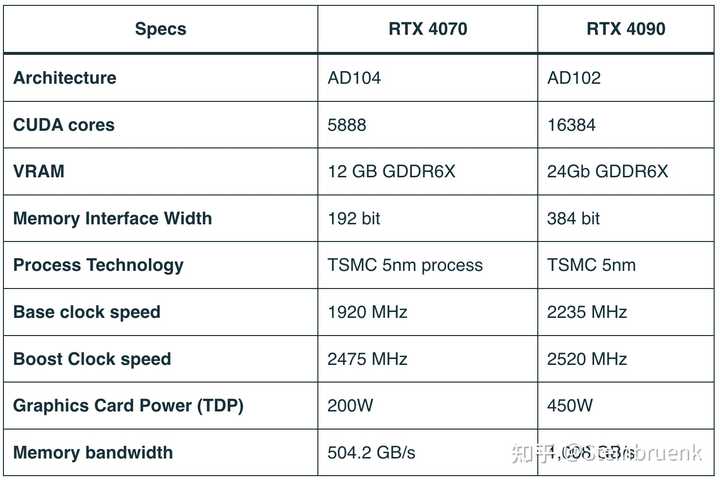
ƿ�����Դ�����ɣ��ϸ���˵RTX 4090�Ĺ����RTX 4070��3���� RTX 4090����AD102-300-A1���ģ�����16384��CUDA��Ԫ������Ƶ�� 2.52 GHz���Դ�Ϊ 24GB 384 bit GDDR6X���Դ����Ϊ1008 GB/s���Կ��ܹ���Ϊ 450W�� RTX 4070����AD104-250-A1���ģ�����5888��CUDA��Ԫ������Ƶ�� 2.475 GHz���Դ�Ϊ 12GB 192 bit GDDR6X���Դ����Ϊ504.2 GB/s���Կ��ܹ���Ϊ 200W�� RTX 4090�ĺ��Ĺ�ģ��RTX 4070��2.78�����Դ������RTX 4070��2�����Դ�����Ҳ��RTX 4070��2����Խ�Ƿֱ��ʸߵ���Ϸ��������Ӱ���Խ���ԡ� �ο���ȥ���RTX 4090��RTX 4070�IJ��ԣ���4K�ֱ�����һ��������10��3A��Ϸ�����Σ�ƽ������RTX 4090����Ϸ֡����RTX 4070��2.023�����պþ��������Կ��Ĵ�����ࡣ |
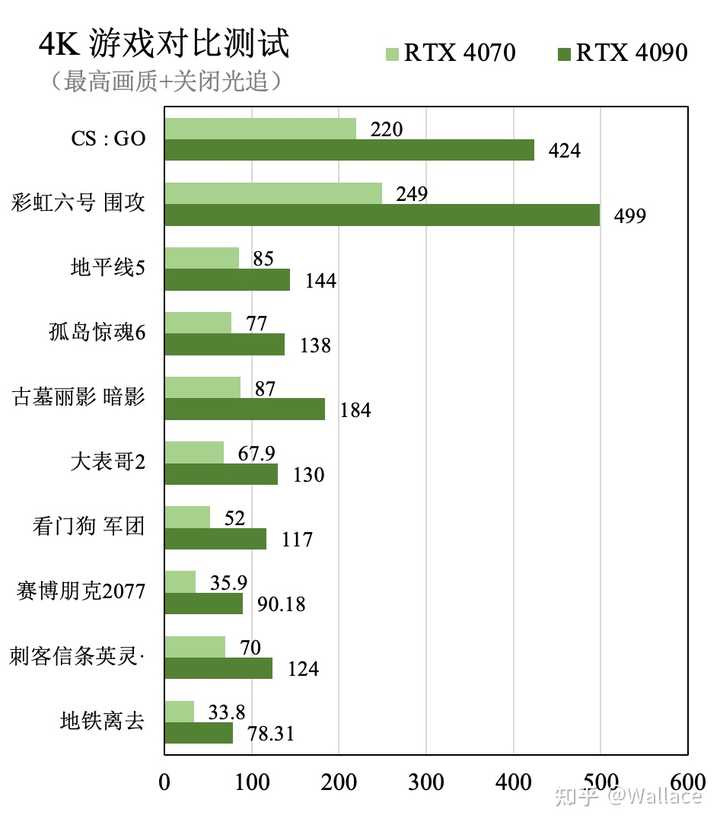
|
|
��Ȼ���Կ���Ӧ�ó���������������Ϸ���ܶ��˻����һЩAIGC����Ĵ�����RTX 4090���ܱ���Ҳ�����RTX 4070��2�����ҡ� ����AIGC��ͼӦ��Stable Diffusion���ܹ��ܹ������ı���ʾ���ɸ�������ͼ��Tom's Hardware������45���Կ�����Stable Diffusion�����ԣ����Ժ��֣����趨Ϊ515*515�ֱ���ʱ��RTX 4090�����ٶ���RTX 4070��2.28�����趨��768*768�ֱ����£�RTX 4090�����ٶ���RTX 4070��2.32���� |
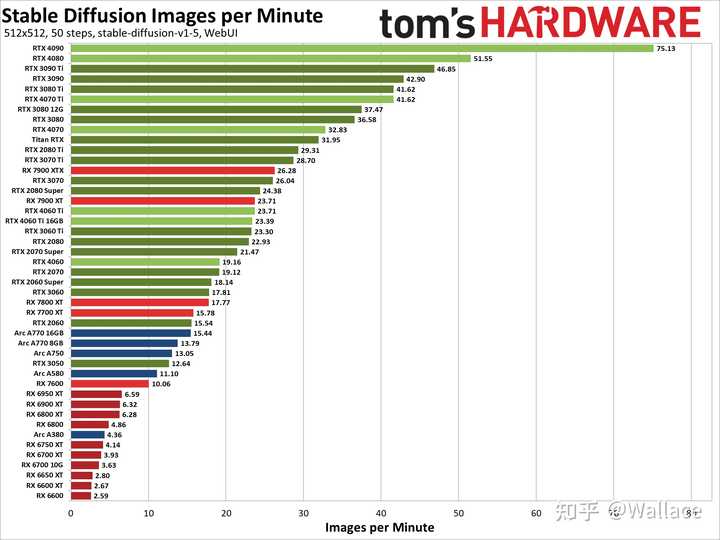
|
|
|
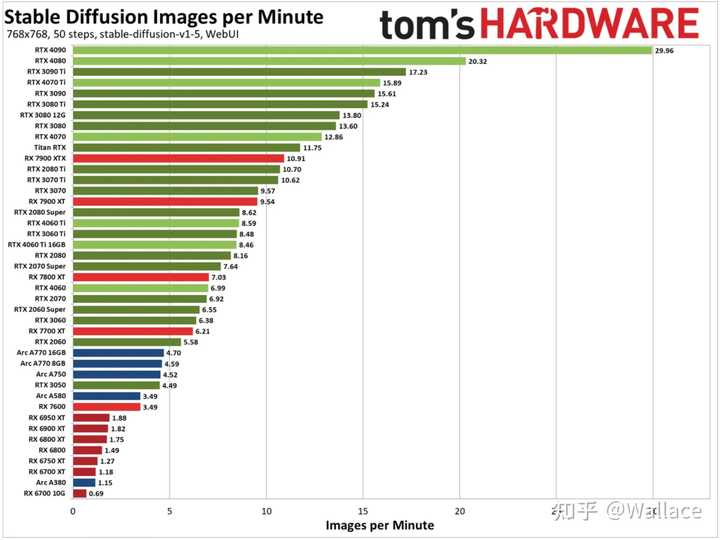
|
|
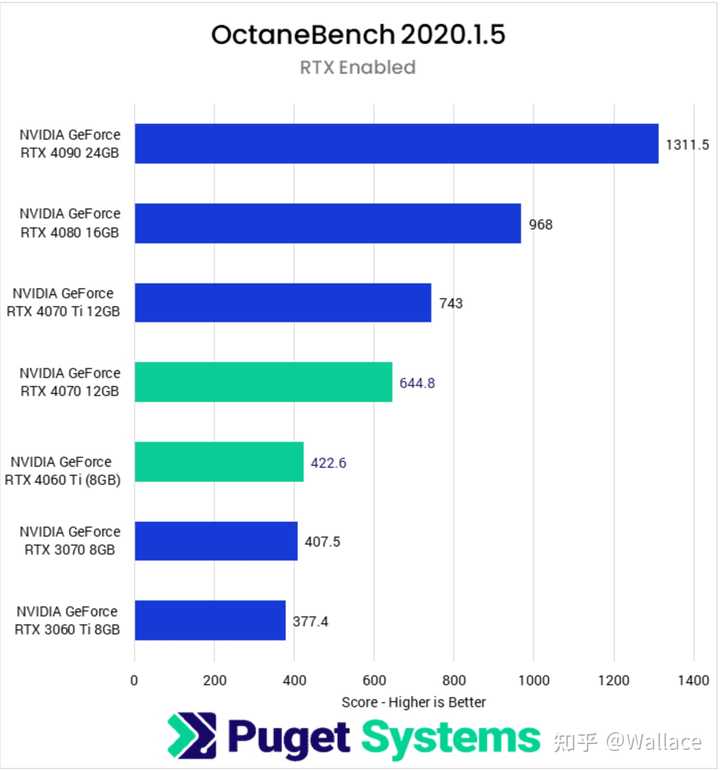
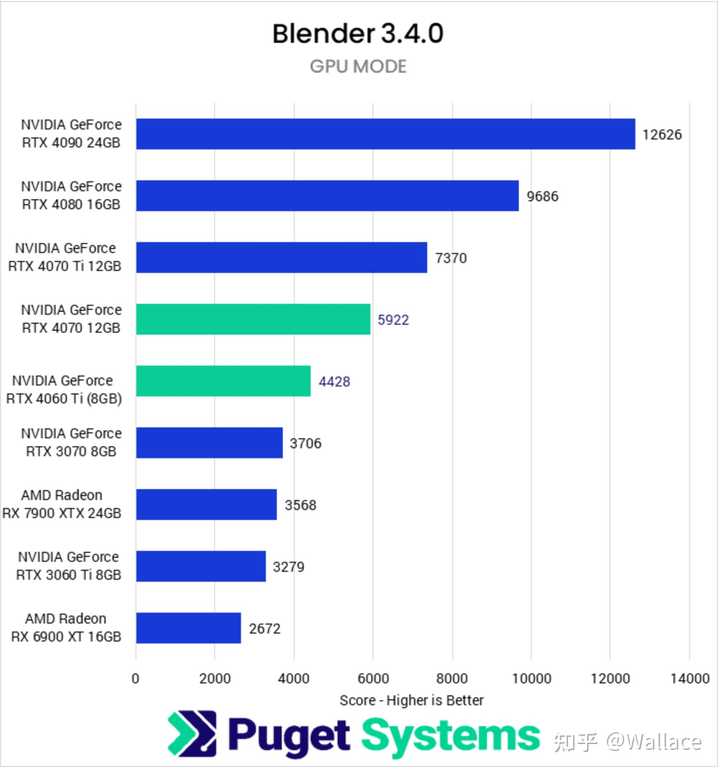
����Ⱦ���棬RTX 4090���ܱ���Ҳ������RTX 4070��2�����ҡ�����Puget�IJ��ԣ���V-ray�У�RTX 4090�����ٶ���RTX 4070��2.27������Octane�У�RTX 4090�����ٶ���RTX 4070��2.03������Blender�У�RTX 4090�����ٶ���RTX 4070��2.12���� |
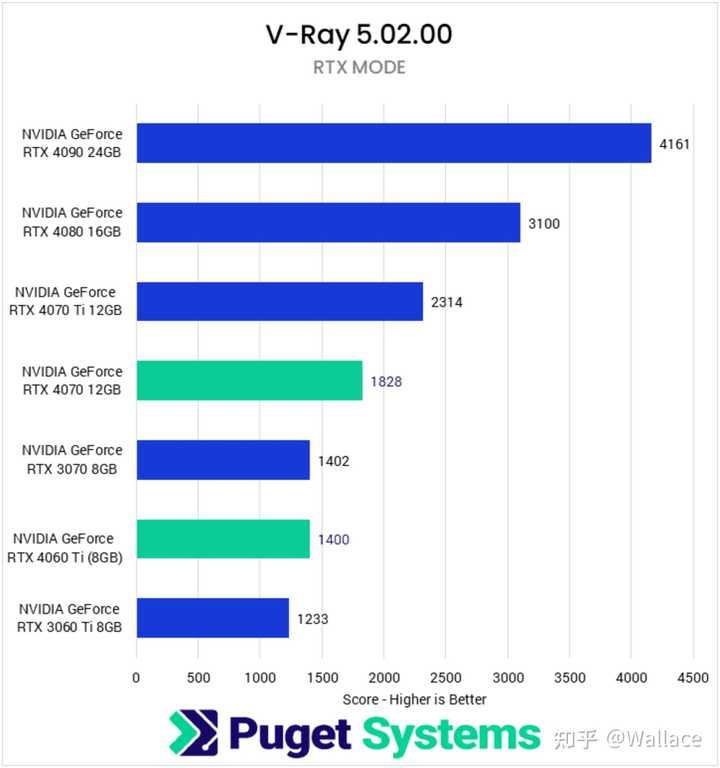
|
|
|
|
|
|
|
|
��ˣ���������Ϸ�������������߶��Կ������ܶ����ܴ�������Լ�� |
|
��һ��������� @���Ͻ�ʺ��� ��˵���Ǵ��������� ����Ҿ������Ƴ̹��յľ��ޣ�������һ����Ȼ�ܡ��ȡ��� |
|
|
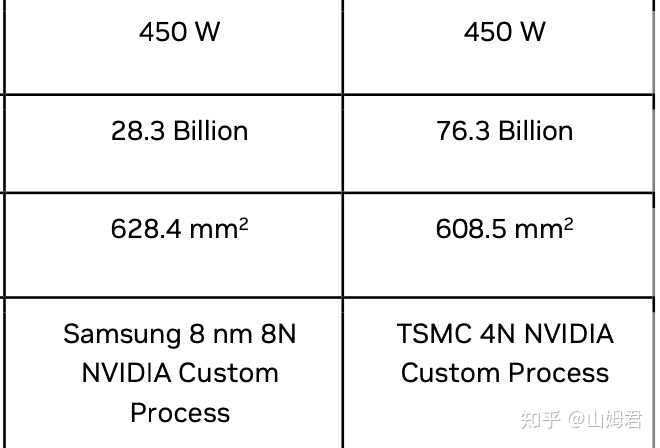
���ǿ�������NVIDIA�ṩ�����ݣ�4090����һ��3090TI�ĺ������С��3%������£�ȴ��������1.69���ľ���ܣ�TSMC 4NҲ����������ľ���ܴ����ķ������⡣ 4070���ھ���������٣�ɢ�ȵ�������Բ����أ����Դ������ɵ�ɢ��������ҲҪ˫�������ˣ�����������оƬ������ӣ�ɢ�����Ľ�������������оƬ��ģһ���ɱ���������Ϊ���õ��ԵĻ������������ġ����Կ��Կ������ڵ�4090����3.5���ˣ�ȴֻ���ṩ450W�Ľ�������������Ҳ�����ˣ����һ���Ҫ�����ѹ�Ÿ˷�ֹ���Ρ� ɢ�ȵ�����Ҳ��Ӱ�����ṩ��4090��ʵ��������ģ��������CUDA�㣬4090��4070��2.78������ô��Ӧ�Ĺ������ٳ����ȲŶԣ�Ҳ����4090Ҫ�ﵽ556W��Լ600W����������Ĭ��ֻ��450W����Ȼ��4090��û�б���ι����, 4070�DZ����ӵ�����¸ɻ4090�Ƕ����ӵ�����¸ɻ������ȻҲ�����ۿۡ���Ȼ�ܶ�OC���Կ��ṩ��600W�Ĺ���ǽ�����Ǻ����Գ�����450W֮��Ƶ�ʾͺ��ѳ���ȥ��ʵ������������ʼ�ʵݼ�������Ҫ����Ϊ���ڵľ���ܶ��Ƕ��Ķѵ���ƣ���ͬһ��3D������У�������̯���һ��ƽ�̵ģ���ʹ�н���600W��ɢ��������Ҳ�����Ǵ��߱���һ�����������Ȼ�кܶ���������Щ������ڲ���¥���϶�У�û�취��ʱѸ���ͷų������Ӷ�Ӱ�����Ƚ���Ч�ʡ� |
|
��ЧӦ�������Ǹ��۸�����ȵġ� ��������Honda Civic-R���ܾͿ���1-2�룬���ǹ���15-20���������ࡣ �����˵ƿ���� ƿ������ATX�ijߴ����ƣ��Լ������ߵ�Ǯ���� �����1000����ԪһƬҲ�кܶ�ܶ����������������Կ�����һ��2��һ���ľ������������ٶȻ��ܶ�ܶ�ܶࡣ |
|
��CUDA����դ��������TC��RT��Ԫ������4090��4070��2.78������Ȼ����˵�ӽ�3��Ҳûɶë�����������п����4070��4090�IJ�࣬������������Ҫǿ���£����߲����2.78���� �������������������������Լ�TDP�����ϣ�4090ֻ��4070��2.06~2.25�����������һ��Ӱ�������ܷ��ӵĹؼ����ء� ����������Դ棬4090������4070��2��������Ϸ�����Ӱ����������һ����ϸ˵˵�� ����ƿ�����������ϸ��������ۺ�Ӱ��������ı�ЧӦ�� |
|
|
���������Ա� �������ǿ������������棬����һЩ���ܷ֣�4090������4070��2.1~2.3������Щ�ܷ��Ҹ�����Ϊ�������Դ�Ӱ�첻��������TDP���Ƶ��µģ��ټ�������ıʵݼ�Ч�ʣ��������������ˣ���Ȼ��2��Ҫ�ߵ㣬�����2.3������֮������ߵ�2.78�����е��࣬������Ҳ���ܽ��ܡ��Ͼ��Դ��С��ʱ���������������Ӳ���ż�����������������û�Ӧ�ò������������⡣ |
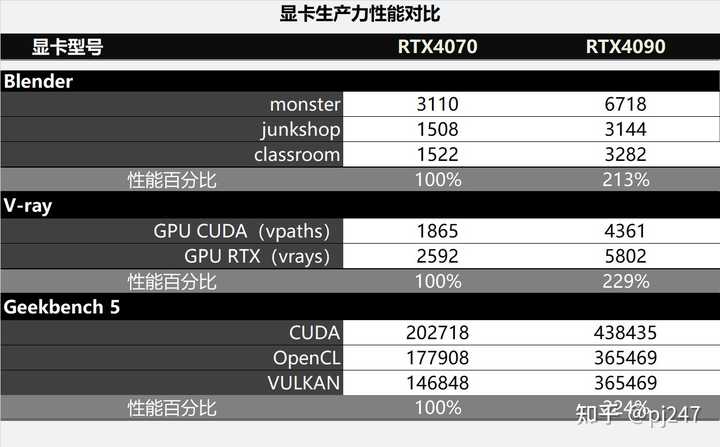
|
|
��Ϸ���ܶԱ� �����ܷ� ��Ϸ���������������۵�3dmark�ܷ֣�����ƽ��ֵ�����4090��4070��2.2����������������������ࡣ |
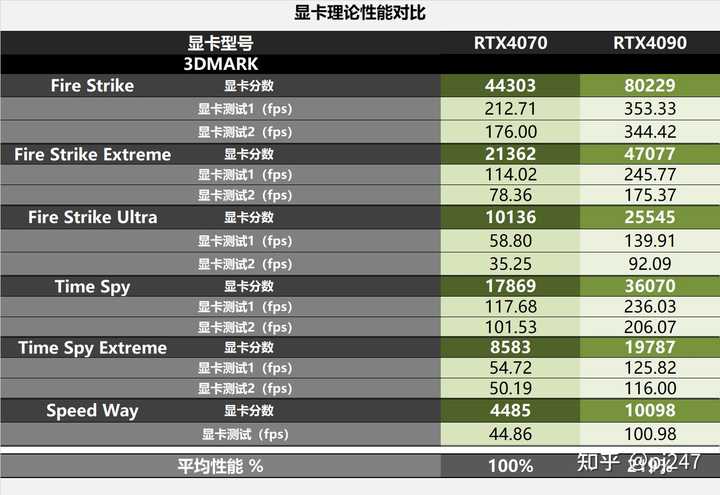
|
|
ʵ����ϷΪ���Ͻ��������Ե�����Ϸ���Դ���benchmark���ֱ��ʷֱ���4k��2k����ᷢ�ֱַ��ʵ�Ӱ���Ƿdz���ġ� ��դ��Ϸ ��4k�ֱ��ʣ�4090��4070��2��������2k�ֱ��ʣ�4090ֻ��4070��1.5�����������Ƿdz����ԡ� |
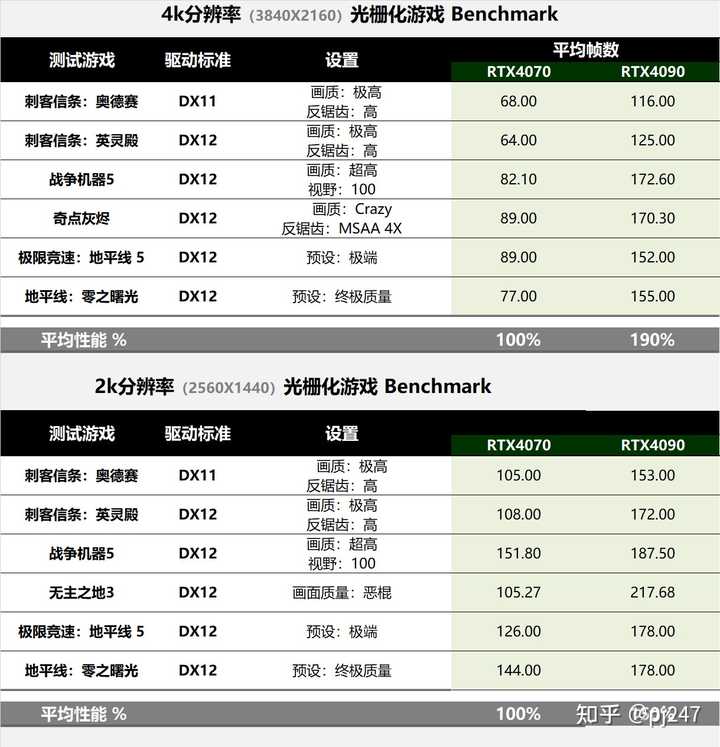
|
|
����Ϸ 4k�ֱ����£���ȹ�դ��Ϸ�����߲����������ˣ��ﵽ��2.3�����ң�2k�ֱ����£���������Ч�����߲���С��1.7������������Ч�����߲�����2�����ҡ� |
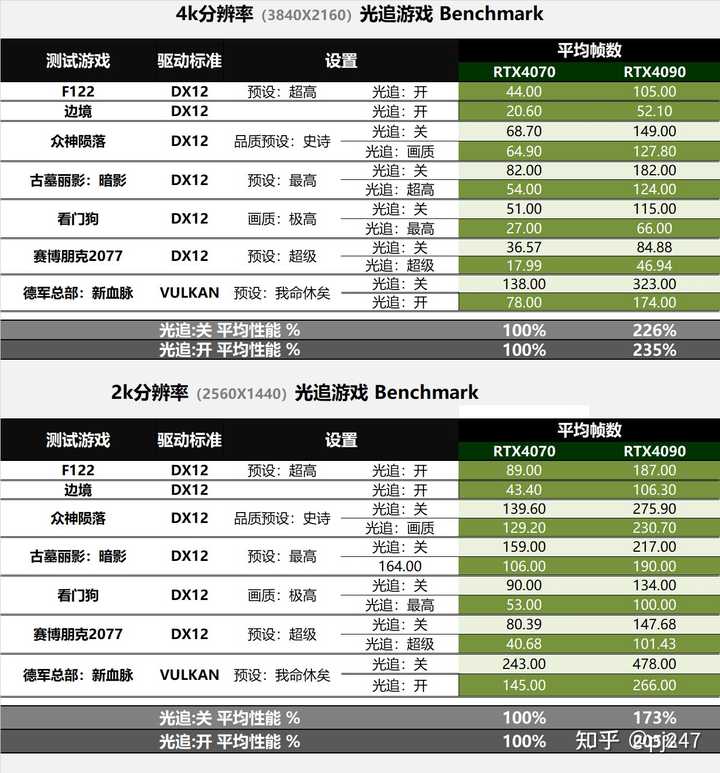
|
|
DLSS ��DLSS��4k�ֱ����»���2�����ҵIJ�ࣻ����2k�ֱ��ʾ���1.2���IJ�࣡ |
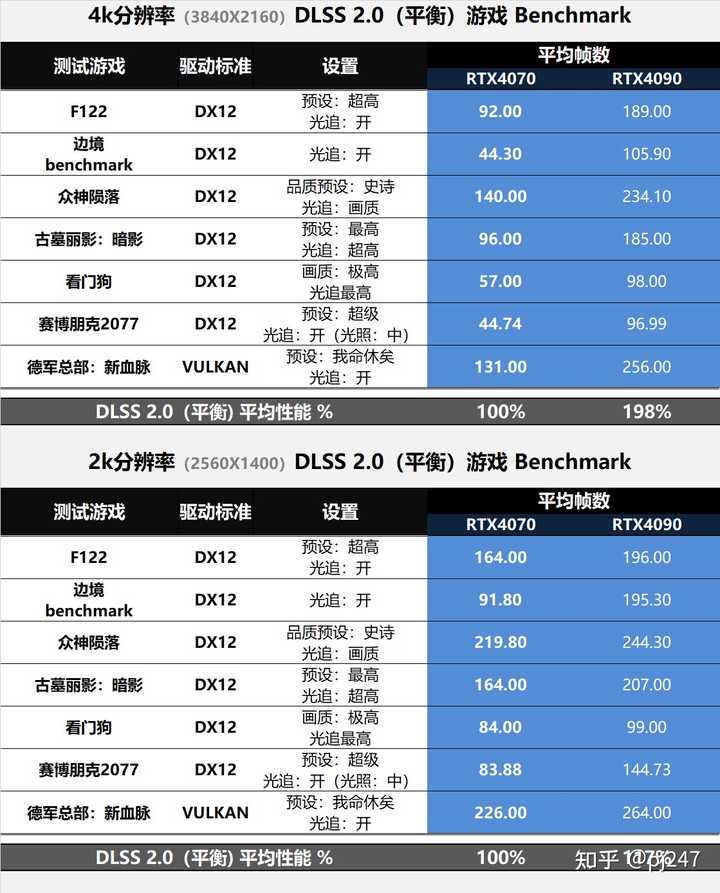
|
|
Ϊɶ�ֱ��ʵ�Ӱ�����ô�����ǿ��Կ�����ͬ�ֱ�����GPU�ĸ����������8k�ֱ��ʣ�DSR���£�4090�ĸ��ز��ܴﵽ100%��4kҲ������ȫ���ӳ�����ȫ�����ܣ����4k��dlss�ڣ����ػ����½��ࣩܶ��2k���ǻ���ٷdz��࣬�൱���Է�2~3���书�� ���Լ�ʹ����4k�ֱ����£�4090Ҳ��Ҫ�ܺ�cpu���ڴ�ƽ̨�Ż��бȽϺõķ��ӡ� |

|
|
��Ȼ8k�ֱ����£�4090������ȫ�������ܣ���ô��8k�ֱ����£�4090��4070�IJ�����ɶ�仯�أ��ܿ�ϧ��û����4070��8k�ֱ��ʲ��ԣ���������4090��4080��8k�ֱ��ʶԱȲ��ԣ����Թ��ο�һ�¡� |
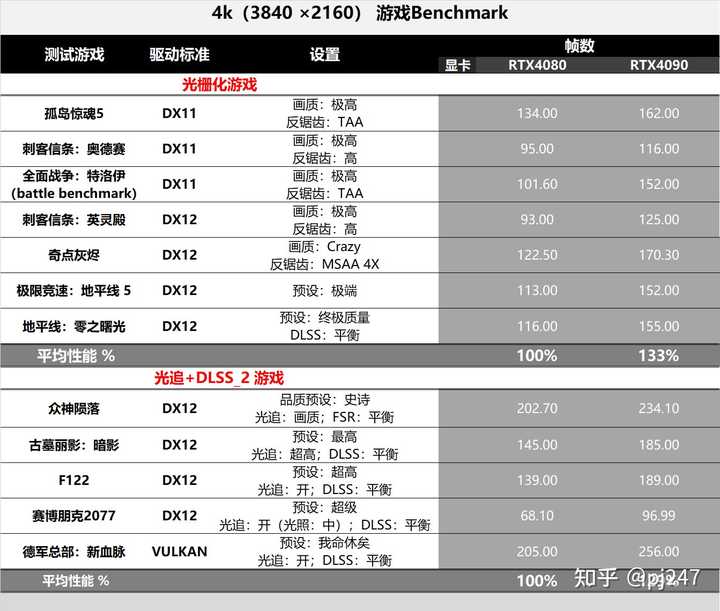
|
|
���Կ����ڹ�դ��Ϸ�У�8k�ֱ���4090���4070�����ȷ��ȶԱ�4k����������5%�������ر����ԣ����ڴ�DLSS�Ĺ���Ϸ�У�8k�ֱ���4090���4070�����ȷ��ȶԱ�4k����������17%����ͷdz������ˡ� |
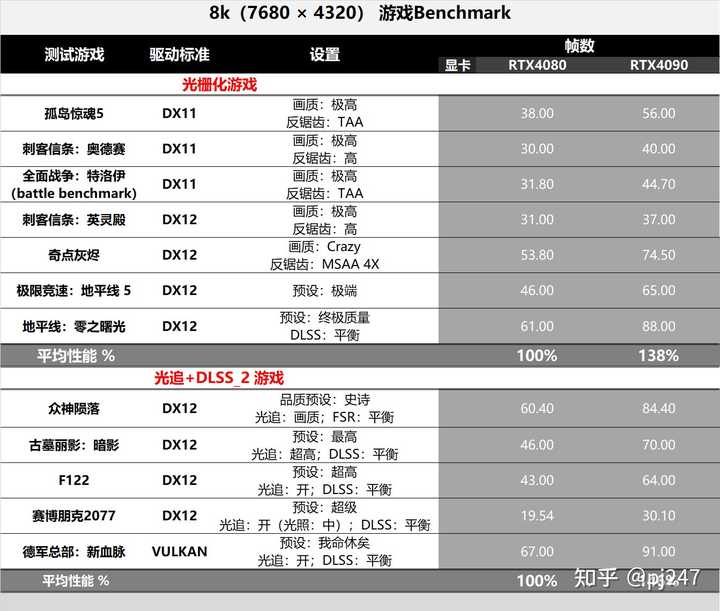
|
|
Ҫ֪��4080�ô���256bit�Ĵ�������4070ֻ��192bit�����������8k�϶Աȣ�4070�IJ������ ����˵���������Ϸ�Աȣ��������Կ�û�о��Թ�ƽ��������4k�ֱ����£�4090����ȫ���ӣ�2k�����Է��书����6k��8k�ֱ��ʲ��ܰ���ƽ̨��ƿ����CPU���ڴ棩��������4070��˵������˵6k��8k����ʵ4k�ֱ��ʶ��е���ǿ���ˣ����ʺ������ӵĻ�����2k�� ��������ѡ���Կ��������ϷӦ��Ϊ����һ��Ҫ���ȿ��Ƿֱ��ʵ����أ�����ͺܿ��ܶԩ��Ǯ�����߲��������Լ������� ���� ��������˵��һ�£���������8K��ʾ����ʹ��N�������е�DSR����̬�����ֱ��ʣ�����ģ��8k�ֱ��ʵ�Ӧ�û�����4k������4���պ�Ϊ8k���� �е���Ϸ��cpu���еij�gpu�����еij��ڴ棬��ͬ��Ϸ�����ͬ������һ�Ŷ��ۣ�������Ľ����Dz����˶����Ϸ��ƽ��ֵ�õ��������ο��� ��Ȼ�������в������ݶ������Լ����ġ� |
|
�����ȿ�4090��ģ�Dz��ǽӽ�4070��������Ȼ�������ۺ�������ݡ� |
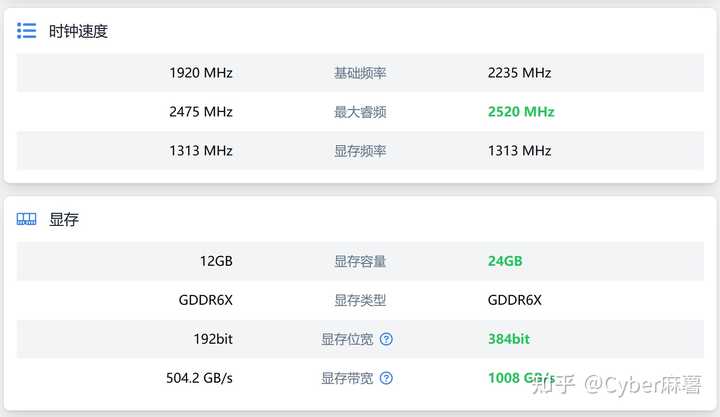
|
|
Ƶ�ʷ�����Ҫ�ǻ���Ƶ�ʲ�Ķ�㣬����Ӱ�첻�����Ǽ������Դ棬�Դ���4090��4070��������λ������������������ |
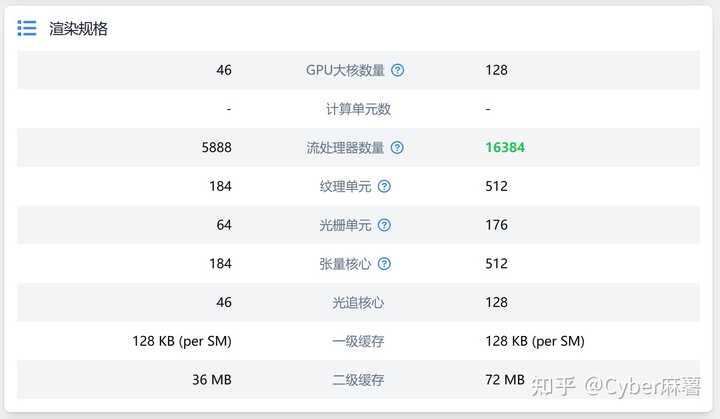
|
|
��Ⱦ��֣������ӽ�������16384/5888=278%��128/46=278%������ |
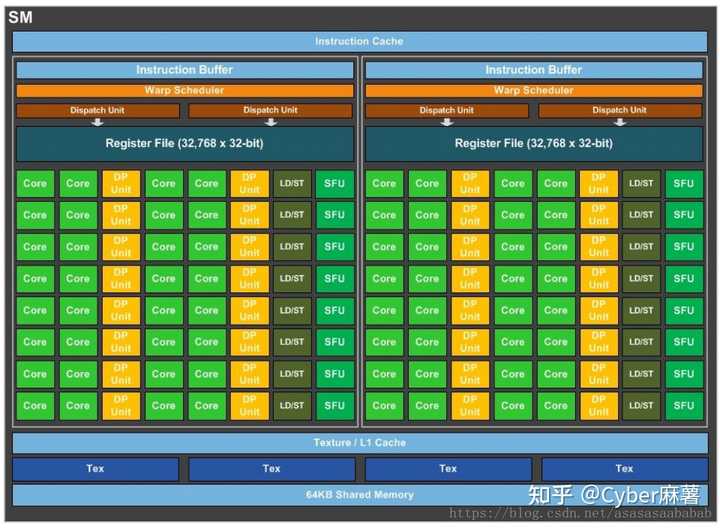
|
|
SM��������SP���ģ�CUDA core��Tensor Cores��RT Core��+������һЩ��Դ����ɣ�ͬһ���Կ��ĺ�����ɻ����ǹ̶��ġ� ���Ƕ������沿��4090��4070�Ķ����� �����Ҹ�����Ϊ��4090�Ĺ�ģȷʵ�ӽ�4070�������� ����������Ļ������ٽ�һ�����ۣ�4090��4070�����ܱ��ֵIJ���ж�� |

|
|
��FP32��������Ϊ���Ļ���4090��4070��283%�����Ϲ�ģ���������������� ���Ե�Ӣΰ�ﶨ�������������۵ļƻ����Կ��Ĺ�ģ���ܹ����Դ�ȵ�Ϊ������Ϸ���ֵ�˼·�ͱ�����趨һ��������Ȼ��������ڵ�SM��Ԫƴ��һ�����ȶ��ﵽ��������������þͿ����ˡ� �����ٿ�������һ���4080 16G���ͱ���Ӧ����4070Ti��4080 12G�� ������4080 12GΪ����4080�Ĺ�ģΪ130%��4090Ϊ213%�������ֳ��������ܲ��죨FP32�������ܣ���120%��205%�� ������ģҲ�����ȡ� ���������Ǹ��߿Ƽ�����������ģ�ֻ��һ����ָ�ꡣ ������ĵ�����Ϸ�����ϣ�����ת��Ϊ֡�ʡ� �ܶ�������Ӵ�����SM��Ԫ���ܹ�����ȥ�����ˣ����ǻ�һ������ĽǶȣ�4070��TDP200W��4090��450W���� �Եģ�����������ͷ�����滹��������Ϊ���������������߹��ɢ�ȵĹ��ġ� ���Dzο���һ��3090��3070����Ȼ�Դ����3��������λ��150%����ģ�ӽ������������Կ��Ĺ��IJ����50%��ͷ�������ֳ��������ܲ�����£� |

|
|
�����Ҹ��˸���������Ϊ��Ӣΰ���ڿ���4090֮���ͷ����ˣ�������Ϊ�������Կ����ܷ��ӵ�������⣬��˵��콢�������Ժ����ĸ�����Կ�ֻ��һ��һ����˸�����Ҳ������û��4090Ti��ԭ�� ���������Ѿ������������ˣ����Ծ��ܱ�3090Ti����38��SM��Ԫ�����ǹ���Ҳ��һ�£��м�Ҳ���Ƴ̹���������Ӱ�죩���ø����Ĵ�ɸ��ߵ���������˵õ�����һ�������ԡ�����4090�¶ȵ͡� |
|
�ܼ���Ϊ�������ơ� 4070�����ع��ľ��Ѿ��ﵽ300W�ˣ�4090��3����Ӳ���������£����������Ż�Ч��100%��Ӳ������û��˥����300*3=900W�Ĺ���Ҳ̫�ֲ��ˣ������Դ�����ܸ㶨��1000W�ķ������ѵ��������ڸ��˵���������ѹ���������Կ϶�������Ϊ�������TDP�����������3������Ӳ������3���ĺĵ磬�����Ǻų�һ���ݻ�һ����ĸս��Ⱥ��GTX690˫о�Կ���TDPҲ��������300W�� |

|
|
|
|
RTX4090��cuda��������RTX4070��������������ֻ��2���� |

|
|
���ǣ� ����ͨ�����Ȳ�����cuda���ĵ�Ƶ��ÿ����ȥ�� Ƶ���ҿ��ˣ���Ҳ�࣬�Ǽ��п����Ǵ��������桢�����Դ�Ķ�д�ٶȣ��ۺ������γɵ�ƿ���ɣ���רҵ������� ���Ҿ��ð����콢�Կ��Ķ��ۣ�������˼�� |
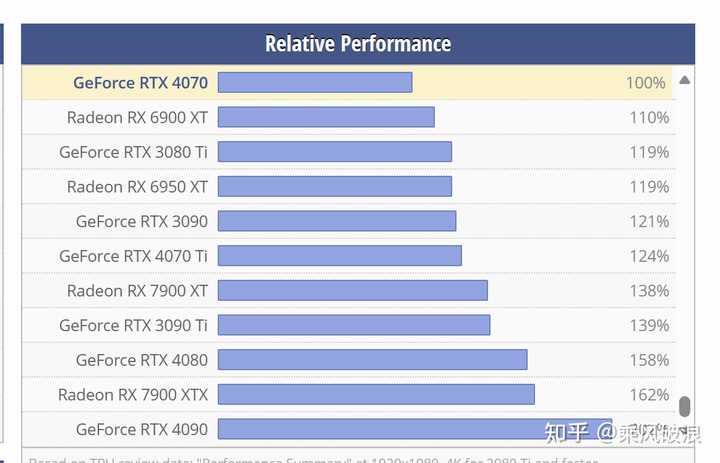
|
|
��Ӧ������һ����ҵģ�ͣ�����Ķ��������Խ������ ���������콢���ŵģ�����ʮ֮�˾�Ҫ�й���֮�£����ޣ��и��²�֮�£�����ij�콢�ᱡ����ij�콢�ֻ���ij�콢����������ij�콢���õĻ������ȵȡ� �����ں�Ǯ�ģ�ʮ֮�˾ţ����ǾͲ�������Ŀ��ͻ��� |

|
|
RTX4090���ִ��Դ棬����Tensor Cores����ۣ����������õ��Կ������õģ��Դ���ƿ�������£������Ѷ�Ϊ֮�ģ������ٲ����˰ɡ� ������ʱ���Դ��һ�㣬�����������㣬������ģ�͵ģ�Ӧ�ö�֪���� ���dz�����Ϸ�ģ���RTX4090���Ǿ��Ǹ��ϻƶ��͵�Ǯ�����ο����ڵ�����汾RTX4090�����ۣ��д����Ҳ�Ƿ����ۡ� ������²˺ܶ࣬���������꣬�������ţ� |

|
|
PS��2024���Ʒ����������7000K |

|
|
��� PELADN �ۼ� RTX4080 16GB GDDR6X DLSS3 �羺��Ϸ��� ���� ��8689.00 ȥ����? �����һ����������˵��ۼ��Կ����۸� |

|
|
��� ����(Lenovo)��������7000K 2023��Ϸ��������(13��i5- ���� ��6968.00 ȥ����? |
|
�ϻƣ�С���ӣ���Ҫһ��һ�ڳԣ�����Ҫһ��һ�㼷�� ��Ҫ����һ������������GDDR7���Դ��512���Դ�λ��������������һ����ʲô�����ࣿ |
|
���Ѱɣ�û��4090���ˣ�ֻ��4090D D for dog |
|
ƿ�����ںܶ���ۺ�Ӱ��������ı�ЧӦ�� |
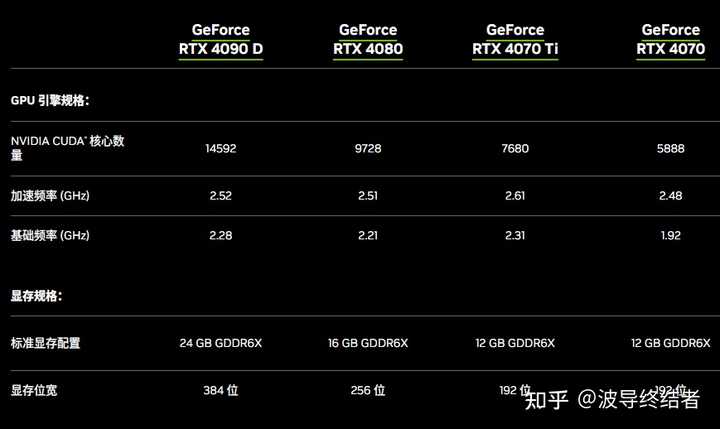
|
|
|

|
|
���ڵĺ���ԭ����ǹ������ơ����ǿ����ȿ����Կ��ܹ��ģ�������NVIDIA�ٷ���Ƶ�Ϊ��4090��425W��4070��200W��ȷʵ��2��������һ���Կ������ܶಿ�ֵĹ��ܣ�����Ӳ������룬����DLSS��һ�㲻��ͬʱȫ�����������Կ�������Ϸ���ģ�4090��302W��4070��186�ߡ����㿴��Ƶ��ļ����ʣ�Ŀǰ�����ձ��������4090��600W��4070��400W��ͷ�� Ҳ����˵���ڹ��������棬������ܹ��ģ�4090����4070��2����ͷ�����ֻ���ٷ���Ƶij�����Ϸ���ģ�ֻ��1.6�����ң��������ģ�Ҳֻ��1.5�����ҡ���������Ҳֻ��2�����ң����������⡣���Ե�ɢ�Ⱥ��¶����أ����Թ���������4090��������4070��2����ͷ�� |

|
|
���ڽ�����CPU���Կ�����Խ��Խ�ߣ�TDP֮����������������Ұ��TDP��ΪThermal Design Power��ԭ����CPU�����̵�ɢ����ƹ���ָ�꣬����Ҳ���굽�Կ��ϡ���ǰûʲô�˹�עTDP����Ϊ��ʱ��CPU���Կ����ȶ������һ��ǵ��ҵ�����һ��NVIDIA GeForce2 MX 200��ɢ�ȷ��Ⱦ��������죬�����ֱ�ӻ��˲�ת������һ�����ã�Ҫ�����ڵ��Կ�����յ��ˡ� ���ڹ���Խ��Խ�ߣ�������CPU���Կ������Ĺ��ģ�ͬʱ��������Ĺ���ǽ�����ǵ���ǽ�Ȳ�������Ϊ�˽��������Ҫ�˽Ⲣ�����IJ���������ͻ�ײǽ��Ƶ����������ȫ����Ӳ�����ܡ�2���Ĺ���ǽ��2�������ܣ��������� |
|
|
|
|
|
���Լ������õ��Կ�����4070��Ĭ��״̬��ƽ��������������Ҳ����200W��֮ǰ����Ҳ������ģ�ƽʱ�ܵ�AIӦ�û�����Ϸ�����ľ��������ˡ�4090��ͬ���ģ����㲻�Ѹ���˥���ͱ�ЧӦ���ȥ��2���Ĺ��ľ�2�������ܣ��Ѿ��ܲ����ˡ� ��������Ҫ��һ�㣬4090�Ĺ��Ҳ����4070��3���������CUDA���ĵĻ���4090��14592����4070��5888������һ����2.47�����Դ�λ����������С���棬4090��4070��2���������ٿ��������4090����Ҳû���ķ�����4070��3���� ���Դ𰸺������ˣ�4090û���ĸ������4070��3��������2����CUDA����Ҳ����2.5����������2������Ҳ�ͺ������ˡ� |
|
��dz�˵�����⣬�ڹ����Կ���ʱ����ֻ������ν��cuda��Ԫ��������Ϊ�����ܵķ�����һ�������ۺϽ�� ��Ҳ˵���ϻƵĵ����İ������Ķ�������ȣ�����һ���ܳ�����ȻӲ���ܺã����Dz������ͻ��߹�����ٵ�λʱ�乩��������������������ô��Ȼ�Dz��ܳ�ַ����ܳ����ٶ����ơ� �����Կ���ֱ�۵����ڱ����� �Դ��λ��������GPU���ܵķ��ӣ���ˮ����ˮ�ߣ���õ�״̬����ˮ��һֱ��ͣ��������ת �������������У�����GPU����Ⱦ��ˮ�ߣ�����Ҫ�������ݡ���Щ������������CPU������ݸ��Դ棬GPU�ٴ��Դ��ȡ����Ҫ�����ݣ��������漰���������������OPENGL �Դ�Ĵ�С�������Ƶ�1������Դ��������С�ͻᵼ��GPU��ˮ��ͣ�����ϣ���ؽ����������½��� �ϻ��Ǻ������Щ�ģ�������Żῴ�����ϻƵĸ��ֵ��������統���˵������4070��оƬ����4060�ϵ��������Ϊ����ȫ����ͨ�������Դ��С���Դ��������Լ�����ܷ��� |
|
ʵ����Ҳ���������� 3 ���������Ƕ�ά�ȵģ���ֻ����һ��ά�ȣ�����ֻ�� cuda �Dz�� 3 ���� �������Դ�Ĵ�����λ������ֻ�� 2 ������Ҫ���� pcie x16 �ӿڣ�ͬ��pcie �汾�£�4070 �� 4090��pcie������һ���ģ����ﲻ�̫�ֻ࣬�����ģ���Ϊ����λ�ö����ܳ�Ϊ����ƿ���� |
|
|
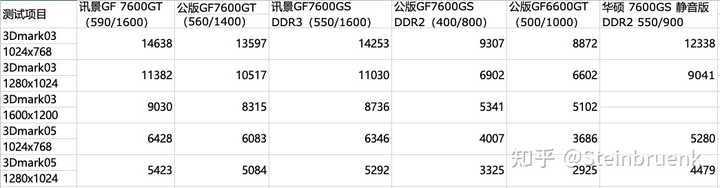
��Ϊ���ں����ҵ�ͬ�Ⱥ��ģ���ͬ�Դ���Կ����Ұ��ռ��䣬ȥ���� ddr2 �� ddr3 �� 7600gs�ĹŶ����Է��������ܿ������Դ�Ĵ����Ѿ������� 7600gs �ĺ������ܣ��ر��ǵ� GPU ����������ǿ��ʱ�����׳��֡�ι������������� ���� xfx �� 76GS d3 vs ASUS �� 76GS d2���ܿ��� d2 �Ѿ����� 76GS �ĺ��������ˡ� ����Ҳ�п�һ����ǰ���Կ���76gt �� gs ʵ���ϲ���û�Ǵ��Ļ���d3 �� 76gs �ǵ�ʱ�ܳ�ֵ��һ� |
|
|
������Ƿdz��Ͻ������ܿ����Դ�����������ܵ�Ӱ�죬������Դ���£���ֻժȡ��������Թ��Աȵ����ݣ�������ž��С� ������Դ1�����ʵ�����ж�ɱ��:7600GS DDR3����_����_̫ƽ�������PConline ������Դ2�������Լ۱� 33��7600GS�Կ�ɳ������_Ӳ��_�Ƽ�ʱ��_������ (sina.com.cn) Ȼ��pci �������֣�gpd x1 �� oculink vs usb4���������������ֱ��� oculink 4.0x4��oculink 3.0x4 �� usb4 3.0 x 4���ܿ��� usb4 �����ܱ� oculink �������ԣ�������� pcie ������Ӱ�죬��Ϊ oculink ������ȫ ��pcie��û�� USB4 �� tb3 �ȵ� dp�ȵ����߰���ģ�Ҳ����ҪоƬ��һ�� pcie x4 �Ϳ���ת��������Ŀǰ eGPU ����ʵķ������ܿ������ߵ� pcie ������������ 10%�� |
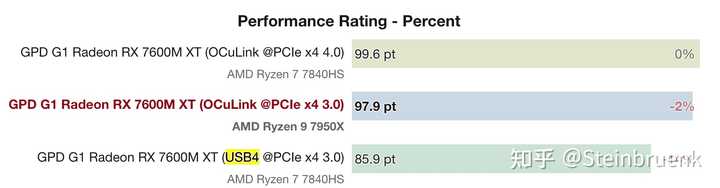
|
|
�����İѴ����������� 3 ��������Ӧ�û�ӽ� 3 ��������ô�����ܼ۸�Ͳ��� 3 �� 4070 �ˡ� �����ף�������̸�ĵ��Ե�ľͰЧӦ��A Ͱ�� B Ͱ��A Ͱ���ľ���� B Ͱ 3 ����������װ�µ�ˮ�IJ�����ľ����ģ���Ϊ���������ܵ����������Լ���ܿ�����Ϊһ����������ܾͲ���ƿ���� |
|
һҹ֮�䣬4090�Կ��ļ۸��쭵�������զ��ĵز��� 10��18�գ������ѷ����ڶ�����������У�Ӣΰ��RTX 4090ϵ���Կ����¼ܣ�����콢�����۵�4090��ز�Ʒ����ȱ��״̬����4090�Կ�ȫ���¼ܡ�Ѹ�ٵ������罻ƽ̨�����ѡ� 10��19�գ�������վ�ϵĵ������̼ҷ۳���RTX 4090��棬���۴����2��Ԫ��3��Ԫ�����赭д�شﵽԭ�۷�����ˮ���������ߣ��Ѿ���4090�Կ������˽ӽ�5��Ԫ�� |
|
|
����Ǽ۵�4090��ͼԴ����ƽ̨ ����������������ݵ�һ�������ľ��������Ѷ�����������Ի�����4090�Կ����� ����Ϣһ��������Ϸ��ҵ����Ƽ���ҵ��ʱһƬ��Ȼ����Ϊ�������Ѽ���Ʒ������̫��������˼��������ʮ�־��û�Ⱥ�鼤��֮�ʣ���������������̼ҵ���������ۣ��Կ�������ҲĦȭ�����ٴ������� һʱ�䣬����Ƿ��Ľ�ͼ�Ĵ�Ʈɢ�����ɲ���ĵ��̿ͷ���ü��ʾ��������Ӫ���һ�֡�4090�ٲ�����������ˡ��Ļ��ȷ�Χ�� ��ô����������Կ��г����Ƶġ�������Ƿ���ʵ��������ʱ12999Ԫ��ͨ�м۸�����ֱ��5���ȱ����ۣ�RTX 4090ϵ���Կ�����������ʲô�� |

|
|
���ȵ������Կ� ȱ�����Ǽۣ�����4090�Կ����̼��ƺ�ӭ����ʷ����Ӳ����һ�졣 ������������ƽ̨�ձ�ȱ�������ڻ�ǿ���������̼���Ҳ������4090���������ϻ��������ȳ�����˯һ�������Ǽ�ǧ�������£�4090�ļ۸���ϵ�����ǰ��δ�еû��ң��ڶ�����������֡� �г��ı仯����������������֮���Ա����ȣ����ǻ��������۷��͵Ľ���� ��10��18�������𣬹���4090�����������ڹ��Ƶ���Ϣ����������Vת���������ձ齫֮���Ϊ��4090�Կ���������������ǣ�10��17�����������������µ��˹�����оƬ���ڹ��ƹ涨��������AIоƬ���ڽ��ܵ���һ�����ơ� Ӣΰ�﹫˾������֤ȯ����ίԱ���ύ���ļ���ʾ�������ɵ�·����ijЩ������ֵʱ���¹�Գ��������˶��������Ҫ����Ӣΰ�����еIJ�Ʒ�������ܶ���ע��������г��е������Կ�RTX 4090��ȻҲ���������ܹ��Ƶķ����С� |

|
|
���ἰ��RTX 4090��ͼԴ���� ��Ϊ���Ѽ���Ʒ��������ߡ�������ǿ����Կ���RTX 4090ϵ��������2022��10�£�����760�ڸ�����ܡ�16384��CUDA���ĺ�24GB��������GDDR6X�Դ棬����4K�ֱ��ʵ���Ϸ�г����Գ���100 FPS���С� ��Ӣΰ��ٷ��Ļ���˵��RTX 4090�����ܡ�Ч�ʺ� AI ������ͼ������ʵ���ˡ��ʵķ�Ծ�������ڹ�����������Ϸ��������Ľ��죬�ܴ������������4090������ȫ����ҵ������鿨�� ��ˣ��ܳ�һ��ʱ���4090�Կ������Ļ�����������ݵĽ�ɫ����ʵ���������Ϸ����������������컨�塪������������4090���ҵ������ |
|
|
1300���ش���������ʣ�ͼԴ֪�� �����֪��������һ����������Ѽ���Ʒ������ۡ��������������������˳��� �ڸ����罻ƽ̨�ϣ����ǴӲ�ͬ�ĽǶ�������һ�¼���Ӱ�����ԿƼ�Ȧ����ϷȦΪԭ��������䣬�����ڵ����������𡣡�4090��ʲô����Ϊ���Ѵʵ�ͬʱ��������Ϊʲô�Ʋ�4090������10��18���������ý������ѡ�⡣ �������Ѷ�����Խ��Խ���ŵ��Ʋ���Ϊ���ﲻ�������������������Ƶ��ص�Ƽ�����Ҳ������Ϊ�������ľٴ���ij�ֻֿŵı��֣����ν����¼��������Ϊ�ƶ����������ڶ�Ӧ�������ֱ��ͻ�Ƽ������Ƶ������� ��������ֵ����۲��еģ�����Ͷ���̼ҵĶڻ��糱�� ���š����ľ��桱���г������������ͣ������̡�������Ա�ͻ�ţ����ս�֣����ֱʶڻ����۸������ ֵ����ζ���ǣ��ɶڻ���������ɵ��ձ顰ȱ�������������ֱ����������������¼ܡ������ۡ��ȴ��ŵ�֤�����̶��������¼��Ľ�һ�������� ��������4090�Լ�����ٶ����۱�������Ŀǰ�Ľڹ����ϣ���ͨ��Ҽ������ò����ܼӼۺ�ԤԼ�ȶ���Ҫ���п���������鴦�ڷ���˼����ǿ�Կ��� |
|
|
|
����ģ�͵IJ��ӣ���Ϸ��������� 4090�¼����ͺ��10��19�����磬һ�Ž�ͼƵƵ��������������У����Ķ����š���ת�����֡� |

|
|
һ�š���ת����ͼ��ͼԴ���� ��ͼ�е��������Ը�ýHKPEC�����ʾ���������Ѷ���ع������߽��г��壬RTX 4090�Կ��������й������г����ۣ�Ҳ����˵�������Ȼ����4090���������ú�������оƬ�������ޣ��й���������������װ����4090�Կ��� �����������ҵ�Ͱ�ȫ�ֵ��ļ������������г��ܵ����⣬�����Ը�����оƬ��������Ҫ�����������Ӧ�á����Ծ���4090�Կ�������ˮƽ�Ѿ��ﵽ�����룬����������λ��������;��Ȼ����ȫ���� Ӣΰ�����Ҳ���ܳƣ�4090�Կ������Ѻ����ּ��ģ�����������������ר��ѵ��AI���ʹ�ǰΪ���ƿ��������ƴ���ġ��й��ع��桱A800��H800оƬ����һ���� ���������Ƶķ�Χ����Զ��Ԥ�ڣ�����4090��A800��H800оƬͬ��������������������ҹ涨�ڱ����¼����������ܶ�ָ�꣬���������뵼�幫˾��ͼ�ƿ������ƣ����й��ṩ��������ָ��ϵ͵�AIоƬ�����Ѷ�Ҳ��������ӡ� Ҳ����˵����ν4090�Կ����۵�˵��������ʵ�����Ľ�����ʵ�ϲ�δ�ܵ�Ӱ�죬�ʶ��ڶ��ݵĶڻ��ڹ�ȥ�����г��۸����ʻ���䵽�������䣬���ֻֿ���Ͷ��������ȡ����������AIоƬ�Ľ���ȷʵԽ��Խ���ˡ� һ���棬��û�еõ����ɵ�����£������������ĸ߶��Կ���װ�Ӵ����ޡ�����ת�ƵĹ���Ҳ�Ʊػ���һ���̶���Ӱ���Ʒ������δ�����ܵ����Կ��۸�IJ����� ��һ���棬�����¹淴ӳ������оƬ�Ʋò���Խ��Խ�ܼ���רҵ������Խ��Խ���ӣ��������������ܶȡ����ڷ�Χ�����ƣ�ȫ��λ����й��İ뵼���ҵ��AI��ҵ�� ����������ҵ�Ͱ�ȫ�ֵ��ļ��У�һ���µ������жϱ���������Ӹ����Ƕ�������AIоƬ���ڡ�4090֮���Գ�Ϊ��η粨�����ǣ�������Ϊ���������������Ҳ�����ױ��������� ֵ�ù�ע���ǣ�һͬ��������ν��ʵ���嵥���Ļ���Ħ���̡߳�����Ƽ��ȹ����Կ���˾�����ڹ���GPU����һ��ͷ�N�ڣ����������ڻ�Ϊ���£�����������������һ�嵥�� �˾٣��ٶȸ������Կ���˾�����з��ĵ�·�������ƣ���ͼ�����й���ҵ�ó�����4090��A100����оƬ�Ľ��̡� |

|
|
���Ƽ��ͼԴ��������ҵ�Ͱ�ȫ�ֹ��� �ɴ˿ɼ����������ӡ��IJ�������һ���Կ���һ��оƬ�����Ǿ�ȷ�����Щո¶ͷ�ǵ��й���˾������֮�ⲻ�ڡ�9���������й������뵼���AI��ҵ���� 10��18�գ��ҹ��������ŷ����˾����������Ի��뵼����ڹ������չ��������ʡ������˱�ʾ���з�ע�������ȥ��10��7�ճ�̨����ʱ��������ϣ���һ�����϶��˹��������оƬ���뵼�������豸�ĶԻ��������ƣ���������й�ʵ����������ڹ��ơ�ʵ���嵥�����������Ϸ������Ұ�ȫ������ó��ڹ��ƴ�ʩ��ʵʩ���߰����о����з��Դ�ǿ�Ҳ�����������ԡ� �������������ҵ���Ҳ����Ӣ�ض���Ӣΰ��������뵼����ҵ��������������������뵼����ҵЭ����ڵ�һ���������ԣ� �����ڹ㷺�ĵ��߿��ƿ��ܻ��������뵼����̬ϵͳ��������ٽ����Ұ�ȫ����Ϊ���ǻ��������ͻ�ת�������ط����� |
|
������ һ��AD104��һ��AD102 ���Ķ���һ�� ��ȴ���ù��ֻ�������죿 384bitλ����192bitλ����һ��������ô ��������Ϸ˵�£���Щ��Ϸ��GPU����Щ���ڴ���ʱ ������ɨ��Ȼ���� |
|
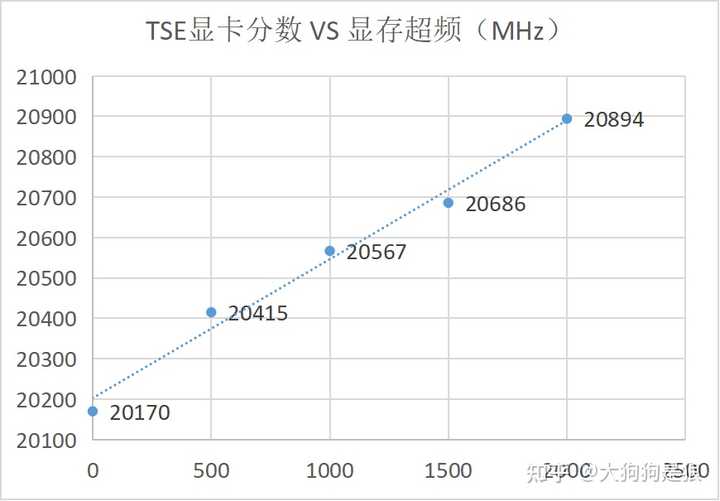
��������˵�Դ��������Ҫ���صĴ����������һ�����ص��Dz��Ǹ���ԭ���Դ泬Ƶ����һ�¾�֪���ˡ������Ĺ�ģ�ı�ЧӦ��Ҫ���ذ���Ҫ�����зֱ��ǣ������ܶȺ�ɢ�ȣ����������ʣ�����IC��Ƶ�ƿ����������ϸ˵���� ------------------------------------------------ ��������4090�Դ�Ƶ�ʿ�������+2000MHz��������TSE�ܷ����Դ泬Ƶ������������������Կ���+2000MHz�Դ�Ƶ�ʺ��ܷ������3.59%��4090�Դ�Ĭ��Ƶ��Ϊ10502MHz����Ƶ���Դ�Ƶ���������19.04%��Ҳ�����Դ�����������19.04%�����Կ����Դ���������������ܷ������������ܴ��Դ����������Լ�Կ����ܵ���Ҫԭ�� |
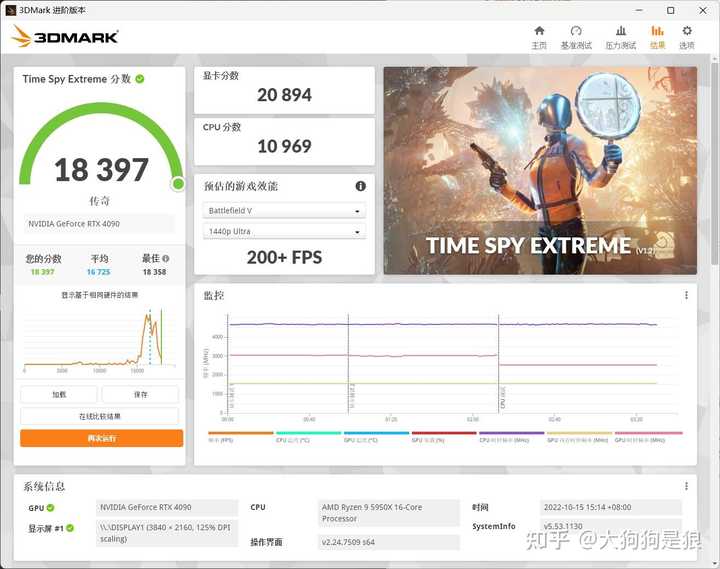
|
|
|
|
|
�Կ����Ĺ�ģ�����������ܷ������������������Դ������������Կ����Դ�����ı�ЧӦ�Ⱥ��Ĺ�ģ�����ԣ�������ǰ�Կ����ܵ���Ҫ��ʽ��Ȼ����ߺ��Ĺ�ģ�ͺ���Ƶ�ʡ� �������ش�һ��Ϊʲô���Ӻ��Ĺ�ģ������˵CUDA���������б�ЧӦ�� ��һ��ԭ���ǹ��ĺ�ɢ�ȵ����ơ����������������ĺͷ��Ȼ���ȫ�����ں��Ĺ�ģ������ʵ���ϲ����ܣ������Dz����Ƚ��Ƴ̹���֮���ĵķ����ܶȱ�����Ҳ����˵��ʹ���Ӻ���������Ҳ����������100%����ת���������ǡ�ɢ������-�����ܶȡ��ı�ЧӦ���������º���Ч�ܵı�ЧӦ��ʵ��������������3090�Կ������Դﵽ1000�ߵĹ��ģ�����ʵ��ʹ�ò����ܣ�һ��������400�ߣ�4090�Կ�����ֱ���������ĵ�ѹ�����㹦�ij�Ƶ���ޡ������Ҳ��ǹ����������ܣ����Ƿ�ֹ���Ƚ���ʹ�������� �ڶ���ԭ�������������ʵ����ơ�������GPU��ȫ������ͬʱ����ͬ�ļ�ָ������������ߵģ�Ȼ��ʵ��ʹ��ʱ�����ܴﵽ��������״̬������3dmark�����ܷ��������ڣ�GPU�ĺ���ͬʱҪ�������ֲ�ͬ��ָ�������Ⱦ����ɫ��ǰ�����ͺ�����ָ�����ĵ�ʱ�䲻ͬ�͵��¶����ˮ�߲�����ȫ���룬���к��IJ�����ͬʱ100%����ת��Ȼ����������м����㣬�������۸����������ܷ֣�����������ȫ��Ч�������к��ģ������������ӽ����Ĺ�ģ�����������������м������棬�������������ϵͳAPI������DX12��vulkan������Ϸ�Ż�������������ÿ�����������ʶ�����100%�����Ч���ݼ��������������ܺ�Ӳ����ģ֮��ı�ЧӦ�� ������ԭ��������IC��Ƶ�ƿ����оƬ��ģ��͵���оƬ�����оƬ�����ͺ�������ʱ��ͬ��������������Ƶ��Խ��Խ�ߵ�����£���ͬģ��֮��ʱ����λ�����������ɱ�Ȼ���µģ���͵��²�ͬģ���ͬ�����ѣ����Ҫ���Ĵ���Ӳ��������ͬ��У������������Щ����Ҫ��չ�첽���㼼��������GPU����CPU��GPU��Ȼ����ͬ�������ԣ���ʹ�����첽���㼼������ȻҪ���Ѵ���Ӳ������������ͬ������� ����������������ԭ����Ҫ�����������еģ���������һЩС���ر���оƬ�ܹ���ƺͰ�ͼ��ƣ����̹����˸��Դ�ͻ���ȵȡ� |
|
���û�����ľ� ����û���ϻƾ� Ҫ��ƿ�������� �����ϻƵ������� |
|
��ʵ�ɣ�����������µ�4090���Աȣ���ᷢ��70%���ĵ�4090������������4090��90%���ϵ����ܡ� |
|
|
|
|
|
|
|
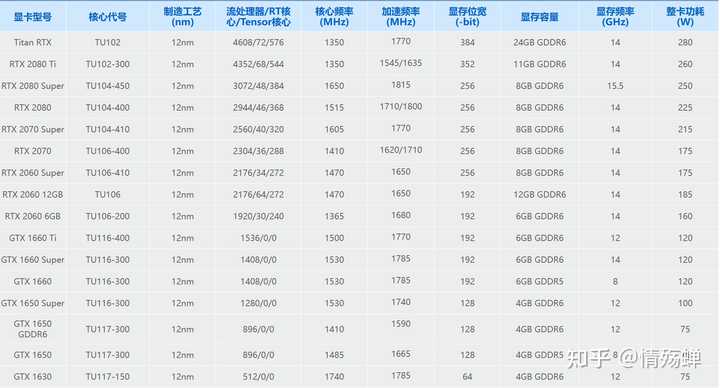
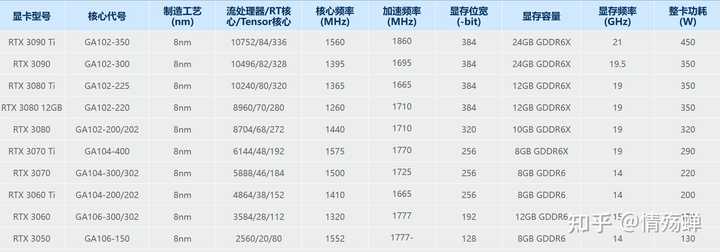
���40ϵ���Դ�λ����û�г����һ�졣 20ϵ�к�֮ǰ��10ϵ�У�����GTX9ϵ���dz�ƽ�ģ��߶�352/384���ж�192/256����Ʒ128������64. |
|
|
20ϵ�Կ����� 30ϵ�м�ֱ�����ģ����˼۸���Ʒ192�������Ͷ˶�128�ˡ�3080����ȫ��384��ˬ�IJ��С��������¸�����GDDR6�Դ棬�߶��콢������������ЧӦ�ܵ͡����AMD��ȫ��yes |
|
|
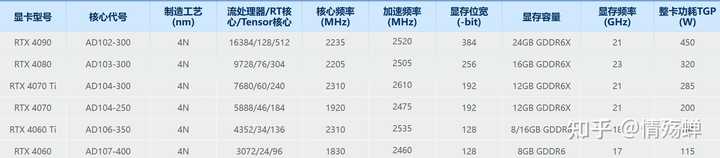
30ϵ�Կ����� �ٳ��40ϵ��ʲô�������۸�һ������IJ��У�����Ҳ���4090�Ҳ��Ҹ���512bit�� |
|
|
Ԥ���£�50ϵ�еı�40ϵ�е���������1�����ĺ���������������������2������Ƶ��С����3���Դ�λ��������������ټӸ�4���ڴ�����������������ˬ�ˡ������ϻ������ˣ������������ݣ��ܱ�֤��2�����������ĸ��»���������3�����ϻ����ķ����ˣ�����4�����ϻƾͿ��Խ���̳���ܹ����ˡ� |
|
|
| [�ղر���] �����ر��ġ� |
| ���� �������� |
| ��ο�������Ƽ������Ѽ��Կ��ȼ�4060�� |
| ���OPPO�����Ҵ��ԣ������ķŵ�Ů���г��� |
| OPPO�������������Ϲ����İ������Խ������ |
| ������ۻ�ΪMatePad Pro Max 4.7���׳��ᱡ |
| ��ο���С�� YU 7 GT 38.99��ļ۸� |
| ��ο���ijЩ�˲���װ��թapp? |
| ����Ƽ�Ϊʲô�����ˣ� |
| ����Щ�����������Ƶ����ͼƬ�� |
| ����A7R5�۸���ն�Ѿ�����A7M5�ˣ�����̬�� |
| �����������ۺͻ�������Ʋ������������� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
|
��������:
��ӰƱ��
����Ȧ
����
����
����
�����
ӡ��
�ɼ�
��س
����
��ˮ
��Ǯ�ҽ���ר��
����
˫ɫ��
����ĸ��
����
ƹ����
�й�Ů��
����
nba
�г�
�ܲ�
����
���
��ɫ
�Ϻ��п�
80��
����: ���� �����ֶ� ������ķ�ȴ� �ʼ������� ����ͼ˹ ���� ����� ���� �ﰺ ����ʥ�ն��� ���� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ֪ʶ�� |