| |
|
|
| ֪ʶ�� -> ���� -> ���������ϵͳ��ֱ��������Ͻ��г�������ᷢ��ʲô���? -> �����Ķ� |
|
|
[����]���������ϵͳ��ֱ��������Ͻ��г�������ᷢ��ʲô���? |
| [�ղر���] �����ر��ġ� |
|
���⣬����ϵͳ�ͱ����������ζ������쳣���м����ء� |
|
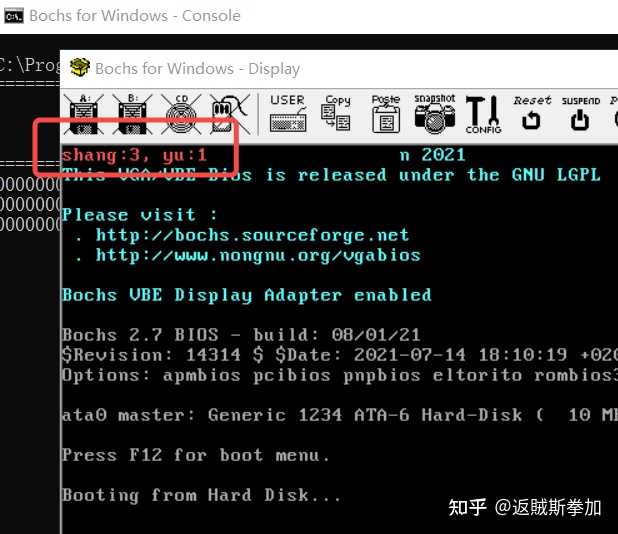
�ղر��࣬���һ����һ���� ͦ��Ȥ�����⣬�����������Ĵ𰸽��ĺܺã��������������������������Ƚ϶࣬����ʵ��һ�ѿ�����������´��������bochs��qemu��virtualbox��Щ����vm�����У������ͬ�� ���д�˸�һ����boot���桤������У��ȿ��������ģ��������ij��� 7/3 ��2 ��1��Ȼ��ѽ����������ϴ��룺 ����Ĵ����� nasm test_div_0.asm -o boot.bin ���룬Ȼ��д��һ�������ļ���ͷ512�ֽ����棬Ҳ����Ӳ�̵ĵ�һ��������Ϊβ���� 0xaa55 ħ����bios����Ϊ����Ǹ����������������ӵ������512���ֽڴ�����ص��ڴ��������У����ʱ��û�в���ϵͳ��������Ϊ����������������ԭ����bios���汾������rom����Ĵ��룬����Щ��д����������ģ��������ǿ�����Ϊ���ھ�������ˣ� bochs�������������ͼ�� |
|
|
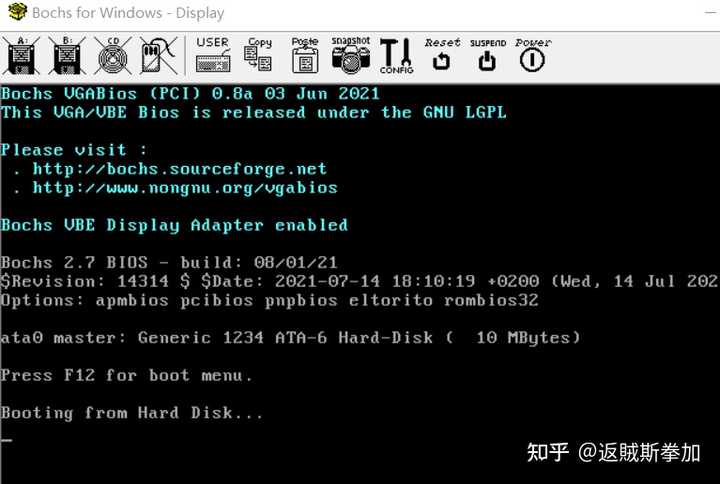
����ұ�ע�ˣ����Ŵ��룬������Ϊ���ǵIJ��Գ���ɹ��Ľ�����7/2�IJ��� ����������0�����⣬�Ĵ��� ���У� |
|
|
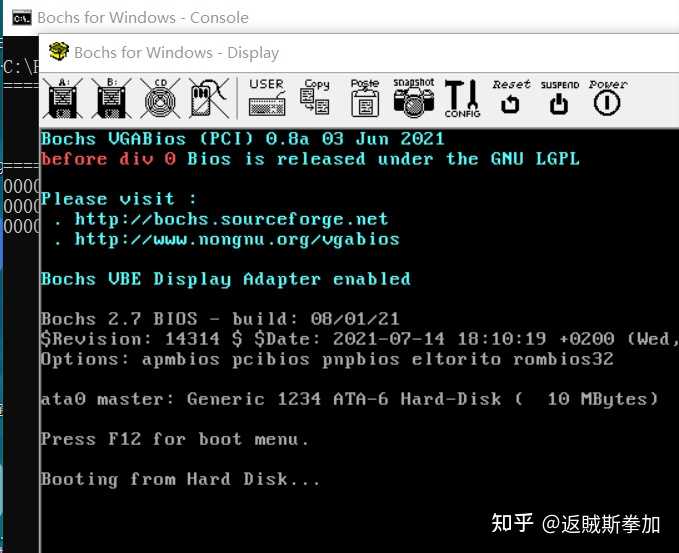
���Σ�û�д�ӡ�κζ���������Ԥ����ܻ������0��error����ʾ��Ȼ����û�� �ӵ���־���� ���� |
|
|
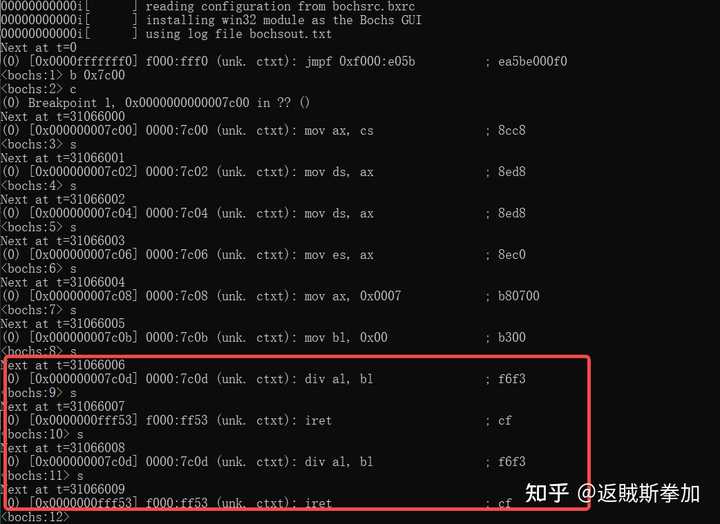
���Կ�����ֻ��ӡ�� before div 0������Ĵ��붼û�������� ���ԣ����Իش����������⣬����������г�0���ᵼ��CPU��0�쳣~~~~ �������������ǿ����ˣ�����ɶ��������Dz�ȷ������������£�ֻ�ܶϵ������ˣ�д�����ij�0���� bochsdebug���������öϵ㣬���е��ϵ㣬Ȼ����div al, blָ���һ�����ῴ����ת����f000:ff53 λ�ã�ִ�� iret���ַ����� div al, bl����һ��������ת��f000:ff53 λ�ã�ִ�� iret���������������ֻ��������ѭ����ȥ���ӵ����Ľ�������ﲻ�ǻ����������������е�������dz�0�жϵķ��� |
|
|
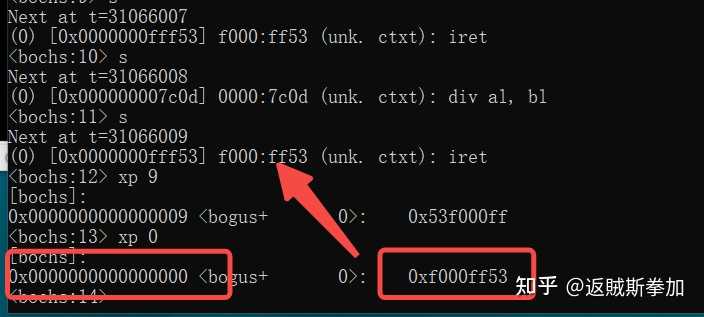
���ھ����о�һ��f000:ff53 �����iret��ʲô���������֪��bios�ӵ����������rom�й̻���һ���ִ�����ؽ��ڴ棬����һЩӲ�����ͳ�ʼ��������Ȼ����Ǽ����������������ǵij�0���룩 ����rom��bios������һЩ��Ҫ���ܣ������̣���ʾ���ȵȣ���Щ����ͨ��bios�ж����������ṩ�ģ��ж����������ǿ��������һ������ָ�����飬������±���Ǹ����жϺţ����жϷ�����ʱ�����жϺŲ����ж����������ҵ���Ӧ���жϺ���ָ�룬���ҵ��ã���ɺ��ط����жϵ�ָ������ִ�� ��ô������²� iret ���dz����жϴ���������f000:ff53�������������ָ�루��ַ������CPU��������ʱ�ᴥ�������жϣ�Ȼ����ת��f000:ff53ִ���жϴ�����������Ϊ����жϴ�������ɶ��û�ɣ�ֱ��return�ˣ����Է��غ��ٴ�ִ�г���������ٴ������жϣ���������ѭ���������� Ϊ����֤��һ�㣬����ֻҪ���ж����������濴����0�жϵ�ָ����Dz���f000:ff53�����ˣ���Ϊbios���ж������������ڴ��0��λ�ÿ�ʼ�ģ���0�ж�����0���жϡ����������Ӳ��Լ����û��Ϊʲô������������ֻ��Ҫ�鿴�ڴ��0��λ���е������Dz���f000:ff53���У�ִ��xp 0��ӡ0λ�õ��ڴ� |
|
|
�ư��ˣ�0��λ������������ǵ�Ԥ�ڣ���base:0xf000 offset:0xff53���պþ���iret�ĵ�ַf000:ff53 �������ǿ��Իش�һ�´����������� ���������ϵ��������bios���������0���Ҳ�֪����ô��֤��ͳ�����ϵ������һ̨����װ����ϵͳ����û�а�װ����ϵͳ����µĻ�������0���ᴥ��bios�����жϣ�������Ϊ����ж�ɶҲû�ɣ����Իᷴ��������������ͻ�һֱ��ѭ���������� ע�⣬���ϲ��Ի�����intel x86 cpu����bochs���°汾��bios���룬�������һ������bios��д����ӡ��0������ϢҲδ������ ����һ�£�����ϵͳ���dz�����Ʊ����ȥд�ģ����ǿ���Դ�룬BIOS���Dz�����ȥд�ˣ����������Ѿ��ٵ�BIOS�ˣ�����������Ļ���IJ�̫���ˣ����Կ���һ��BIOS��Դ�룬ȷ��������IJ²� �����ͼ�еĴ��붼��BIOS�����Dz���ϵͳ���룬��ˢ������BIOS�еĴ��� |

|
|
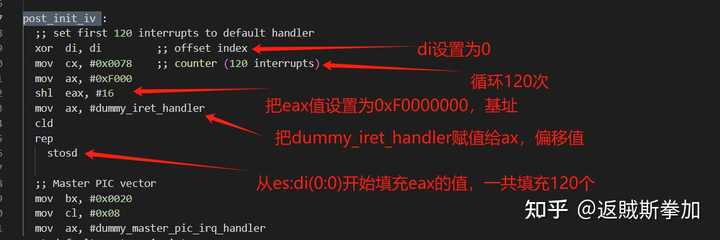
��ͼ���Կ���������δ����es�Ĵ�������Ϊ0�����ҵ����� post_init_ivt����ʼ���ж������� ���ռ�һ������֪ʶ rep ָ����ָ�ظ�ִ�к����ָ�cx�Ĵ������汣����Ҫִ�ж��ٴ� stos ָ�����˼�� mov es:di, ax Ҳ���ǽ�ax�Ĵ����е�ֵ shl ������ָ�� �������ǿ�post_init_ivt��ʵ�� |
|
|
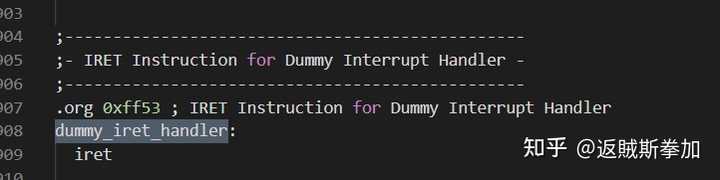
��������ڳ�ʼ��BIOS�ж�����������Ϊes��di����0�������Ǵ��ڴ����ʼλ�ÿ�ʼ���õģ��ж����������� base:offset����ʽ������base�� 0xF0000����ôdummy_iret_handler���ƫ��ֵ�Ƕ��٣� |
|
|
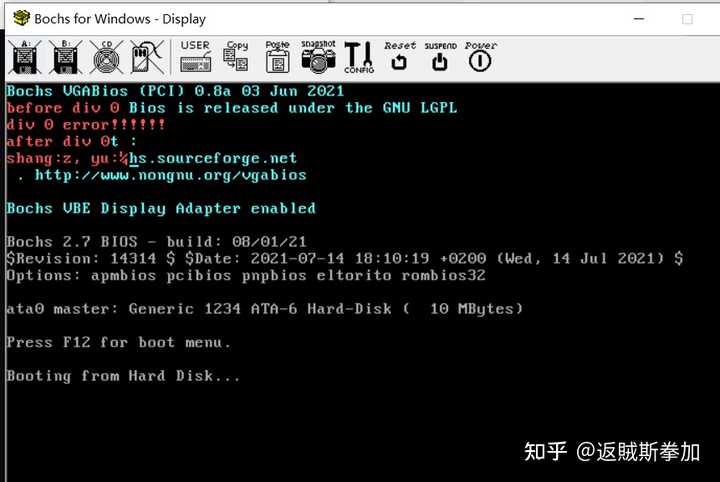
���� dummy_iret_handler����0xff53�������ж��������е�base:offset���� 0xf000ff53���������������ģʽ��xp 0��ӡ���ж�������һģһ�������Է��������쳣��ʱ��CPU��ȷ�����ж���������ת����0xf000ff53������ִ����iret ���������Ҿ�������������Ǹ�һ�����ˣ����Կ���BIOS��ǰ120���ж�����������Ϊ��dummy_iret_handler��Ҳ����˵��Щ�ж��쳣��BIOS�������ܣ�BIOS����������ô������飬��ֻ���ṩ����ϵͳ��д�߱�Ҫ�Ĺ���֧�֣������̵ȵȣ������������鶼�Dz���ϵͳ����֮����д�����ж��������� ����������������Ϊ���������У���С�����Ϊ��0�ж������ش������������������������ߵ��˳�0�жϣ����Բŵ��µĿ���ȥ����ѭ�����������Ʋ��Ǵ��ģ���0�жϵ�ȷ��CPUӲ���߿��Լ����쳣������CPU�ᴥ���жϣ��жϱ�������ش�����д�����BIOS�е�dummy_iret_handler��������һ���жϴ������� ��ʵ�б���������0����������Dz����ߵģ����������������ˣ����ܳ���ֱ�ӱ��ˣ������׳��쳣��������dummy_iret_handler����ѭ����������������ַ�ʽ�������ټ���ִ�г������Ĵ����� ��������Ʊ���Ҳ�Ҫ����ã���Ҫ�Ҿ��ã��ҷ�Ҫ��0�˲���Ӱ�����Ĵ���ִ����ô�죿������д�˸��Լ��ij�0�жϳ���BIOS�ĸ��ǵ���������0����ӡһ��error��Ȼ�����ִ�д��룬���������棬����Ҳ���Կ�����ô��Ϊ��iret���ص�ַ�������ĺ����� : ) bochs���� |
|
|
��ͼ �ڳ�0�жϷ�������ȷ���������Լ�ʵ�ֵij�0�жϴ�������ͨ������ջ�б�����IP��iret���ص�ʱ��ֱ��������0�����������ִ�ж���0�ˣ����ߺ�������������ԣ��˴�ֻ�����ֶ��ѣ����� |
|
���ȣ�����ϵͳ�Dz���������Щ�����ģ���ֻ�����cpu�Ĺ��ܷ�װ������¶һЩ�ӿڸ�Ӧ���������������ʹ�ã����ۣ�����������������������ɶҲ�����������ǿ������ĵط��ᷢ���ܶ���Ȥ���� �ȴ����ԵĽǶ����������ڳ��������C ����ȷ�涨������������������������δ�������Ϊ C99����https://www.open-std.org/jtc1/sc22/WG14/www/docs/n1256.pdf����C11����https://www.open-std.org/jtc1/sc22/WG14/www/docs/n1570.pdf��6.5.5��5�ζ����ᵽ�� δ�������Ϊ��ζ�ű�û��˵�����������飬�����ܻ�����������������Ľ�������ܻ����Ҳ���ܲ��ᣬʵ���ϱ�����Ĭ�ϻ����ʽ�ij�0���и澯�� |
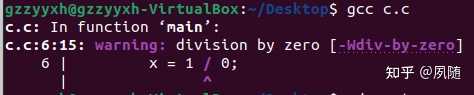
|
|
����ͨ�� gcc�ڱ���������׳�һ��warning�����Ⲣû����ֹ����������̣�����ǣ� �����warning���ɼ�����������һ���Ե���ʾ���⣬�Գ���������Ӷ������� �Ӵ������ĽǶ�������ʵ���϶ԡ�divide by zero���ļ������cpu���Ӳ����·��ɵģ� ���������ִ�C������/FPU��ʹ�õ�IEEE 754����http://people.eecs.berkeley.edu/~wkahan/ieee754status/IEEE754.PDF����10ҳ�������ģ����ڸ�������Ϊ�������ij������㣬�����������ΪĬ�ϵķ��ؽ���� ���������������Ȳ��ṩinfҲ���ṩNaN�����Դ�����ֻ�ܴ����쳣��exception���������߲���ϵͳ��ֹ���̵����У�ͬʱ���������û��� ��Ϊ��֤�������벢�������´���ʱ�� �������Floating point exception (core dumped)�Ĵ���ע����������˳�����еģ�ֻ��ʵ�����ڴ�������ʱ�Ż��������ͱ���cpuִ�е���0ʱ�׳��쳣��ֹͣ��ǰ�����ִ�в�������Ȩ���ظ�����ϵͳ�ںˣ�trap�����ɲ���ϵͳ�����¼���ͨ���ǵ����쳣���������ж��������е�ijһ����Ŀ������ӡ���쳣�������Ϣ �����������Ǹ�����ʱ�� ������ӡx = inf�� ���Զ��ڴ������������RISC-V���������⣩����������divide by zero��ʱ���������쳣��FPUҲ��״̬��־��ALU��FPU�Dz��еģ�������Ǹ������������ֹ�������У����һ᷵��ȷ���Ľ��inf ��x86�ܹ�cpuΪ���� cpuͨ��8λ���ж�������ͨ���ж���������IDT���ҵ���Ӧ���жϴ����������ڵ�ַ���漴����Ȩ���ɲ���ϵͳ�ں˽��й��ϴ�����x86��ϵcpu��ÿһ���жϺ��쳣������һ��vector number����ΧΪ0-255��һ����256���쳣���жϣ�ǰ32��vectorΪ���������������쳣������32-255��ָ��Ϊ�û�������жϣ����Ҳ��ɴ������������ж��������������ڴ��У���8086PC�����ж�������ָ�������ڴ��ַ0������0000��0000��0000��03FF��1024����Ԫ�����ж���������Intel? 64 and IA-32 Architectures Software Developer��s Manual Combined Volumes�б�6-1�г��˲����쳣��Ϣ�� |
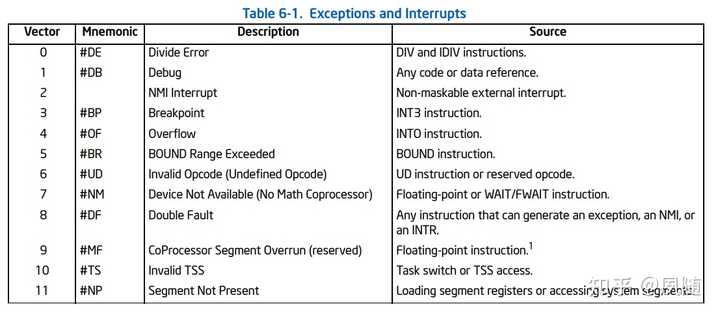
|
|
Exception and Interrupt |
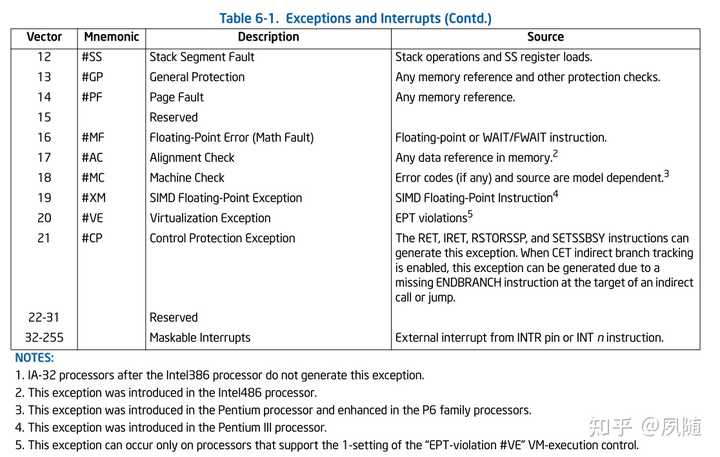
|
|
Exception and Interrupt IA-32��AMD64 ISA��#DE�����������쳣��ָ��Ϊ�ж�0�������쳣�����ж�16��x87���㣩���ж�19��SIMD���㣩�������������㷢��ʱ��������ת��0���жϴ�������ִ�У���ǰ���������߲���ϵͳ��ֹ��ǰ���̲����������Ϣ�� ���ڸ������������˴�������x87 fpu floating-point exception handling���쳣һ����6������� |

|
|
six classes of exception conditions ���г����������ֲ�8.5.3������ϸ˵���� |

|
|
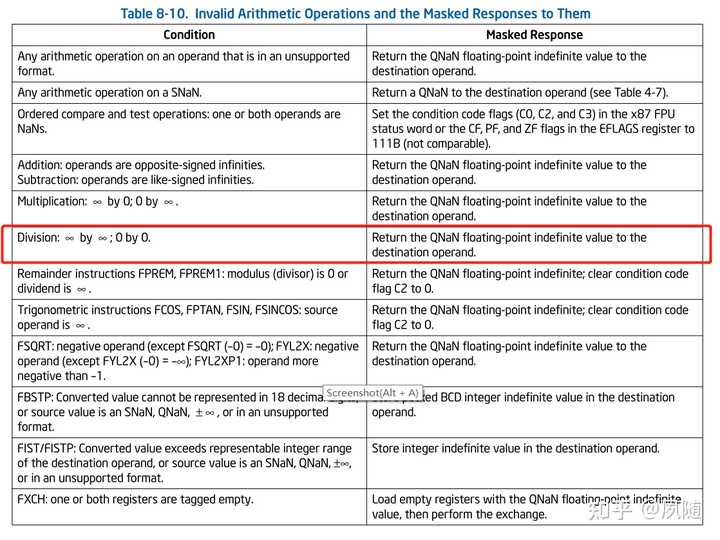
Divide By Zero Exception �ɼ���0����ʱ��Ϊ�����x86 cpu����һ�������ŵ�inf�������ᵽ�ı�8-10�� |
|
|
Invalid Arithmetic Operations and the Masked Responses to Them �ɼ�����ǡ� �� ��0 �� 0��x86 cpu�����ս���Ƿ���һ��NaN ԭ��˵�����£� The x87 FPU is able to detect a variety of invalid arithmetic operations that can be coded in a program. These operations are listed in Table 8-10. (This list includes the invalid operations defined in IEEE Standard 754.) When the x87 FPU detects an invalid arithmetic operand, it sets the IE flag (bit 0) in the x87 FPU status word to 1. If the invalid-operation exception is masked, the x87 FPU then returns an indefinite value or QNaN to the destination operand and/or sets the floating-point condition codes as shown in Table 8-10. If the invalid-operation exception is not masked, a software exception handler is invoked (see Section 8.7, ��Handling x87 FPU Exceptions in Software��) and the top-of-stack pointer (TOP) and source operands remain unchanged. Normally, when one or both of the source operands is a QNaN (and neither is an SNaN or in an unsupported format), an invalid-operand exception is not generated. An exception to this rule is most of the compare instructions (such as the FCOM and FCOMI instructions) and the floating-point to integer conversion instructions (FIST/FISTP and FBSTP). With these instructions, a QNaN source operand will generate an invalid-operand exception. 8.7�ھͲ����������ˣ��漰���жϿ��������ж�/�쳣������ϸ�ڲ����������������жϴ����������õĹ����Լ�������ôʵ�֣�Ӧ����linuxԴ��������ҵ��� ����������� x =1/ y;�滻Ϊx =-1/ y; ,������ӡx = -inf ����������� x =1/ y;�滻Ϊx =0/ y; ,������ӡx = NaN ISO C99�����˲�ѯ�Ͳ�������״̬�ֵĺ��������ǿ����ڷ���ʱʹ����Щ�������δ������쳣����Щ������������ IEEE 754�쳣���������� FPU ���������в�ͬ���쳣�����ҽ���FPU ֧�ָ��쳣ʱ���Ŷ���ÿ�����������ǵĶ�����fenv.h: ���ͺ�����֮���������𣨴�����Ԫ���жϴ���������ڲ�ͬ���������ڸ������ı�ʾ���������Ͳ�ͬ���������ʵ���Ͽ��Դ洢��ʾ������ֵ������������ʾ��������������������κ�λģʽ���Ǵ���ģ���Ϊ����һ���ض�������ֵ��������ֻ��ʧ�ܣ����ܲ���NaN��inf��Ϊ�����IEEE������涨�˸��������ָ����β��ֵ����֧����������ͷ�����NaN���ĸ��� |
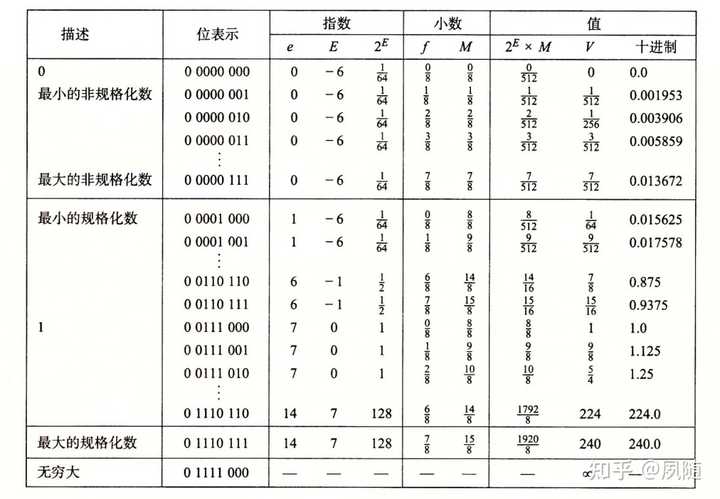
|
|
IEEE��������ʾ��8λ�� NaN�������֣����Ը����ʽ����ķ���ʵ�壬���������ͣ� Signalling NaN��������Ч�����쳣�ź�Quiet NaN���ڼ����������������д������������쳣�ź� NaN�����²��������� �� - ��, -�� + ��, 0 �� ��, 0 �� 0, �� �� �� �������͵�NaN���ɸ�ʽ�������Ȼ�˫���ȣ����������ƫ��ָ���ͷ���β����ʾ�� SNaN ��β��λģʽ�������Чλ����Ϊ 0���������������е�����һ������Ϊ 1QNaN ��β��λģʽ�������Чλ����Ϊ 1 �����������۵����������NaN���⣬�κ�����������������㶼����������������ɸ�ʽ���������ƫ��ָ������β����ʾ ���ڵ�����ֵ�� ���������λģʽ7F800000��ʾ���������λģʽFF800000��ʾSNAN ��7F800001��7FBFFFFFF֮���FF800001��FFBFFFFF֮����κ�λģʽ��ʾQNAN ��7FC00000��7FFFFFFF֮���FFC00000��FFFFFFFF֮����κ�λģʽ��ʾ ����˫����ֵ�� ���������λģʽ7FF0000000000000 ��ʾ���������λģʽFFF0000000000000 ��ʾSNaN ��7FF0000000000001��7FF7FFFFFFFFFFFF ֮��� FFF0000000000001FFF7FFFFFFFFFFFF֮����κ�λģʽ��ʾQNaN ��7FF8000000000000��7FFFFFFFFFFFFFFF ֮��� FFF8000000000000FFFFFFFFFFFFFFFF֮����κ�λģʽ��ʾ ��Ϊ��֤�������������´��루GCC12.1/C17���� ������ӡ�� �������Ҫ���Լ��ij�����ʹ����������кܶ��ַ��������ڵ����ȣ�����һ���ǣ� ���ַ��������ڱ��������������κβ���IEEE�����ʽ�Ĵ�������x86�ȣ������߸����ģ� Ҳ����ֱ��ʹ��math.h�еĺ�INFINITY ��C11 standard (ISO/IEC 9899:2011)��7.12��4���������� ���ʵ��֧�ָ�������� INFINITY ����չΪ�������͵ij�������ʽ���������Ϊ����������������ʵ�ֲ�֧�ָ�������� INFINITY ����չΪһ����ֵ����֤�ڱ���ʱ���������������ʹ�ô˺�����ɱ��������档 ����math.h���У� __builtin_inff()��gcc�����������ú���������Ҫ�����κ�ͷ�ļ�����ʹ�ã����������������������ӡ�䷵��ֵ�� ͬ�����õ�inf ��math.h�л��кܶ����Թ�����ʹ�ã������ж�һ���������Ƿ���������������ֵ �� ���У� fpclassify()������ֵ����Ϊzero��subnormal��normal��infinite��NAN����ʵ�ֶ������� �������������´��루DBL_MINΪfloat��double��long double�Ĺ�һ��ֵ���� ���õ��� �����ʵ��ϸ��Ҳ��math.h�У� �����е�__fpclassifyf����鵥���ȣ�Ϊ������ʵ��ϸ��Ҳ��math.h�У� ������һЩ���Ͷ��壬�Ǹ���IEEE�������ͼ������� ������˵��RISC-V���������ᷢ����0�쳣������RISC-V�ܹ�Ϊ�˼�Ӳ����ƣ��ܶ�RISC�ܹ��Ĵ����������������ܹ����������������ʱ���������磨Overflow�������磨Underflow�����ǹ��������Subnormal���ͳ��㣨Divide by Zero�������ᴥ���쳣��ת��trap���Ӷ������쳣ģʽ����RISC-V�ܹ���һ������֮�����Ƕ��κε�����ָ������������븡��ָ����������쳣�����Dz���ij�������Ĭ��ֵ��ͬʱ����ijЩ״̬�Ĵ�����״̬λ���������Դ����������ˮ�ߵ�Ӳ��ʵ�֣�RISC-V�ܹ��Ƽ�����ͨ�������������ҵ���Щ���� ��RISC-V�ٷ��ĵ�Volume I: Unprivileged ISA��https://github.com/riscv/riscv-isa-manual/releases/download/Ratified-IMAFDQC/riscv-spec-20191213.pdf����7.2�������˵���� The semantics for division by zero and division overflow are summarized in Table 7.1. The quotient of division by zero has all bits set, and the remainder of division by zero equals the dividend. Signed division overflow occurs only when the most-negative integer is divided by ?1. The quotient of a signed division with overflow is equal to the dividend, and the remainder is zero. Unsigned division overflow cannot occur. |

|
|
Semantics for division by zero and division overflow. L is the width of the operation inbits: XLEN for DIV[U] and REM[U], or 32 for DIV[U]W and REM[U]W We considered raising exceptions on integer divide by zero, with these exceptions causing a trap in most execution environments. However, this would be the only arithmetic trap in the standard ISA (floating-point exceptions set flags and write default values, but do not cause traps) and would require language implementors to interact with the execution environment��s trap handlers for this case. Further, where language standards mandate that a divide-by-zero exception must cause an immediate control flow change, only a single branch instruction needs to be added to each divide operation, and this branch instruction can be inserted after the divide and should normally be very predictably not taken, adding little runtime overhead. The value of all bits set is returned for both unsigned and signed divide by zero to simplify the divider circuitry. The value of all 1s is both the natural value to return for unsigned divide, representing the largest unsigned number, and also the natural result for simple unsigned divider implementations. Signed division is often implemented using an unsigned division circuit and specifying the same overflow result simplifies the hardware. ��ͼ��Floating-Point Control and Status Register��fcsr�Ĵ������ı��룺 |

|
|
Floating-point control and status register ����������쳣��־λ��fflags��������������㵥Ԫ�������г�������Ӧ�쳣����Ὣfcsr�Ĵ����ж�Ӧ���쳣��־λ����Ϊ�ߣ�����֪�����ۼƣ���������ͨ��д0�ķ�ʽ���ij���쳣��־λ����ͬ���쳣��־λ��ʾ���쳣��������ͼ���ٷ��ĵ���Volume I: Unprivileged ISA��11.2�ڸ�������ϸ˵���� The accrued exception flags indicate the exception conditions that have arisen on any floating-point arithmetic instruction since the field was last reset by software, as shown in Table 11.2. The base RISC-V ISA does not support generating a trap on the setting of a floating-point exception flag. |
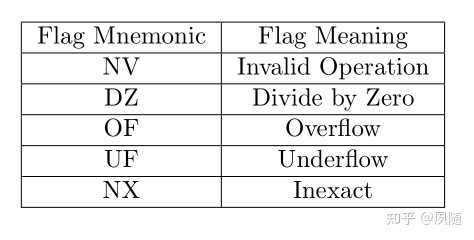
|
|
Accrued exception flag encoding. As allowed by the standard, we do not support traps on floating-point exceptions in the base ISA, but instead require explicit checks of the flags in software. We considered adding branches controlled directly by the contents of the floating-point accrued exception flags, but ultimately chose to omit these instructions to keep the ISA simple. ��11.3�ڶ�NaN�����Ҳ��˵���� Except when otherwise stated, if the result of a floating-point operation is NaN, it is the canonical NaN. The canonical NaN has a positive sign and all significand bits clear except the MSB, a.k.a. the quiet bit. For single-precision floating-point, this corresponds to the pattern 0x7fc00000. |
|
AArch64��������0�Ľ��Ϊ0 RISCV64��������0�Ľ��Ϊ-1 �ý�����ܲ���ϵͳ��Ӱ��, ��ͨ��MSR�ȷ�ʽ�ı�. X86��������0�������������������X86���е���Ϊ(�ݳ�IBM���ͻ��õ�S390xҲ��������Ϊ, �����ֻ����ȽϺ���) ������C��������0ΪUB, ��˳��DZ��������Ծ�̬��ȷ��������Ϊ0(��ʱ����ֵΪ��Ⱦֵ), ���������������κμ��. �������´��� ARM64 ��ARM64 macOS������ 2/0������Ϊ0. Microsoft VC++��������AArch64�ܹ��»�ģ��X86����Ϊ, ���Dz��������, �ڳ�0ʱ����WIN32�쳣. RISCV ��RISCV64 Linux������ 10/0���Ϊ-1 RISCV�ij���ָ��ΪMָ����չ�е�divָ��, ����֮���divu(���ų�)��rem(����), remu(��������). ��������Ϊ���±��� ConditionDividendDivisorDIVU[W]REMU[W]DIV[W]REM[W]Division by zerox02^L???1x??1xOverflow (signed only)?2^(L?1)??1�C�C?2^(L?1)0 ����RISCVû����ʷ����, ���32λ��64λ����Ϊ��һ�µ�. ARM32 ��ΪARM32�³���ָ���ǿ�ѡ��, ���Ĭ�ϱ�������ARM32/Thumb32�µ���__aeabi_idiv���������������. ������Ϊ0ʱ, �ú�������int __aeabi_idiv0(void), ����Ĭ�Ϸ���0, ��˳�0�Է���0. ���ǿ���ͨ���滻�ú����ķ�ʽ�����0����Ϊ. ��Ϊ֧����������ָ��SDIV/UDIV��CPU����ʱ, �������������ɼ�����. ARM����������ָ���0�Է���0. MIPS MIPS�Գ�0�Ľ������Ϊ��Ԥ���ֵ. ����MIPS��ISA Spec�н����������divָ�����������, ��˱�����Ĭ�ϻ����ô���, ����ʹ�������в���-mno-check-zero-division�ص�����Ϊ. �������´���: ���ɻ�� teq��trap if equal. MIPS�ܹ��dz�����, �����Ľ��Ҫ��mfloָ���һ�Բ��ɼ��ļĴ���hi, lo�а����. LoongArch LoongArch������MIPS���ƵĶ���: When the divisor is 0, the result can be any value, but no exception will be triggered. GCCĬ��ֻΪ-O0��������� LLVM�ƺ����Dz����������: PowerPC ��MIPS����, ��0�Ľ����δ����. ��LLVM�ƺ����Dz����������. ������Ļ���������IBM�Ĵ�������? X86 ��x86_64 Linux������ �����ش��Ѿ��ᵽ��, x86_64��floating point exception(SIGFPE)��Linux������ת��Ϊ�źŵĽ��, ��������ֱ�Ӵ�����������Ӧ���жϴ�������. Rust������� ��Rust�г�����0�ᵼ�±������, ����ȻLLVM��Ϊ������0ΪUB, Rust������safe Rust�Ĵ������UB, ��˻���MIR������. �������´��� ��MIR���� ��X86������� �ɼ���Ҫ���3��, ������Ϊ0, ����ΪMIN�ҳ���Ϊ-1. �����������, Rust�Գ�0�ļ����Releaseģʽ��Ҳ���ر�, ���Rust�ڲ���ϵͳ�º�������³�0���ǻ�panic. Rust�ṩchecked_*ϵ�к���, ��������������ͳ�0ʱ����None, �����Ͳ��ᴥ��panic, �������û�������δ���Option���. checked_div��Դ������, ����unchecked_div��ӦC/C++������. WebAssembly WebAssembly��һ�������ָ�, �ҵ���������0�����������Ϊ�ұ�д��WebAssembly�������ڲ��Թٷ��IJ�����ʱ����. WebAssembly��spec��Ȼ˵������0��������������Ľ����δ����, ��ʵ����Ҫ�����Trap. ���WebAssembly�Ǻ�X86һ��Ψ��������0��������ļܹ�. |
|
������ִ������ԣ���BASIC��Python��Java�ȣ�����������ʱ���ȼ�������Ϊ�����л���Ӧ�ĶԲߣ��������׳��쳣�ȣ���ǰ���أ�CPU��������ִ�г��㡣 ��C�������������������������㣬ֱ�ӱ�������CPU����ָ������롣 ��CPUִ�г���ʱ����Ϊ������ָ��Ķ���;��������·����йء� ��������Ϥ��8051��ֻ��һ������ָ��DIV AB���ѼĴ���A��B�����ִ�к�AΪ�̣�BΪ���������BΪ0����ִ�к�A��B�е�ֵΪδ���壨��˼�ǿ���MCU����������ں˵�·ʱ�������һ���DZ��ֲ��䣩�������־OV��1�����B����0��OV���DZ����㣩��Ȼ�����ִ����һ��ָ�û��ʲô������¼������� ��ARM��ᴥ���쳣�������жϣ�����ת���쳣����ִ���жϳ��� ����ϵͳ�ܷ�����쳣Ҳ�ǽ�����CPU�ܹ����֮�ϡ� ��ARM����CPU�ϣ���Ӳ���жϲ�����㣬���쳣���������������ϵͳ�ں˱������ ��8051����CPU�ϣ�û��Ӳ����Э����ֻ������������顣�õĿ⺯�������ȼ������������º���OV��־����ʵ���������Dz�ȥ����������δ����Ľ���� ������������DZ����ߵ����Ρ�Ӳ����OS���쳣�������Ʋ�������������ô����ƨ�ɵ�~ |
|
|
���һ����λ�����ʡ� C���ԣ���������Ч�ʵĿ������涨��������Ϊ��ʱ��������ȡ��Ϊδ������Ϊ��undefined behavior�����UB��������ζ�ţ�C���������ֱ������CPU����ָ���������ʱЧ����ߣ���Ϊû����ǰ�º�ļ�鲽�裩������Ϊ��ʱ��UB�Ĺ�˦��CPUָ��� ���ĸ�ֵ���ұ��DZ����ڳ�������������ֱ���������ٸ�ֵ����3/0�㲻���������Ա�������������棬����Ȼ���ܱ���ͨ������������ʲô���Ļ����벻�ö�֪�� ����ij� ��ô���Ƚ����ʵı�����������GCC�����������ʱbʵ����Ϊ0���������棬���Իᰴ�������ɳ���ָ���һЩ�ģ�����һЩ��������ָ��ı�ԴC���������Ͳ������κξ����ˡ� ���һ������Ҫƽ��������棬C��������⡣C��ȡ�������µ�Ч�ʣ���˸߶����α����ߡ���ϤC���Եı����������������ɪ��г��������ã������Ч�Ļ����롣 C�й涨��UB�������Ǹ��ֲ��᷸�ĵͼ�����C��ԸΪ��Ԥ�����Ƕ���ʧЧ�ʣ���ΪUBҲ����һ��˦����Ϊ�ɡ� ������ @ī����ͩBA7MQN �ĸ����ٲ���2�䣺C��������warning��ʵ����ֵ�����DZ��������ߵľ���ᾧ��C��������UB����warningֻ�dz��ڵ��壬���������� |
|
�Ͳ���ϵͳû���κι�ϵ��ֻ��cpu�й�ϵ�� |
|
|
| [�ղر���] �����ر��ġ� |
| ���� �������� |
| ����Note17PRO�Գ���������Ʒ�ʷ��������� |
| �ʼDZ����Գ�����ȥ�ۺ�Ҫ��������壬�� |
| ��ο����߶� PC ���ơ�XCMOD�����ҡ���ծ2 |
| ��ο������� realme �˳��й��г����ۺ��� |
| ��ο��� 26 �� 7 ��DDR5�ڴ�۸��ٴα��ǣ� |
| ��ο�����Ϊ����90 Pro Max����3�����¼��� |
| 4399 Ԫ�����ҫ Magic6 ϵ��ֵ�����𣬺��� |
| ����diyȦ����Щ����? |
| Ϊʲôƻ����Ʒ��ô�� |
| ��Ӫ���ֶΣ�С����ıȻ�Ϊlow�� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
|
��������:
��ӰƱ��
����Ȧ
����
����
����
�����
ӡ��
�ɼ�
��س
����
��ˮ
��Ǯ�ҽ���ר��
����
˫ɫ��
����ĸ��
����
ƹ����
�й�Ů��
����
nba
�г�
�ܲ�
����
���
��ɫ
�Ϻ��п�
80��
����: ���� �����ֶ� ������ķ�ȴ� �ʼ������� ����ͼ˹ ���� ����� ���� �ﰺ ����ʥ�ն��� ���� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ֪ʶ�� |