| |
|
|
| ֪ʶ�� -> ���� -> �ҹ�Ϊʲô���ƹ���о�� -> �����Ķ� |
|
|
[����]�ҹ�Ϊʲô���ƹ���о�� |
| [�ղر���] �����ر��ġ� |
|
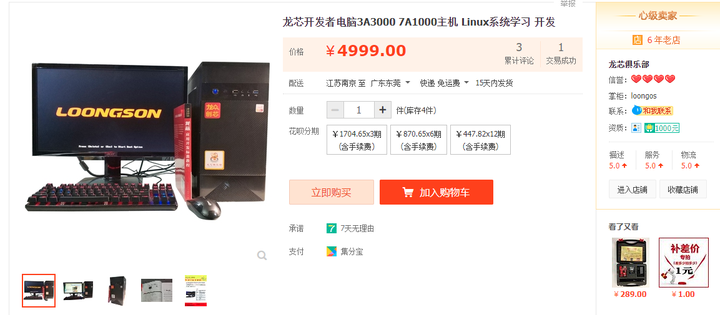
��о���ڿ�����Ӧ��������J1800���߸�ǿ�������ˣ���Ȼ������windows����������칫�ĵط�Ҳ������Ϸ�����Ǽ��ð칫������Ҳ�����������ŵȡ� |
|
���������Ե�����: ������ ��о���� MIPS, ������Ϊ MIPS ��˵, ���������ֲ���ȫ�������� MIPS: ���ߣ�Ң�Կ��� ���ӣ�https://www.zhihu.com/question/48881215/answer/518741822 һ��ʼ�Ƿ��� gobject-introspection ��������û�з�Ӧ���� ^C ���˳���������Ҳû���ҵ���������������ҹص���һЩ GTK �����ĵ��������������ֲ��ֱ��Ӧ��Ҳ�����������ǾͿ�ʼ gdb �����⣬�ҵ��������� FFmpeg �Ŀ������������ȥ���Dz��� FFmpeg �Ĺ������ò��ԣ�������ʲô���ء����˰��죨ʵ������һ���£�����֪��Ϊʲô���������������� Glibc �ĵ�����Ϣ���ִ��������� pthread ��� pthread ��ʱ����ִ�е���һ�� MIPS ָ���е� Load Link / Store Conditional��ll / sc��ָ��ԡ������������Dz���ʶ������������Ӳ�����⣺����о 3 ���У�ÿ��ִ�� ll ָ��֮ǰһ��Ҫִ��һ�� sync������ ll ָ��֮�� sc ָ��֮ǰ�Ĵ����������ת����תĿ��һ���� sync ָ�����ǰ����Ҫ���� GCC �� Binutils ������������Ҫ�����������ӡ�[5] ���������ҪӰ�� FFmpeg�������������� FFmpeg �������������������FFmpeg �Լ�������������� SIGBUS��SIGILL �� SIGSEGV�����������ý��ջ�����϶��ǻ��ģ����Dz����� FFmpeg �������ܵû���ͦ���ġ� ffmpeg ��һ����ý�幤��/��, �ܶ����ⲥ����/OBS �����Ķ�ý��Ӧ�ö�������. �������˵��, ����˵СҲ��С, ��Ϊ��ζ�źܶ����� MIPS-Linux ��Ӧ�þ�ҪΪ�˵�������һ���汾. ���������Ȼ����ԭ������ x86 Ӧ��. ��˵ͨ�� qemu ���п�ƽ̨ ISA ģ��, Ȼ������ wine ���ܹ�����������߰˳ɵ� Windows ԭ��Ӧ��... �������ܾͺܸ�����. Ҫ֪�� x86 ���ǿ��Լ����� 100% �������� 100%(Linux wine �� IO ������Щʵ�����첽��������) �������� Windows Ӧ��. Linux ����������, GPU �� AMD + ��Դ�����ľ�������ǿ������. 2. ���� ��. J1800 �� Windows ��Ҳ���Ǽ��������õ�ˮƽ(�������õĵ����� J5005 ���� 4415Y). ���ֻ����ǿ�����ƽ, ���������������ܵİ칫����, libreoffice, ����������ֲ�� WPS, �������ܲ���. Office �����⻯+wine �Ļ������� 03 ������. ��Ч����ȫ�ĵ��. 3. ���ɶ� �� J1800 �ӽ������ܵĴ����������Ĺ���, ��� CPU die �ϲ������ϱ��ź� GPU. ֮ǰ�ͱ� HT �� AMD оƬ��Ϲ������˺þ�. 4. ��̬ ���� nix �ϵ����治�ǻ��ڹ��ϵ� X ���ǻ��� Wayland. Ȼ����Щ����ϵͳ���ں˵���϶Ȳ���. ÿһ���������Ǵպ����õ�ˮƽ. ��֮ǰҲ˵��, ���Ҫ����, �����õȵ�ԭ��������. �ǿ����������ûɶ����������. ���� Chrome/Firefox ����, ������Ҳ�dz���... ����, �����������ص���վ���� IE Only, �Լ����� Flash��ActiveX �� SliverLight ��չ��... 5. �۸� һ�����ܽӽ� J1800 �Ķ���, ������Ҫ���� 3000 �� 4000 ��... J1800 ����ֻҪ 300 ���ܸ㶨����, 500 �㶨����, ���� thin itx... ����о�����ô��Ҳֻ������ matx... |
|
��ô�ƹ㣬��������ȷ����㿴�����ײ����ܲ�����������о�ϣ� �ϰ��գ�ʲô���⣬�������ֹ����ӲŲ����أ��������ֵ������������ء���ҵ��λ�����������ȵ�С����ȥ�� �����������ܲ����������ɣ���һ����ʲô�����Ǿ��군�ˣ��Ҷ��������ȶ��Ķ����������²���첻��������Щ�³��������㻹���ñ����Ժ����ȶ��������ɣ� �ط������� ������������Ƿ��ֵ��𣿲���ѽ�����ǵĻ�˭���ֵ�˭��취ȥ�������ȵ�С��������������Ӵ�˭���ϣ���˵�ˣ��ϼ��������ã�˵��������������ף�����ΪɶҪ�ã����з�����û�ô������¶����ɡ� ������������Ƿ��ֵ����ǰ����������������ɣ���ô����ء����������������ԡ� �¼����ء����� ���ƹ��¶����ˣ��ϼ����ʽ���û���������¶��ɲ��ˡ� ���ƹ��¶����ˣ��ϼ����ʽ��𣿾�Ȼ���ˣ������ɣ���˼��˼������࣬��������£� ���������������������������������������� �ⶼ��ʵ������������ͺ���˵�����Ǹ�������ϵ���ţ������Ķ���Ҫ���ã��������Լ�������ץ��һ��������ҵ���Ҫ֧�ֹ�����������������Щ����Ϣ����ҵ��Ҫ���Ѷ�IOE�������� ��IOEָ������������������˾���ֱ���IBM��Oracle�����ģ���EMC���װ��ţ������Ѿ������������ˣ�����Ӫҵ��ֱ��Ǽ��㡢���ݿ⡢�洢�����ǵIJ�Ʒ��ν���ҹ���Ϣ֧���İ�ڽ�ɽ�� ���뺰����ô���ꡰȥIOE������Ч���𣿶�����һ�㡣��ȥ����û�У�֤ȯ�����С����ա���ͨ����ȵȻ����õ���Щ������ �������߷�һ��֮������ⶳ���������������ɡ� |
|
�и�ǰ����Ц���� ��֧�ֹ�������ϵͳ�� ����֧�֣� ��֧�ֹ���CPU�� ��Ȼ֧�֣� ��֧�ֻ�Ϊ������ ת��������ʮ��֧�֣� ��Ը��칫����о������ ��Ը�⣡ Ϊʲô�أ� ��Ϊ�����õ��� |
|
|
|
|
|
��ô˵�ɣ�������о����̫�ͣ�����������ġ��칫��������ô�� ��о��ȴ���������칫������û����ģ����ǰ칫�������Ǽİ칫�� ����������ҵ�Ͳ��ţ��ֵİ칫��Ա�ĵ��ԣ����������������һ��İ칫����������Ҳ�ᰲװ���֣��������û��߾����õĴ�����������˵�ܶ���ҵ��Ա����ô�����ϰ��ר�İ칫�أ���Ҫ��������ô����ľ�����excel��ʵ��̫���ˡ� ��һ�㶼���������̬����Ӳ�����ܡ� ����������ҵ���������������վ�Ҫ����ȥ��Ӧ���������Ǿܾ��ı�ģ������ܶ��˰�xp��win7 win7��win10���������ء� ��Ӿ���Ӳ�����ܲ��㡣 ����һ����Ҫ��������ϵͳ��һ�����������ܣ���Щ�������ı䣬����Ŀǰ����ƿ����������ǹ����ƹ�����ܸı�ģ������г���������ġ� |
|
�ҹ��ƹ���ɣ� ��Ϊ�����Ƿ����˴��غ���1.0ϵͳ����ҫ�ǻ�����ȫ�����Android TV�ĸ���Ӧ�ã�����ADB�� ����A�������ˣ���Ϊ��������¢�ϣ�ó��ս�Ʋ������йؼ�������������� ����B������֧�ֵ�Ӧ��������ҲҪ����ɣ����ڵĺ��ɿ϶��Dz������ģ���Ϊ�����Dz�������սʿ�����������IJ�Ӭ�����²�֧�ּ���Ӧ����ҲҪ��Ǯ֧��һ�£��л���Ϊ�� -- �ҹ��ƹ���о�� ��о�����������ðɣ��Ѿ�������i3�������ˣ���̨ʽ���Ѿ�ûɶ�����ˣ�������Ѿ����ˣ�OfficeҲ���ˣ����������������������Ѱ��ˡ� ����A����ô�õ����ܣ���ƾɶ�����ã� ����B��Ϊɶֻ����Linux���Ҳ�����Linux���ο���QQ����office��û�У��㻹����˼�����ã� |
|
�ƹ�û���⣬���DZ���ijЩ���Ӱ�ܰ����黳������MIPS���û�������С�ף�������1000��İ���������������������8000��10000���档 Linuxû���⣬������������OpenBSD����о�Լ�������һЩ�ض�ָ�������MIPS64��ָ��������������ƺ�û���Ͻ��ȡ�����OpenBSD��ij���ض��汾֮��û�µ�CPU֧���ˡ� �����£� RISC-V�����ˣ�MIPSѹ��Ҳ�ܴ� ��IoT�г��ϣ�RISC-V + BSD����IJ�Ʒ����ȫ������ҵ��Դ������ҵ�г���������Ҳ˵�Ĺ�ȥ�� ������أ�Fullstack CRUD boy |
|
�����߲���ʹ��Ӳ����������ʹ�õ���app�� app������Ҳ��ʹ��Ӳ����app������ʹ�õ��Dz���ϵͳ���ṩ��api�����б�̡� ����ϵͳ����ֱ��ʹ��Ӳ����һ����������û��Ϊ��о�����IJ���ϵͳ���У����������С� ���ԣ����������ǣ�������ʹ��app��app������ʹ�ò���ϵͳ������ϵͳʹ��Ӳ���� ��ֻ�ƹ����Ӳ�������ƹ�֧�����Ӳ���IJ���ϵͳ������ʲô���أ� �������˾���ijij�ǹ�������ϵͳ������ijij��������ϵͳ����������Ŀǰ������֧����о�� ��ˣ��ƹ���о����һ������ҵ���������ƹ�Ӳ���������ƹ���о��ز���ϵͳ�������ÿ�����Ϊ��ز���ϵͳ�������������� ��һϵ�еĹ�����ȫ���ɹ��������Ļ������������������Ź����뻹����ģ�������û���㹻��Ͷ���Ԥ����������¡� ij˽����ҵ�����������������ƹ�������ִ���������˼��ֲ�����о����ô���أ� |
|
�������Ӧ����ô����ô�����CPUΪʲô��֪���ϣ�����оһֱ���ʣ�Ϊɶ��֧���ң��г����ã��û�����ѡ����Ϊɶ��Ӧ���ʵ���Ϊɶû�б��CPU�����ң���оӦ���ʣ�Ϊɶ�����Ϻ�������������������ԭ������о����о�������˰ɡ���Ϊ������ǿ�ɣ�Ϊɶ�������ʣ�Ϊɶ������ʹ���Ʋ�����ԭ������ǿ�������к��⡢���ں������������Ʋ������ˣ���Ϊ������Ŀ����������ܼ��㣡��о�Dz���Ӧ����������֮ǰ�������Լ���Ϊɶ�������������Լ�����������D�ķ��۰��� ˵���ף����Dz�Ʒ���У�����̬���Ҫ�����ȶ���������������ָ�����ʵ�����û����ҵ�ʹ�㣬����ʲôָ����У��������������������ס���������涼�ȱ��˲�����ܹ��������ø�С��������ģ����������ȶ����ܲ�����õĺˣ���һֱ�����ķ�����о�ͺ�˼����Щ�����Լ���CPU�˵ġ� �����磬���п�Ժ����������Ϊ����Ӧ��֧��������������Ϊ������Ӫ��ҵ��Ӧ�õ�����̬��������������߽߱ǽǾͺ��ˣ�����ǿ��ȥ�����ܵ�֪�������Դ����������Σ�20���Ѿ�մ���п�Ժ���ٹ⣬���ϰ�Ҳ���˹���xc����Ǯ���ϰ壬�����ɶ��û����������һ������ԭ��Ͳ����ˣ����������֪ʶ��Ȩ�۸���˭���ģ�����ɶʱ�������ҵ����Ȩ�ģ� ��Ϊ��о�ڹ���CPU�в���ͻ�������������������������ɿء� |
|
����û��ר���ƹ���о�������Ŵ�cpu���Կ����г������ڻ��ǻ�Ϊ�뺣�⣨amd��������ĺ�һЩ����Ϊ��Ϊ�ڲ���̬�ã�amd�����Ժá� ��о�ĵ�·����Ҫ��һ�㣬ƽ�����¥�������ڡ��������������Ҵ���˹��ڵ�����ǿ��cpu���������Ը���9000s��kx7000gĿǰû�п��۲�Ʒ�����ܲ���֪��amd�IJ����㣩��˳������һ����Сcpu �����ο�����������ϵͳ������һ��������������������������������Ӧ�������������˵Ĺ�ģ������ô�����飬���Dz����ס�ϣ����о������һЩǮ��������õ�cpu�� |
|
���������Ѿ��õ������������Ͽɣ������������Ҳ�õ������������Ͽɡ� ����˵�����˻����ܻ���Ͽɣ�����Ȼ������о���к�Զ�ĸо��� |
|
ж������ ��Ϊ��û�����õ����ò�Ʒ�����ҳ���ȫ�����˲�Ȼ��ƽ̨�ܵ��۵ģ�ָ�����һ�� |
|
1.��о����X86�ܹ����ò���Windows�� 2.��о����ARM�ܹ������ð����ò����ܺ�֧�֡���о��MIPS�� ������Ҫ����ͨ��;���ƹ���ҩ��ġ�һ��ʲô����ϵͳ���ò��˵����������г��� ֻ������о��Ȼ������ͨ������������רҵ�������� ����DSPоƬ��IP�� |
|
˵��Щ�е�û�Ķ�û���ã�ͼ��������һ���֪�� ��Ƶ����ͼ����̸����оȦû���ʸ�����о�Ƿ����࣬��о6����������7���ﵽ7��I5ˮƽ BV1W14y127FB ԭ��Ƶ��Ӣ�ض�ʹʧ���೧����������Ω����о���� BV1v84y1q7d7 gueenet�� 2022-10-21 ����о��С������ ���˱�ͼ�������еĶ�����Դ�����Ŀǰ���Ʒ��������ڣ���ȴ��ʼ���ղ�û��������λ��о��С���� ��ƪΪ��Ƶ�ʼǴ浵����û��̫�����֤ ʡ���� |

|
|
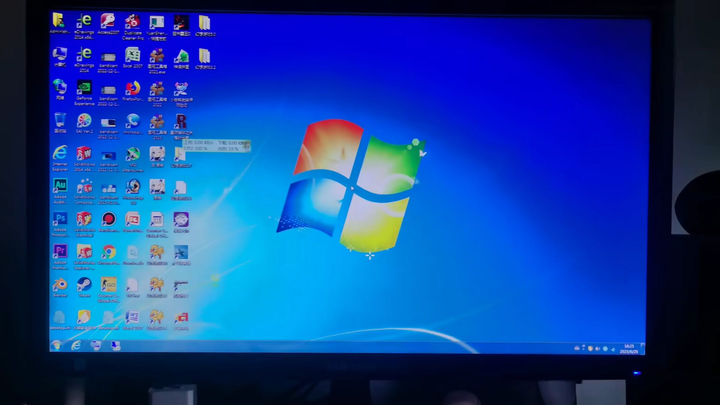
����ʮ��ǰ����оA˫�˰�U����������2023�����48���㻦���ʵļ۸��룬�ͺ�C4350AL |
|
|
|

|
|
����CPU��ռ��100%�ܳ�ʱ�������� ��һ������ܺ� |

|
|
|
|
|
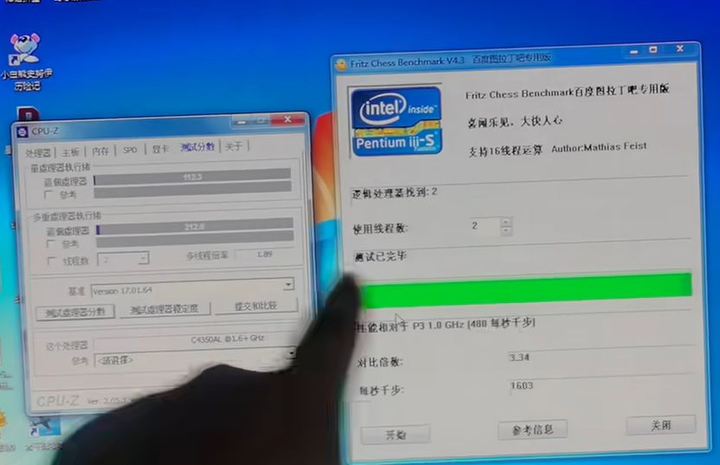
�����ܷ�ֻ��3���࣬CPUz�ܷ�200��ͷ |

|
|
19���KX6000����оE���˺˰�U��������2022���550���ʹ��룬����Ѿ�450���ʣ�CPU�ͺ�KX-U6780A |
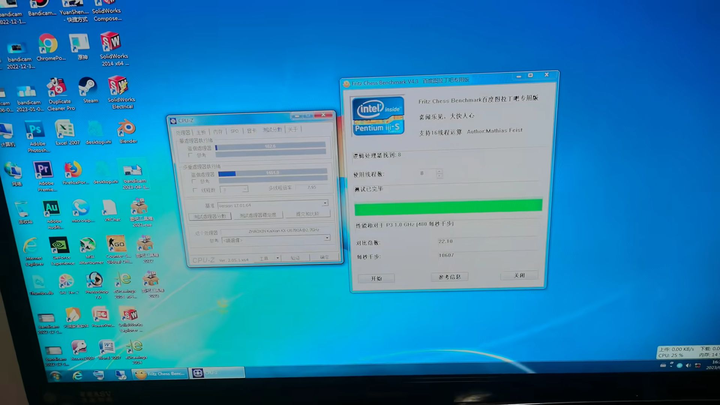
|
|
|
|
|
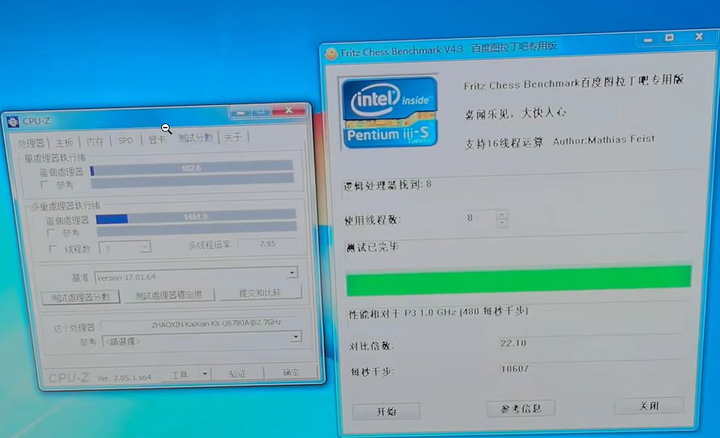
�����ֳܷ���22����CPUz����1400�� |
|
|
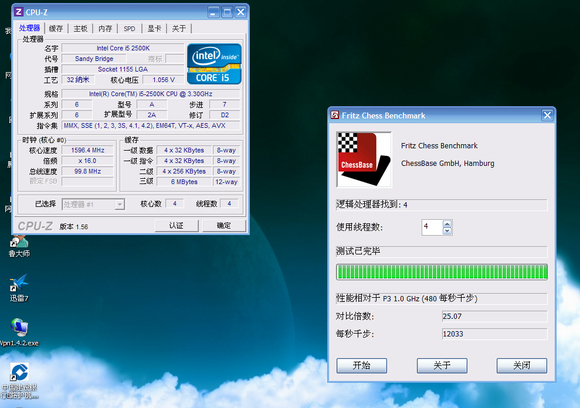
ͼ�ɵ�I5 2500K�ܷ�,���Կ��������ܷ�25.07 12033��4.0G�� |
|
|
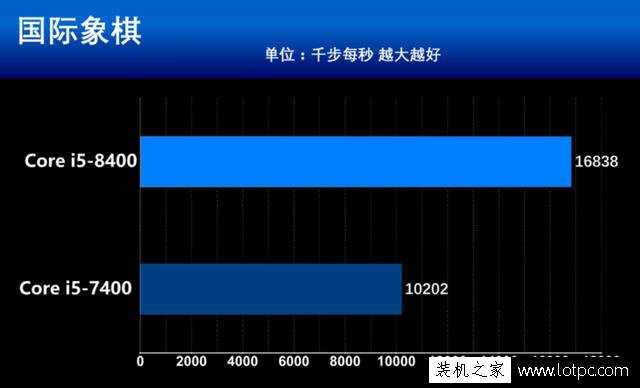
17���I5 7400��8400�ֶܷԱȣ����Կ���I5 7400 ����10202�����ַܷ����½�������֮һ��Ӣ�ض�������ô������������ȥ�� I5 7400 17�귢�����ۼ�$182.00 I5 2500K 11�귢�����ۼ�1400RMB��19���ۼ�170 ���뷭�룬��о��С����˵��о������ʲô�������ļ����ࣿ��?�Ž������ļ����� �����������ܾ����������ϴ���������Եú�û��ò�����ڻ�ͷ������û�������˿���ֳ�PK���������к����� ����Щ |
|
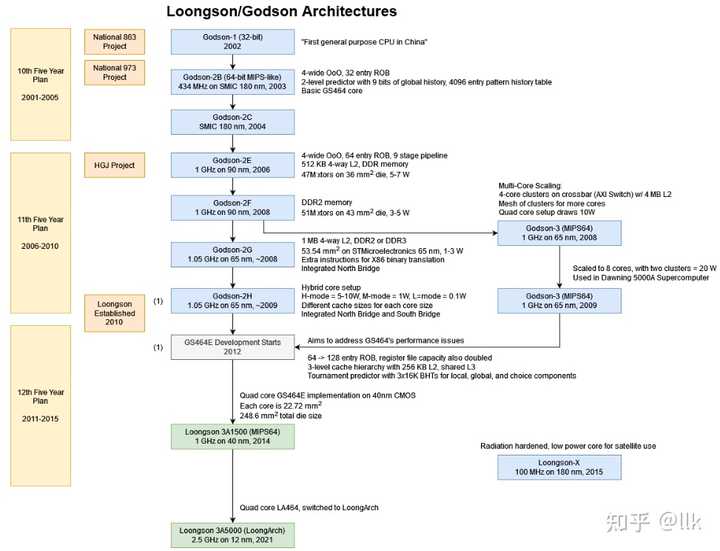
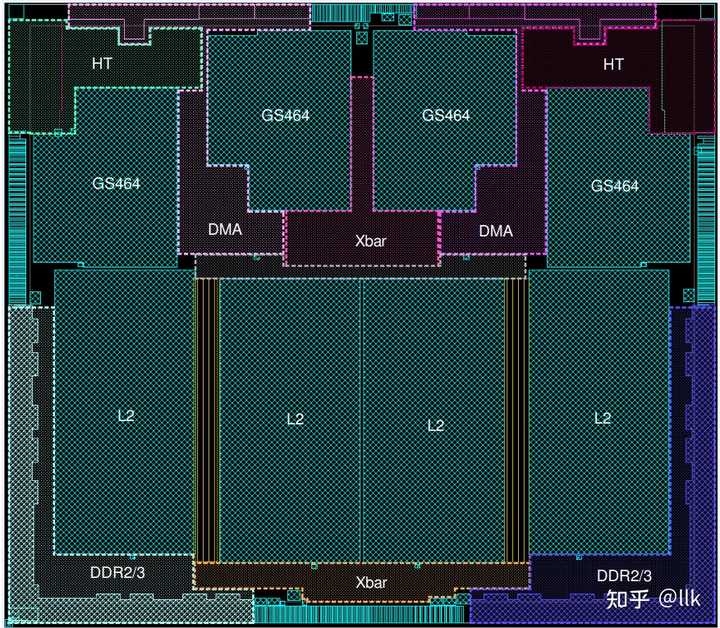
�������Ѿ����˺ܶྫ���������г����Լ�����ѡ������ҵ�ϵ�ԭ�������������ҵ���о��չ��ʷ���£����ԴӼ����Ƕȵõ�һЩ�𰸡� ǰ�� �������ϵͳ�Ե�ѧϰ�������˽�30����ļ��㼼����չ��ʷ�����и����������֮�������ģ�Ŀ���ж���һ����Ϊ֪ʶ������������ͬ�������ھ�ͬ�ܹ�֮���ԨԴ������ͨ�������ٴ�������ʷ����������δ����չ�����ҽ���ϵ������Ϊ����֪Զ, ��Ҫ��ע�����뻥���� ����Ϊ�ڶ�ƪ����Ҫ�ع���оϵ�С� 0. ���� ��о���ݼܹ��IJ�ͬ������ 3 ��������ϵ�С� ��оһ�ţ��������ѵ��Ӻ�Ƕ��ʽӦ�� ��о���ţ�����Ƕ��ʽӦ�ú͵����ܸ��˼�����ĵ��˴����� ��о���ţ����ڸ������ܼ�����������ܼ���ͷ������Ķ�˴����� ��о�������˰����ܹ�����Ϊ���࣬�ֱ��ǣ� ������32λ��132��GS132����Ӳ����Ƶ���Ļ���Ƕ��ʽ MIPS32 �ںˡ�3- (GS132) �� 5- (GS132E) ����ˮ�� ˫����32λ��232��GS232���߶�Ƕ��ʽ MIPS32 GS232 ����� 5 ����ˮ�ߣ�500MHz��16KB L1��GS232 ��Ҫ������оһ�Ų�Ʒ GS232E����� 10 ����ˮ�ߣ�1000 MHz��16KB L1��L2 = 4 MB ����������ִ�� �ķ���64λ��464�� GS464��������·����������ִ�е�MIPS64�ںˡ��������Դ����о2F������ GS464 ֧�� MIPS64 R2 + LoongMMI��2E �� 2F �е�������ͬ�汾�� GS464V �� 2010 ������о3B �״��Ƴ����Ǿ���ʸ�����ܵ� GS464GS464E�� GS464 �ĸĽ��汾����������Ļ�����õķ�֧Ԥ��� GS464EV �� GS464 ϵ�еķ�չ�����ȱ� 3A4000 ������ʹ�� ˫����64λ��264��GS264��MIPS64 �ںˣ���GS232��64λʵ�� ���⣬LA464 �� GS464�ķ�չ��֧�� LoongArch����ͼչʾ����о������Ʒ֮��̳кͷ�չ��ϵͼ�� |
|
|
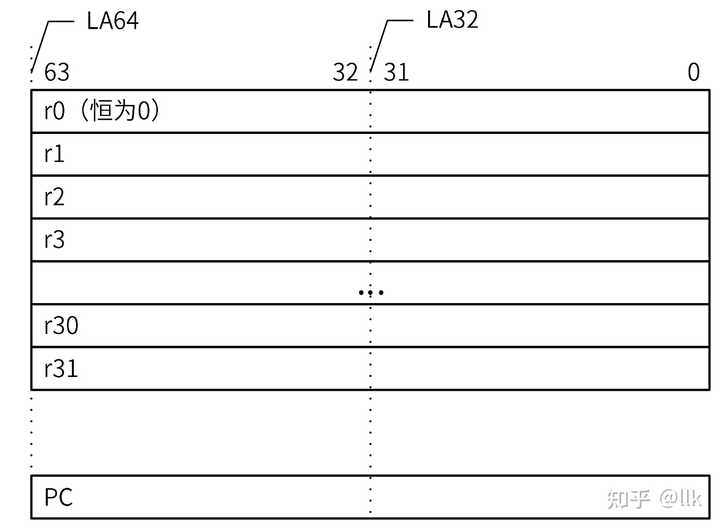
��о 1 ��Godson-1�ǵ���������32λ�����������й�������Ƶĵ�һ��ͨ�ô����� ��о 2 �� MIPS III ���� 64 λ������ϵ�С�����о 3 ϵ�й��� GS464�������ˣ���о 2�ķ�չ�滮�Ǵ�CPU��չΪSOC����о 2E (2006) ��һ�� CPU��2F (2007) �����˱��š�2F ������� GS464 ���ĵĻ��� 2009�����о 3A1000�ǵ�һ�������Ĵ�������ʹ�� 4 �� GS464 �ںˣ�65 nm���ա� ��о 3A1000 �ܹ��Խӽ� 1 GHz��ʱ���ٶ����У�������4 �� CPU �ںˣ�~15 W����Ȼ���� 8 ���ںˣ�40 W������о3B1500 2015 �꣬������ ��о3A1500 �� ��о3B2000��ʹ����ǿ�� GS464E �������ˣ��Ľ������ϵ�ṹ�ṩ�˸��õ����ܣ��ݱ����ٶ��� ��о3A1000 �� 3 �������һ������� LoongISA ��ǿ��ָ��� ��о3A1500 ����Ƕ��ʽӦ�ã��� ��о3B2000 ���ڷ������� PC 2017����о������о3A3000����о3A3000 �����ĺ� 64 λ��ƣ���ƵΪ 1.5 GHz�����Ľ�Ϊ 30 W 2019 ��ף������� ��о3A 4000 �� ��о3B 4000 ϵ�С�ʹ����������� GS464EV �ܹ���������������ĸ��ںˣ�8MB �� L3 ����� 1.8 GHz �� 2 GHz ֮��Ĺ���ʱ�� 2021��7�£���о3 5000ϵ�з�������ϵ�д���������о�������з���LoongArchָ��ܹ������� ��о3A5000��һ���ĺ�̨ʽ�� CPU �� 3C5000L��һ��ʮ���˷����� CPU�����ڵ�����װ�е��ĸ� 3A5000��ʹ��LA464�������� 2023��11�£���о�ٷ�������о3A6000ʹ����6����˫�̵߳�LA664�������� ������Ҫ��ע��о���ţ����ܹ���ҪΪ�ķ���64λ����GS464ϵ�С�������оָ��ܹ���ʷԨԴ��ο���һ����оָ��ܹ��Ľ��ܡ�����ͨ��ϵͳ�Իع�������оϵ�д���������ͼͨ����оϵ�д�������չ����ʷ���磬��չ�ֹ��ڴ�����������չ���̣��Լ������������������̵IJ��졣�±��ܽ��˸���������֮��Ĺؼ�ָ���� Godson-1Godson-2BGodson-2CGodson-2ELoongson 2FLoongson 2GLoongson 3A1000Loongson 3B1500Loongson 3A2000Loongson 3A3000Loongson 3A4000Loongson 3A5000Loongson 3A6000Date2001200320042006200820102009201520152016201920212023Core NameGS132NANAGS464r1GS464r1GS464r2GS464r2GS464VGS464EGS464EGS464EVGS464V/LA464LA664Technology0.18um0.18um0.18um90nmST 90nmST 65nmST 65nmSMIC 32nmSMIC 40nmST 28nmST 28nm12nm12nmTransistors4M15M15M47M51M100M425M1.14B8B8BArea(mm^2)NA41.541.5364354140182.5248.6(17.66x14.08)248.6(25.3x28.8)232147TDP(W)0.5NANA5-73-531530-6015405035Frequency(GHz)0.2660.250.4510.810.8-11.50.8-11.2-1.51.82.3-2.52.5No. Inst Decode1444444444444No. Inst Issue1444444444446COREs1111114844444ThreadsSTSTSTSTSTSTSTSTSTSTSTSTSMT2L1 CacheI$: 8K 2 way D$: 8K 4 wayI$: 64K 4 way D$: 64K 4 wayI$: 64K 4 way D$: 64K 4 wayI$: 64K 4 way D$: 64K 4 wayI$: 64K 4 way D$: 64K 4 wayI$: 64K 4 way D$: 64K 4 wayI$: 64K 4 way D$: 64K 4 wayI$: 64K 4 way D$: 64K 4 wayI$: 64K 4 way D$: 64K 4 wayI$: 64K 4 way D$: 64K 4 wayI$: 64K 4 way D$: 64K 4 wayI$: 64K 4 way D$: 64K 4 wayI$: 64K 4 way D$: 64K 4 wayL2 CacheNA8MB offchip8MB offchip512K 4 way512K 4 way1M 4 way4M 8 way128K/Core256K/Core 16 way256K/Core256K/Core256K/Core 16 way256K/CoreL3 CacheNANANANANANANA8M4M 16 way8M 16 way8M 16 way16M 16 way16M 16 wayIOPCIPCIPCIPCIPCIPCIHT 1.0 2x8@800MHzHT 2.0 2x16@3.2GHzHT 2x16@3.2GHzHT 2x16@3.2GHzHT 2x16@3.2GHzHT 2x16@3.2GHzHT 3.0 x16@6.4GHzMemory8-256M128bit 64M-2GDDRDDR2DDR2-333DDR2/3DDR2/3DDR2-800/3-1200 2x72DDR2-800/3-1333 2x72DDR2-800/3-1600 2x72DDR4-2400 2x72DDR4-3200 2x72DDR4-3200 2x72@42GB/sCommentsMIPS-III 32MIPS-III 64MIPS-III 64MIPS-III 64MIPS-III 64MIPS64MIPS64LoongISA 1.0LoongISA 1.0LoongISA 1.0LoongISA 2.0LoongISA 2.0 ���Է��֣���о�������ܶྫ��������ָ����ˣ��������������˵��ܹ����±Ƚϻ����� ������֯��ʽ����: ��һ�¼�����оָ��ܹ�LoongArch v1.02 �ڶ��½���Godson-1���ܹ����˽���о�����й��ĵ�һ����������� �����½���Godson-2��Godson-3A�Ĵ�������GS464�ܹ���������о������GS464Ϊ���� �����¼�����Loongson-3B1500 ����ܹ��Լ�֧����������Ĵ�������GS464V�ܹ� �����½���Loongson-3A2000�Ĵ�������GS464E���ܹ� �����¼��ܻ���GS464E��Loongson-3A3000����Ҫ�ǻ���Loongson-3A2000���˹������� �����¼��ܻ���GS464EV��Loongson-3A4000�� �ڰ��½��ܻ���LA464�������˵�Loongson-3A5000 �ھ��½���Loongson-3A6000��������г�����Ҫ�IJο�����1. LoongArchָ��ܹ� ��о��ָ��ܹ���Ϊ�����Σ� MIPS ��о�ڳ�ʼ��ʹ��MIPS64 ָ��ܹ�(ISA)��2009 �� 6 �£�ICT ֱ�Ӵ�MIPS��˾����� MIPS32 �� MIPS64 �ܹ������ɡ�2011 �� 8 �£���о�Ƽ�����˾�� MIPS ��˾��� MIPS32 �� MIPS64 �ܹ����ɣ����ڼ����������� MIPS ����о CPU �ں� LoongISA 2015����о3A2000����LoongISA 1.0��չָ����� MIPS64 �ij�����LoongISA ָ����Ϊ GS464E �ں˵�һ�������롣�������в��֣� LoongEXT��ͨ����չ��148 ��ָ�� LoongVZ��MIPS64 �汾 5 ������ġ�VZ��ϵͳ�����⻯��չ��5 ��ָ�� LoongBT������� x86 ��ARM�����Ʒ��룬213 ��ָ�� LoongSIMD��ԭ��LoongMMI������о2E/F����Ϊ128λSIMD��1014��ָ�� ���� MIPS �� 5 ��� MIPS SIMD �ܹ� (MSA)��DSP �� VZ ģ��LoongArch ������о 3 5000 ϵ�еķ�������о�� 2021 ��ת�����Լ��Ĵ�����ָ��ܹ�(ISA)��LoongArch ����һ���� 32 λ�汾��LA32R����һ������ 32λ�汾 (LA32S) �� 64 λ�汾 (LA64)�� LoongArch ISA �ֲ����� 2021 �� 8 �²��ֿ��ã����һ����¼�˻����ܹ�������LoongArch�ֲᣬISAʹ����MIPS����Ȩģ�ͺ�IRQ���ƣ��������ִ����ѭRISC-V��������ȥ���˷�֧�ӳٲۣ��ı���ָ����롣LoongArch ��ȫ�µ�ָ��������� MIPS ��������չ����������ָ�� 337 �����������չ 10�� �������Ʒ�����չ176 ����128 λ������չ 1024 ����256 λ������չ 1018 �������� 2565 ��ԭ��ָ������MIPS�������˲��ֲ��ʺ��ִ�CPU��ָ������˴����Ľ�����չ�����絥��ָ��֧�ֵ���������MIPS�����16λ��չ�����24λ����֧��תƫ��Ҳ��64K��չ��1M�ֽڣ��Լ�Ѱַ�ռ�ӹ̶��ֶθı�Ϊ��һƽ��ȣ�����Ч�����˱�������Ŀ��ָ�������ͷô�����������Ч�ܡ�LoongArch��ָ��ϵͳ�����ʱ�����Ƚ��ԡ���չ�ԡ�������ΪĿ�꣬���м�������ָ�ں�MIPS/x86/ARMָ��ϵͳ����Ҫ�ص㣬��Ч֧�ֶ����Ʒ��롣 1.1 �Ĵ��� LoongArch ΪRISCָ�����32��ͨ�üĴ�����32������/�����Ĵ���������r0��ֵΪ0��PC��ֵ�ǵ�ǰָ���ַ��ֻ�ܱ�ת��ָ��쳣������쳣���ؼ���ġ��Ĵ���������LA32����32���أ���LA64����64���ء� |
|
|
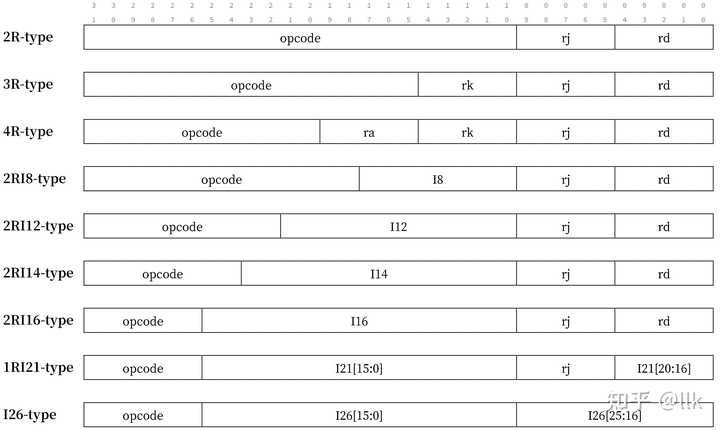
1.2 ����ģʽ ��о�ܹ���ΪLA32��LA64���ּ���ģʽ��LA64���Լ���LA32��Ӧ�ò�������������CSR.MISC.VA32L1/VA32L2/VA32L3���ƣ�����ЩֵΪ1ʱ��������PLV1/PLV2/PLV3���µ���������32λ��ַģʽ���С���ʱӲ�����ô������ַ��32λ����չ��64λ֮���ֵ��Ϊ�ô�ĵ�ַ�� 1.3 ָ���ʽ MIPSֻ��3��ָ���ʽ��LoongArch���������ָ���ʽ ��ʹ��32λ����ָ����õĸ�ʽ���9�� �������3������������ʽ��6������������ʽ��������Ƶ�ָ���ʽ�����������ָ��ۣ��������Ժ�ij�Զ��չ��ָ������ʽ���±���ʾ�� |
|
|
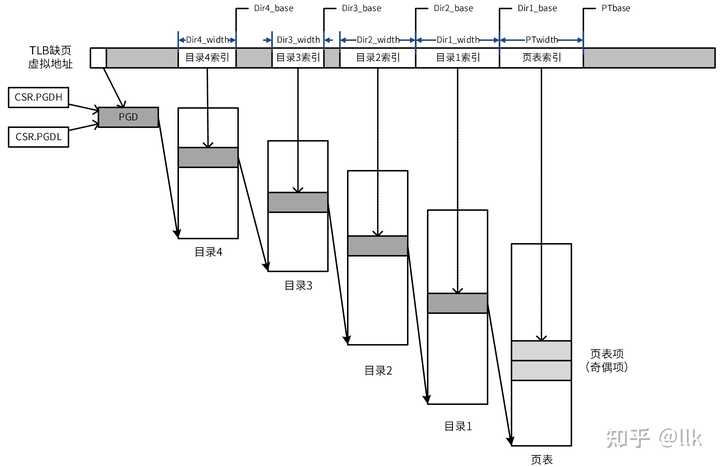
1.4 ��Ȩģ�� ��о�ܹ���Ϊ4����Ȩ�ȼ����ֱ���PLV0~PLV3����CSR.CRMD.PLV ȷ�������У�PLV0���������Ȩ�ȼ�������ʹ����Ȩָ�����������Ȩ��Դ��PLV1~PLV3��������ִ����Ȩָ��ͷ�����Ȩ��Դ����MMU����ӳ���ַ����ģʽ�¾��в�ͬ�ķ���Ȩ�ޡ� 1.5 �洢ģ�� ��о�ܹ��Ĵ洢һ����ģ�Ͳ�����һ����(Weakly Consistency)ģ�ͣ��������ʹ��ͬ��ָ���д������Ԫ�ķ��ʱ����������Ա�֤����д������Ԫ�ķ����ǻ���ġ��Էô��˳���������£� ͬ��ָ���ִ������˳��һ������������ͬ�����������д��������ж��ϸ��ճ���˳��ִ�У��ڵ�ǰͬ��ָ�����֮ǰ���ܿ�ʼִ����һ��ͬ������ ����һ�ô�ָ�ִ��֮ǰ����ָ��֮ǰ��ͬ��ָ���Ѿ���� ����һͬ��ָ�ִ��֮ǰ����ָ��֮ǰ�ķô�ָ������ ��о�ܹ���֧�����ִ洢�������ͣ���ҳ����MAT(Memory Access Type) �������ֱ���: һ�¿ɻ���(Coherent Cached) ���ʶ������������Ҳ�����ǻ��� ǿ��ǻ���(Strongly-ordered UnCached) �ϸ��ճ���˳��ִ�� ����ǻ���(Weakly-ordered UnCached) ������Ͷ��ִ�У�д���Ժϲ�1.6 �ڴ���������⻯ ��о�ܹ�MMU��ַ������CSR.CRMD���ƣ� ��CSR.CRMD.DA=1 && CSR.CRMD.PG=0ʱ�������ַ����������ַ ��CSR.CRMD.DA=0 && CSR.CRMD.PG=1ʱ�������ַ��Ҫ�������룬���Է�Ϊֱ��ӳ���ҳ��ӳ��1.6.1 ֱ��ӳ���ַ����ģʽ ����ͨ������CSR.DMW0~CSR.DMW3�Ĵ������ֱ������ĸ�ֱ��ӳ�����ô��ڣ�ǰ����ͬʱ����ȡָ�ʹ洢����ָ�������ֻ�����ڴ洢����ָ� ��LA64�ܹ��£��������ַ���4λ[63:60]�����ô��ڼĴ����е�VSEG���������Ȩ�ȼ�ƥ��ʱ��������ַ���������ַ��[PALEN-1:0]�� ��LA32�ܹ��£�ÿһ��ֱ��ӳ�����ô��ڼĴ�����������һ��$2^{29}$�ֽڹ̶���С�������ַ�ռ䣬�������ַ�����3λ[31:29]�����ô��ڼĴ����е�[31:29]�������Ȩ�ȼ�ƥ��ʱ��������ַ���������ַ[28:0]ƴ����ӳ�����üĴ������õ�������ַ��λ�� 1.6.2 ҳ��ӳ�� ��о�ܹ���TLB�������Լ�TLB���ڴ�ҳ����һ����ά��ȫ����Ҫ������ɣ��༶ҳ���ṹ������ʾ�� |
|
|
������ҳ��ʱ��PGD�������ַ$PALEN-1$������ ��VA[PALEN-1]=0ʱ��PGD����CSR.PGDL ��VA[PALEN-1]=1ʱ��PGD����CSR.PGDH ҳ�����ʽ���±���ʾ�� |

|
|
1.7 �쳣���ж� �쳣���жϻ��ϵ�ǰ����ִ�е�Ӧ�ó����л����쳣�жϴ���������ڿ�ʼִ�У��쳣���ж����ڼܹ�����Ȩ��Դ�������֣�������Ҫ���ܳ���һЩ�쳣�� ϵͳ�����쳣 ִ��SYSCALL ָ��� �ϵ��쳣 ִ��BREAKָ��� ָ������쳣 ��ִ�е�ָ�����δ����ʱ���� ��Ȩָ����쳣 �ڷ���Ȩģʽ��ִ����Ȩָ��ʱ���� ��ַ���쳣 ��ȡָ��ô�ָ��ĵ�ַ���ַַ����ʱ���ֱ�ᴥ��ȡָָ���ַ���쳣��ô�ָ���ַ���쳣 ������쳣 ������ָ������ݳ����쳣�����Ҫ�����ʱ����1.7.1 �쳣���жϴ��� TLB�����쳣����ڵ�ַ��CSR.TLBRENTRY, ���������쳣�������CSR.MERRENTRY�������쳣��Ϊ��ͨ�쳣����ڵ�ַ����$���ҳ�� | ҳ��ƫ��$ ��������ͨ�쳣�����ҳ�Ŷ���CSR.EENTRY ����ҳ��ƫ�����ж�ƫ��ģʽ���쳣��(ecode)��ͬ����������$2^{CSR.ECFG.VS+2} * (ecode+64)$ ���жϱ�������ͨ�쳣���������ʹ����ͨ�쳣����ڼ��㷽ʽ�������ǣ��ж϶�Ӧ���쳣���Ƕ�Ӧ�жϺż���64���쳣ecode���±���ʾ�� |
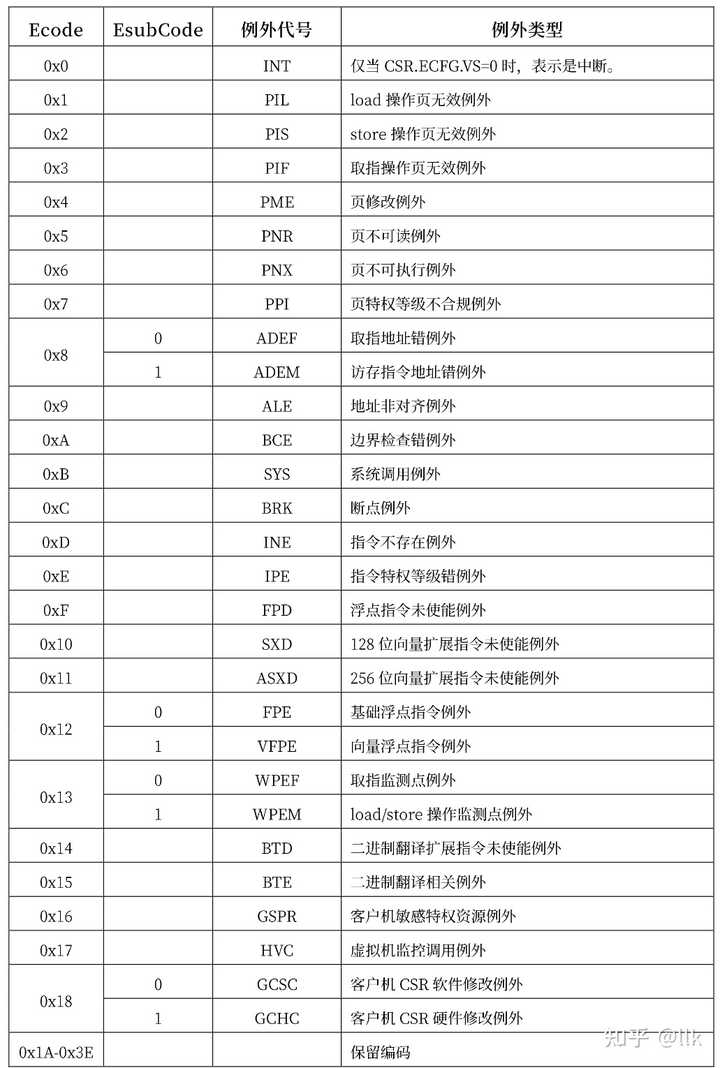
|
|
�����쳣��ָ��ĵ�ַ�ᱻ��¼��ERA���Ϊ�쳣���ص�ַ�����ڵ�ַ������ص��쳣�������ĵ�ַ�ᱻ��¼��BADV�������쳣��ָ��ᱻ��¼��BADI� 2. Godson-1 ��о��һ�������о1�������2001�꣬2002�귢������һ��32λ����������ִ��CPU����Ƶ266MHz��ѧ�������ϴ�����Godson-1�����й���ѧԺ֪ʶ���¹��̷�������Ŀ����ҡ��������������о���չ�ƻ���Ŀ���о��ɹ��������� 0.18 �� CMOS �������죬���� 8 KB L1D��8 KB L1I ��һ�� 64 λ���㵥Ԫ���ܹ��ﵽ 200 ˫���� MFLOPS����ͼչʾ��Godson-1�������滮��ͼ�� |
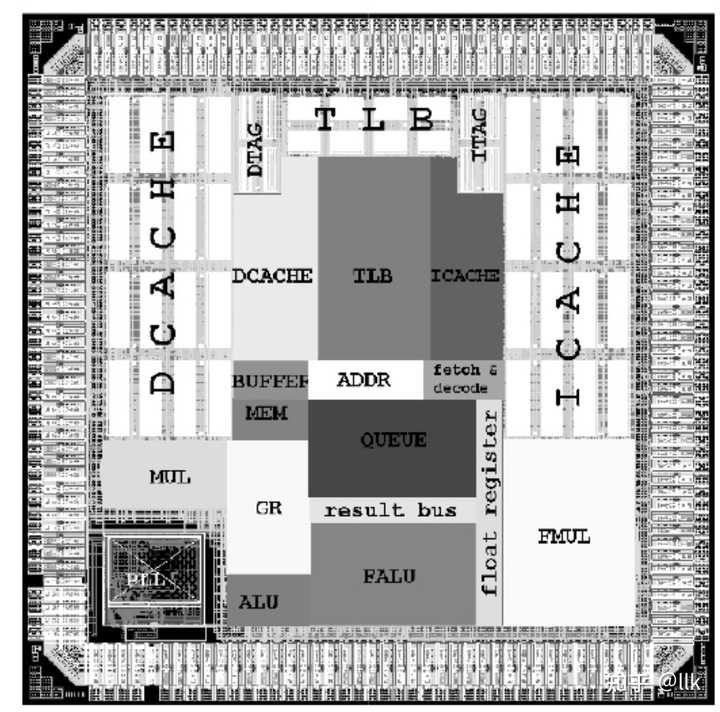
|
|
��о1��ʵ�ֻ��ڲ������и��õļĴ�������������������Tomasulo�㷨���ж�̬���ȣ���֧Ԥ��ʹ�þ�̬Ԥ�⣬��ÿ�ζ�Ԥ���ִ֧�С���Ҫ��ȡֵ��Ԫ�����뵥Ԫ���������У��������Ĵ����ļ��Ͷ��㸡��ִ�е�Ԫ��ɡ���ͼչʾ��Godson-1���ܹ��� |
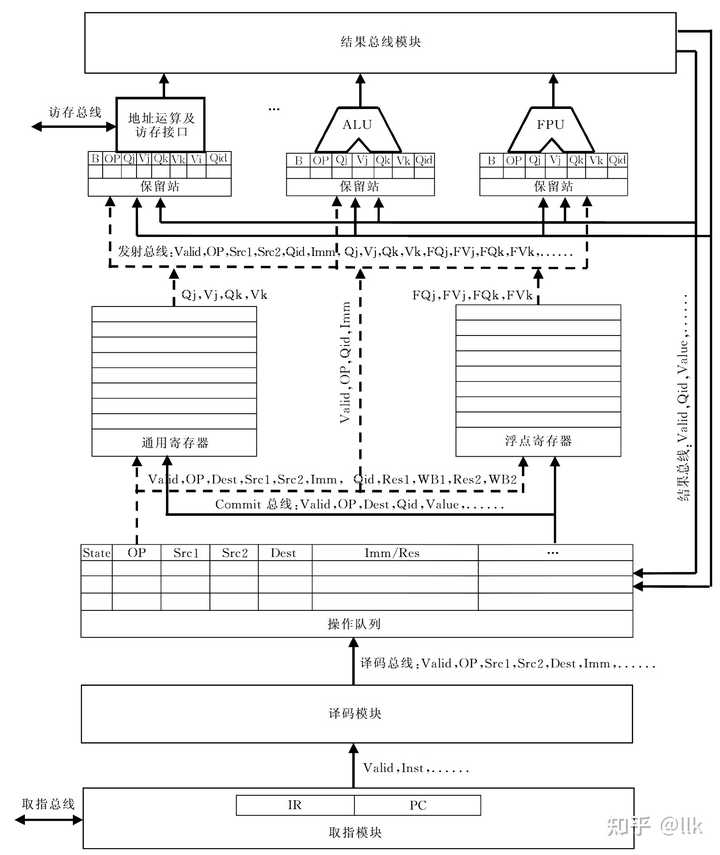
|
|
ָ�����뵥Ԫ������˳�������ָ��ַ����������У��������и���ָ�����ͷ��䵽��Ӧ�ı���վ������������Ѿ���ɵ�ָ�����վ�е�ָ���ִ�е�Ԫ֮���д�ص��������кͽ�����ߡ����ָ���ʱԴ��������û�����ã���������ָֹ��ķ��䣬����ͨ���������кŽ���ָ��������������ϵ�����䵽����վ������վ�Զ��������߽������������Ҫ��ֵ������������£� ָ������������ʱ����ָ��ĵ�Դ�Ĵ���������������е�ÿһ��ָ���Ŀ��Ĵ����Ž��бȽϣ��õ����������������д�üĴ�����ָ���λ��Qid ָ���ʱ���Qid��ֵ������Ѿ�д�ص�����������ֱ�Ӷ���������Qid�͵�����վ����¼ֵδ���� ������վ�����в����������ú�ʼ���㲢�ѽ���͵�������ߣ���Ӧ�������кͱ���վ ָ����ˮ�߷ֳ�ȡֵ�����룬�����������䣬ִ�У�д�أ���ɵȽΣ�����ִ�нο�����Ҫ���ģ��������£� ȡֵ ���ݵ�ǰ���������PC��ָ��ӻ������ָ��Ĵ���IR����ָ֧��쳣����£���һ��ָ���PCΪ��ǰָ���PC+4 ���� ����IR�е�ָ��������벢д��������У��������������������ˮ����ͣ ������ ��ָ��ĵ�Դ�Ĵ���������������е�ÿһ��ָ���Ŀ��Ĵ����Ž��бȽϣ��õ����������������д�üĴ�����ָ���λ��Qid ���� �Ӳ���������ѡ��һ��ָ����䵽��Ӧ�ı���վ�����ָ��Դ�����������ã�����Ҫ����վ��¼ֵδ���� ִ�� ִ�е�Ԫ�ӱ���վ��ȡ������Դ�����������õ�ָ��������㣬���������ָ���ڲ�������λ�ñ���͵�����Ĵ��� д�� �ѽ���Ĵ�����ֵ�Լ���Ӧָ���ڲ�������λ�ñ���͵�������ߣ�����վ�Ͳ�����������������ߵ���Ϣ����������Ӧ״̬ ���� ������������еĵ�һ��ָ���Ѿ���ɣ��������ָ�������������Ľ��д�ص�Ŀ��Ĵ�����������������еĵ�һ��ָ����ִ�й����з����쳣��������쳣����3. Godson-2 �� Godson-3 ��о2F��2007��7��31����Ƭ�ɹ���90�����գ�4��������ִ�У���� $43mm^2$ ����о2F����о��һ��ɹ������ô���������ͼչʾ��Godson-2E�������滮ͼ�� |
|
|
��ͼչʾ��Godson-2F�������滮ͼ�� |
|
|
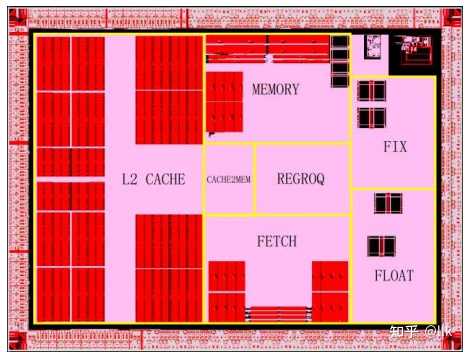
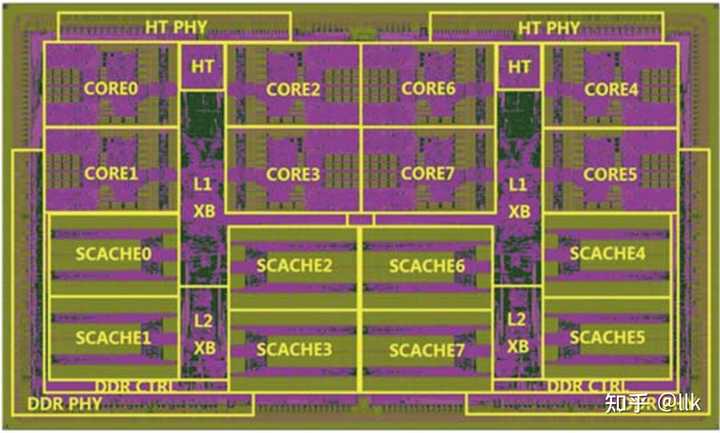
��о2G���ڡ���о��ȫ���ü����CPU������Ӧ�á��˸��ش�ר�����֧�����з��ģ�2008�꿪ʼͶ����ƣ�2010�����Ƴɹ�����о2G����65�����գ���Ƶ1.0GHz���������Ŀ1�ڣ�ָ�����MIPS64����������X86�����Ʒ������ָ��Լ���оý����չָ���64KB��ָ���64KB���ݵ�L1���棬�Լ�1MB��L2���棬����3W���ڸô������ϣ�ʹ����X86�����Ʒ��뼼�����������MIPSƽ̨��ʵ��X86��̬�����Ʒ���ķ�������о2G�൱����о3A1000�ĵ��˰汾����о3A1000��2008�������Ƭ,�����ⷨ�뵼���65nm������Ƭ����Ƶ800MHz-1GHz����о3A1000�����˵�һ�θİ沢��2010��5����Ѯ��Ƭ��10�µ�һ�θİ���Ƭ�ɹ���3A1000�ĵڶ��θİ���2012��2����Ѯ��Ƭ��2012��8����Ѯ��Ƭ�ɹ��� ��о3A1000������4���ķ�������ִ�е�GS464�ˣ�9����ˮ�ߣ���64KBһ�����ݻ����64KBһ��ָ��棬4MB�����������棬�����Ƶ1GHz������15w��֧�ֶ�̬��Ƶ����оƬ��� $174mm^2$ ���������Ŀ4.25�ڡ�ÿ��CPU�˰�����������˼Ӳ�����˫���ȸ������ܷ�ֵΪ16GFlops������о3A1000�������У�ʵ����x86�����Ʒ������ָ�3A1000������PCI��������LPC��SPI��UART��GPIO��2��HT1.0������72λDDR2/3����������ͼչʾ��Godson-3A1000�������滮��ͼ�� |
|
|
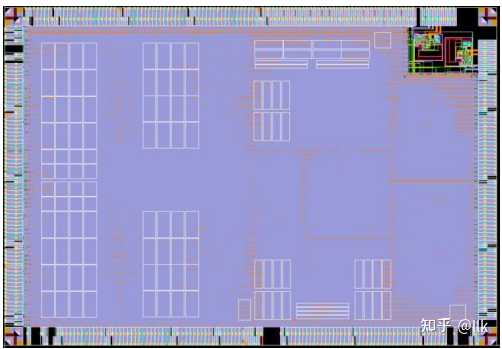
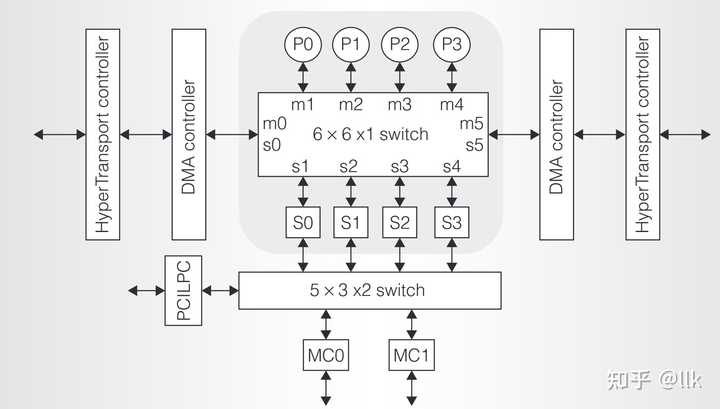
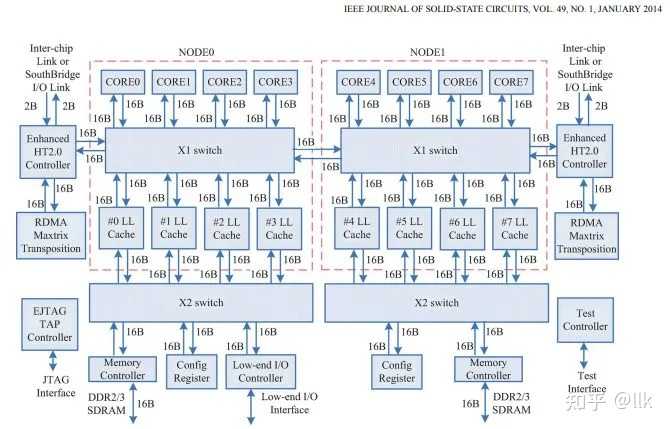
��о3A1000��һ����������6x6�Ľ��濪�أ�����4���������ˣ�4����������ģ�������IO�˿ڵ����ӡ��ڶ�����������5x3�Ľ��濪�أ�����4�������Ļ���ģ�飬�����ڴ��������һ��IO�˿ڡ���ͼչʾ����о3A1000����ܹ��� |
|
|
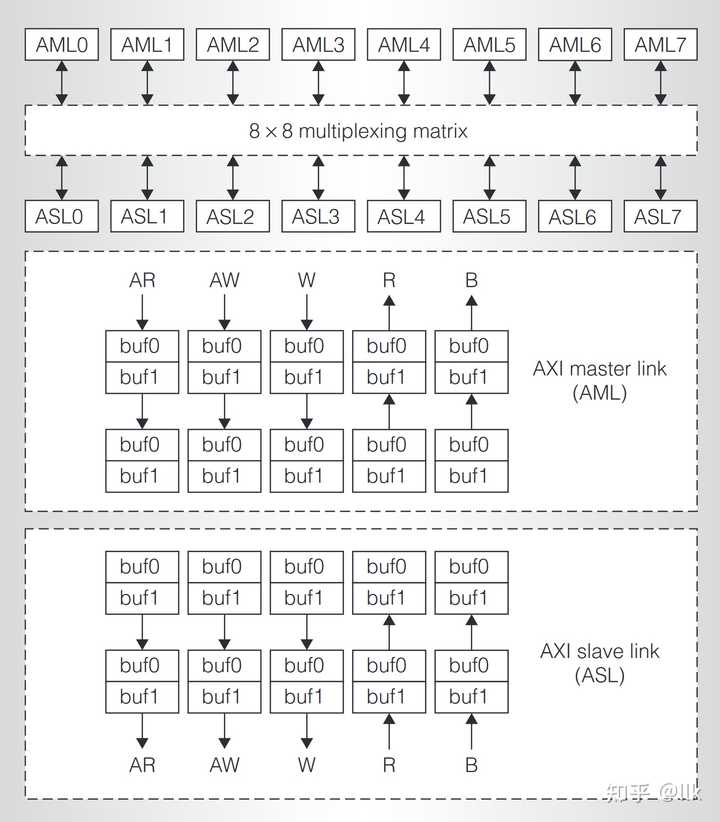
��ͼչʾ��һ��8x8���滥���ļܹ��� |
|
|
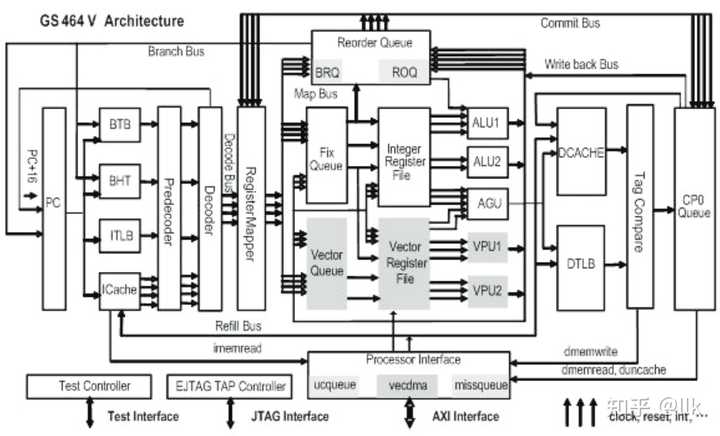
8��AXI master link(AML) �� 8��AXI slave link(ASL) ͨ��һ�����濪�ؽ��л�����AML ʹ�ö�д����ĵ�ַ��Ϣ����·�ɣ���д����8����ַ���䣬��ӦASL��ASLͨ����Ӧ�����AML �˿ںŽ���д��Ӧ·�ɵ���Ӧ��AML��AML��ASL����������ˮ�����Խ��滥��һ����4�������ӳ١� 3.1 GS464�ܹ� ��ͼչʾ��GS464���ܹ��� |
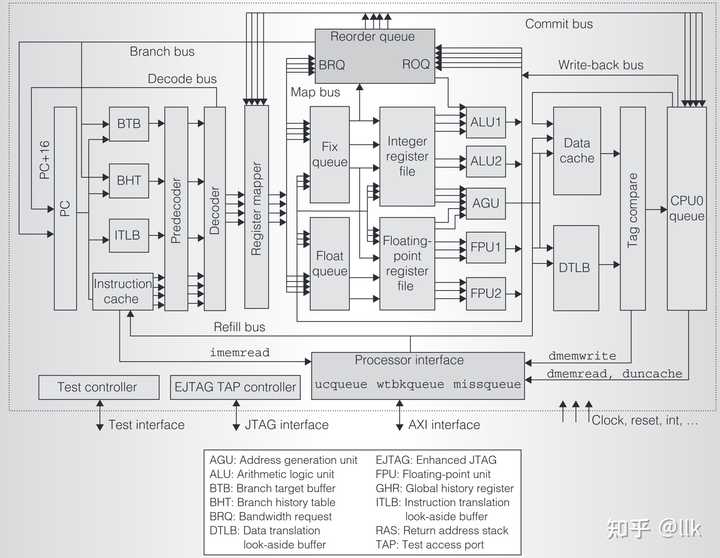
|
|
ָ����ˮ�߷ֳ�ȡֵ�����룬�����������䣬ִ�У�д�أ���ɵȽΣ�����ִ�нο�����Ҫ���ģ��������£� ȡֵ ���ݵ�ǰ���������PC��ָ��ӻ������ָ��Ĵ���IR����ָ֧��쳣����£���һ��ָ���PCΪ��ǰָ���PC+16 Ԥ���� ��ָ��ɨ�裬ʶ�����ָ֧������֧�������Ԥ�� ���� ����IR�е�4��ָ��������벢�͵��Ĵ���������ģ�� ������ ���ܹ��Ĵ���ӳ�䵽�����Ĵ����� �ַ� �Ĵ���������֮���ָ��ַ�������㱣��վ�Ա�ִ�У�ͬʱ�͵��ض�������Ա�˳����ɣ���֧�ʹ洢����ָ��ַ�����Ӧ�ķ�֧���кʹ洢���ض��С�����վ�ͷ������ÿ��ɱ���ַ�4��ָ�� ���� �ӱ���վ��ѡ�������������������ϵ�һ��ָ����͵���Ӧ��ִ�е�Ԫ�����ָ��Դ�����������ã������������ǰ������ ִ�� ִ�е�Ԫ�ӱ���վ��ȡ������Դ�����������õ�ָ��������㣬����������͵������ǰ������ ���� ÿ���ڿ����4��ָ���ɵ�ָ��Ľ�������͵��Ĵ���ӳ��ģ���Ա���¼ܹ��Ĵ���ͬʱ�ͷ���Դ3.1.1 ȡָ�ͷ�֧Ԥ�� GS464���� 1 ��4 ·������ 64 KB ��ָ���, �仺���д�СΪ 32 �ֽ�, ָ���ı�ǩ�����ݲ���ͬʱ���ʲ�����һʱ�����ڽ������е��ж���ѡ���������ݲ��ֻ���Ϊ 8 ��bank��ÿ��ȡָ��ʱֻ�ö�ȡ����Ҫ��bank, �����˻������ʱ�Ķ�̬���ġ�ָ���ʹ�����ַ������ʵ��ַ��ʶ������������ȡָ��������ʵ��ַת��ͨ�� 16 ��ȫ�����ṹ��ָ�� TLB ���, ָ�� TLB �е�������ҳ�����Ӽ�������, ÿ���� 1 ��ҳ����, ÿ��ҳ�������֧�� 4 KB-1 GB ֮�䲻ͬ��С��ҳ����ָ�������ʱ, ȡָ����ÿ��ʱ�����������Դ�ָ�����ȡ�� 4 ��ָ��, �������� һ����ˮ�����з�֧Ԥ��. ����ָ���δ����ʱ, ȡָ���������������ʻ���ʧЧ����, �ô�ʧЧ���и�����л���ȱʧ����, ����������ظ�ָ��档�ӻ���ʧЧ�ӷ��صĽ�����������ָ��棬 ָ����������� 3 �������в�����, ���� 3 ��δ��� (outstanding) �Ļ����в�����ʱ, ���ɿ��Դ���ȷ�ĵ�ַȡָ���ȡָ����ǡ�����ڴӻ���ʧЧ���з��صĻ�������������ʱ, ����ֱ��ȡ����Ӧָ�������һ����ˮ������ ��, ָ����Ԥȡ�ɻ���ʧЧ�����е�Ӳ��Ԥȡ����ͳһ���, ����ȡָ�����е������С�ָ�������ݲ����л�����Ԥ������Ϣ, ÿ��ָ���Ԥ������ϢΪ 8���ش�С, ��Ҫ����ָ���з֡���֧�����ж��Ͳ���ָ��������ж���Ԥ������Ϣͨ���ڻ���ʧЧ��������ָ���ʱ����ó�, ���洢��ָ����С� ��Ԥ����Σ���ɨ��IR��4��ָ���еķ�ָ֧�Ԥ���֧����ͷ�֧Ŀ�꣬branch-like �� jump ָ������Ԥ��ִ�У�����������ָ֧���ʹ�÷�֧��ʷ��(BHT)��Ԥ���֧����ʹ�÷�֧Ŀ�껺��(BTB)�ͷ��ص�ַ��ջ(RAS)Ԥ���֧Ŀ���ַ��BHT��9����ȫ����ʷ�Ĵ���(global history register) GHR ��4Kģʽ��ʷ��(pattern history table) PHT��ɣ�PHT��ÿ����2���صı��ͼ���������λ���ڷ�֧����Ԥ�⡣BTB��16�ÿһ����ָ���ַ����תָ��Ŀ���ַ�Լ�2���ر��ͼ�������ɣ�������ֵΪ0��1�������ȱ��滻��RAS��4�������branch and link ָ��ʱ������ǰָ���ַ��8�ƽ�RAS��������jump register 31 ָ��ʱ��RAS�е���ָ���ַ�� ������Σ�4��ָ����벢�͵��Ĵ���������ģ�顣 3.1.2 �Ĵ��������� GS464ʹ�úϲ��ļܹ����������Ĵ����ѣ��������ֱ���64���Ӧʹ��64���PRMT(physical register mapping tables)��ά���ܹ��������Ĵ���֮��ӳ���ϵ��PRMTÿ�����: ״̬ ÿ�������Ĵ�����������״̬֮һ��MAP_EMPTY��MAP_MAPPED, MAP_WTBK, MAP_COMMIT ���� �����Ĵ�����Ӧ�ļܹ��Ĵ�����ʶ ��Чλ �����������Ĵ���ӳ�䵽һ���ܹ��Ĵ��������ʶ���µ� �Ĵ���������ʱ����Ҫ����PRMT���ҵ�����Դ�Ĵ���src1,src2��Ŀ��Ĵ���dest ��Ӧ������ӳ��������Ĵ���psrc1, psrc2��odest�����⣬һ������MAP_EMPTY�������Ĵ���pdest��ӳ�䵽dest����״̬��ΪMAP_MAPPED����Чλ��1��odest��Чλ��0��֮��ӳ��������Ĵ������͵�����վ��odest�������ض�������Ա�ָ�����ʱ�ͷ������Ĵ�������ָ��ִ�����ʱ����Ӧ��PRMT��״̬����ΪMAP_WTBK, ָʾ��������ָ��IJ����������ˡ���ָ����ɺ�pdest��״̬����ΪMAP_COMMIT��odest����ΪMAP_EMPTY�� 3.1.2 ָ��� GS464����������վ���ֱ��Ƕ���ʹ洢���ر���վ���㱣��վ��ÿ������վ��16�ÿ���ڿɽ���4��ָ�ÿ�����һ��������ָ����뱣��վʱ���ó���Сֵ����ͬһ�����ܵ�Ԫ����ָ�����ʱ����ָ���ֵ��һ���ӱ���վ��ѡ�������������������ϵ�һ��ָ����͵���Ӧ��ִ�е�Ԫ�����ָ��Դ�����������ã������������ǰ������ ���ڷ�ָ֧����˷��͵�����վ���ض������֮�⣬��������֧���У�ÿ���ڿɽ���һ����ָ֧�ͬʱ��ౣ��8����ָ֧�����ָ֧��ִ��ʱ�����д�ص���֧���У�����JR��JALRָ��ĵ�ַ��������֧�ķ�֧�����Լ�Ԥ���Ƿ���ȷ��ÿһ��ָ������һ��brqid�����ڷ�ָ֧�ָʾ�ڷ�֧���е�λ�ã���������ָ���ʶ�˸�ָ��ǰһ����ָ֧���λ�á�����֧Ԥ�����ʱ���÷�ָ֧��֮���ָ��ᱻȡ���� 3.1.3 ָ����� �Ĵ���������֮��ָ����������ض�����У�ֱ��ָ����ɡ���ָ��ִ�н�����д�غ��ض�����а��ճ���˳����ɣ��ض������һ�����Ա���32��ָ�ÿ���ڿɽ���4��ָ��½����ָ���ROQ_MAPPED״̬����ָ����д��ʱ���ڷ�ָ֧�״̬����ΪROQ_BRWTBK������ָ������³�ROQ_WTBK�����ڷ�ָ֧�ֻ�з�֧���ȷ���Ҷ���Ԥ�����ķ�ָ֧���ˢ��ˮ��֮��Ż���³�ROQ_WTBK����ָ����ض�����ж�ͷ�Ҵ���ROQ_WTBKʱ�ſ��Խ�����ÿ���ڿ����4��ָ���ָ�����ʱ��pdest��odest���͵��Ĵ���������ģ���Ա���´������ܹ�״̬���ͷ�odest����ڲ����쳣��ָ�Ҳ����ָ����ͷʱ������ 3.1.4 �ô���� GS464��64K��ָ�������ݻ��棬����4·��������64���TLB��Ϊȫ�����ṹ���ô����һ����16������Ը���16���洢����ָ�������ָ��������ʱ���������и��ϵĴ洢ָ����洢ָ��������ʱ���������и�����ļ���ָ� 4. Loongson 3B1000��3B1500 ��о3B1000�ɺ˸���Ŀ���⡰�����ܶ��CPU�з���Ӧ�á�֧�֣������ⷨ�뵼��65��������ƣ���Ƶ1GHz������25W��Ƭ�ڼ���8��64λ�ķ�������ִ����о������������GS464V��4MB�Ķ������棬ÿ���˰�������256λ������������ֵ�������ܴﵽ128GFLOPS����о3B1000�������ɫ����о�����������˵���ƣ��ô������˽�GS464�˵ĵĸ��㲿������Ĵ������滻Ϊ2��256λ����������������1��128x256λ�������Ĵ����ѣ�ʹ��о3B��1GHz�µķ�ֵ˫���ȸ�����������ﵽ128GFlops������о3B1000�������У�ʵ����300����ר�õ���������ָ���о3B1000оƬ��� $300mm^2$ , �������Ŀ�ӽ�6�ڡ� ��о3B1500������8���ķ�������ִ�е�64λGS464V�������ˣ�9����ˮ�ߣ�ÿ������������64KB��˽��һ��ָ����64KB��˽��һ�����ݻ��棬128KB˽�ж������棬��8MB�����������棬������о����32������������оƬ��� $180mm^2$ , �������11�ڣ���Ƶ1.5GHz����оƬ˫���ȸ�����������ﵽ192GFlops������30w�����ͣ�/60w���������� ��2��HT2.0��PCI��LPC��SPI��UART��GPIO��72λDDR2/3����������о3B1500��2���������ڵ���ɣ�ÿ���������ڵ���4��GS464V�������ˣ������������ڵ�֮��ͨ�����濪�ػ�������ͼչʾ����о3B1500 ����ܹ�ͼ�� |
|
|
��ͼչʾ����о3B1500������ͼ�� |
|
|
4.1 GS464V�ܹ� GS464V��32nm���������Ϊ $6.6mm^2$ ��������256���ص�����������Ԫ��ÿһ������ִ��4��˫���ȵij˼����㣻������һ��128���ص�AXI�ӿڡ���ͼչʾ��GS464V�������滮ͼ�� |
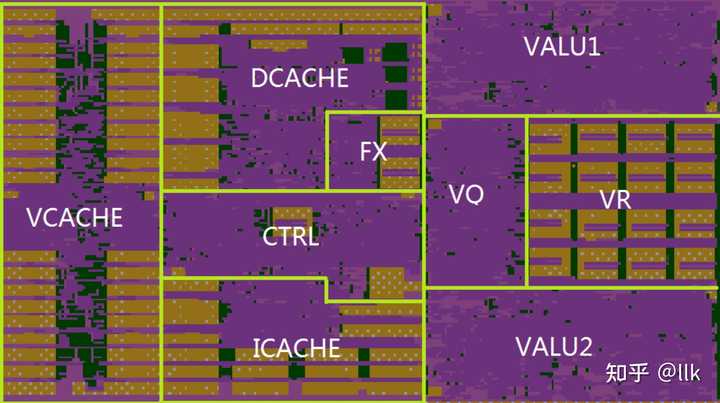
|
|
��ͼչʾ��GS464V���ܹ�����GS464��������Ǹ��㵥Ԫ������������Ԫ��������ˮ�߶���һ���ġ� |
|
|
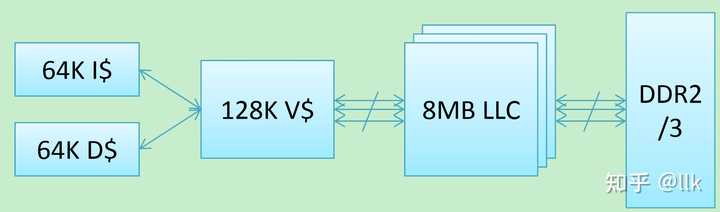
4.2 �洢��� ��о3B1500 ÿ��GS464V������������4·������64KB��ָ��棬4·������64KB�����ݻ��棬�Լ�4·��������Ϊvictim�����128K��L2���棻8��GS464V�������˹���8MB��L3���档 |
|
|
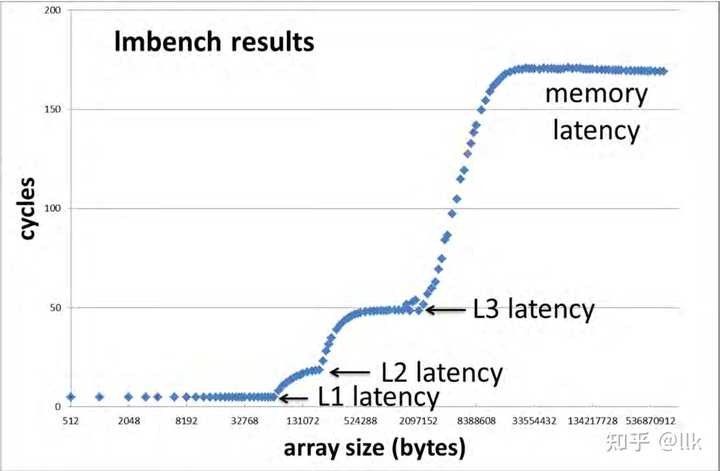
��ͼչʾ�˸����洢���Ե��ӳ٣� |
|
|
5. Loongson 3A2000 ��о3A2000������������4���ķ�������ִ��64λGS464E�������ˣ�Ҳ�������GS464E�ṹ�Ĵ������� ������о����40����CMOS������������Ƶ800��1000MHz GS464E����������GS464�ĸĽ��棬������64KBһ��ָ��棬64KBһ�����ݻ��棬256KB���������4MB�������档��ˮ�ߴ�GS464��9����ߵ���12������ֵ��������16GFlops���ڽӿ��ϣ���о3A200����������HT3.0�ӿڣ�PCI��������LPC��SPI��UART��GPIO��72λDDR2/3-1333��2�������� 5.1 GS464E�ܹ� ͨ������IBM POWER7�ȴ�������GS464E�����֮ǰ�� GS464 �ܹ�, �ص�ǿ���˷ô����ܺͷ�֧Ԥ��ȷ��, ʵ���� MIPS DSP ָ ��������֧��, �����˴������и�����е�����, �������˻��������� TLB �������ô���ϵͳӵ�� 3 ������ṹ, ÿһ�������� LRU �滻����, ����֧�ֶ�˻���һ����Э�顣��ͼչʾ��GS464E�������滮ͼ����Ҫ��ȡָ��Ԫ���Ĵ�����������Ԫ�����㵥Ԫ�����㵥Ԫ���ô浥Ԫ��L2�������ɡ� |
|
|
��GS464��ȣ�GS464E ����������Ҫ����: ȡָ��Ԫ ȡָ��Ԫ�Ĺ�����ͨ����֧Ԥ��������ָ����, ������ָ������. �� GS464E ����������, ͨ���������, �����˷�ָ֧��Ԥ����ת���ȡָ����; ͨ������ѭ�������� (loop buffer), ʹ����� 56 ��ָ����ɵ�ѭ������ִ��ʱ�������ָ��� �Ĵ��������� �Ĵ��������������Ĺ����ǽ��и��ּĴ�����������, ���ڶ�̬��ˮ���е������䡣GS464E ���������еļĴ�������������չ�� 128 ��������Ĵ����� 128 ��������Ĵ���, ����, DSP ���ƼĴ�����HILO �Ĵ����Լ�����ȽϽ���Ĵ������������������� ָ���ض��� ָ���ض���Ԫ�Ĺ����ǽ��������ָ������ض���, �����з�֧Ԥ�����ָ���쳣�Ĵ���. ָ���ض������ (reorder queue, ROQ) �� 64 ������ 128 ��; ��ָ֧����д� 8 �� ���� 24 �� ���㵥Ԫ ���㵥Ԫ���ڽ��ж������. �� GS464E ����������, ͨ�������ļ�������ǰ���� (forward) �����, ���ڼĴ���������ص� 2 ������ָ��֮����ӳ� (load-to-use) �� 2 ��ʱ�����ڼ��ٵ��� 1 ��; ��������������źŴ��� (digital signal processing, DSP) ���ܵ�Ԫ ���㵥Ԫ ���㵥Ԫ���ڽ��и������. ����ȽϽ���Ĵ������ڿ��Ե�������������, ��˸���Ƚ��Լ�ʹ�ø���ȽϽ����ָ�����������Ͷ�̬��ˮ �ô浥Ԫ �ô沿�����ڴ����ô�ָ��. �ô�ָ��ר�÷�����д�СΪ 32 ��, ���Խ��ô�ָ�������䵽 2 ���ô湦�ܲ���, ÿ�����ܲ�������ִ�ж�ȡ (load) ��洢 (store) ָ��; �ô��ض�����е������� 24 �������� 64 ��. һ�����ݻ�������� LRU �滻����, ���� �����д�С��չΪ 64 �ֽڳ�. ��ַ������ٲ��ұ� (translation lookaside buffer, TLB) ������Ҳ�д������, ������ 64 ��ɱ��Сҳ��� 1024 ��̶���Сҳ��˫�� TLB ��� ����ʧЧ���� ����ʧЧ������ָ���ʧЧ���������ݻ���ʧЧ����������, ���ڴ�������ʧЧ���������. �� GS464E ����������, �������� 8 �������� 16 ��, ��ʵ���˼�����ָ�������Ԥȡ����, ��Ԥȡ�������ݻ���ʧЧ�����е���Ϣ�Զ�����Ԥȡ����, ��ͨ������ʧЧ������������ЩԤȡ����. ��Ԥȡ���Ʋ��ᵼ��һ��������Ⱦ Victim Cache Victim Cache ��Ƭ�ڵĵڶ�������, ��һ������ʧЧʱ����ѯ. �� GS464E ����������, ������������Ϊ 256 KB, �����ṹ�� 8 ·��������Ϊ 16 ·������, �������� LRU �滻����, ����� Victim Cache �������� ��ͼչʾ��GS464E���ܹ��� |
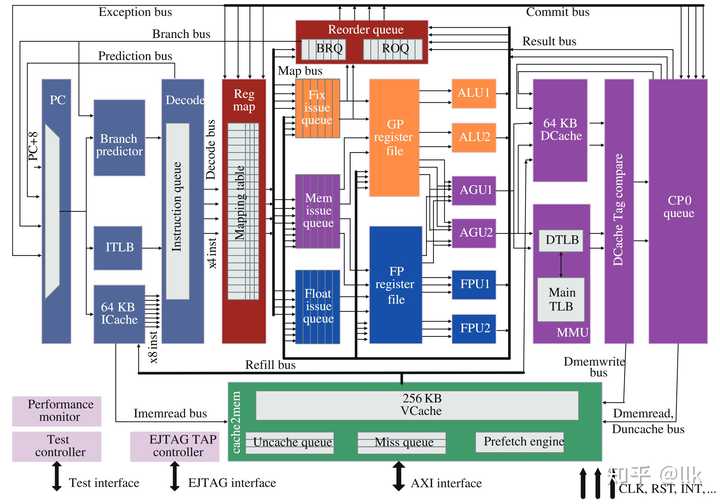
|
|
5.1.1 ȡָ��Ԫ GS464E��ȡֵ��Ԫ��Ҫ����L1ָ��棬ָ��TLB����֧Ԥ������ָ����к����뵥Ԫ����ͼչʾ��GS464E��ȡֵ��Ԫ����ˮ�ߣ� |
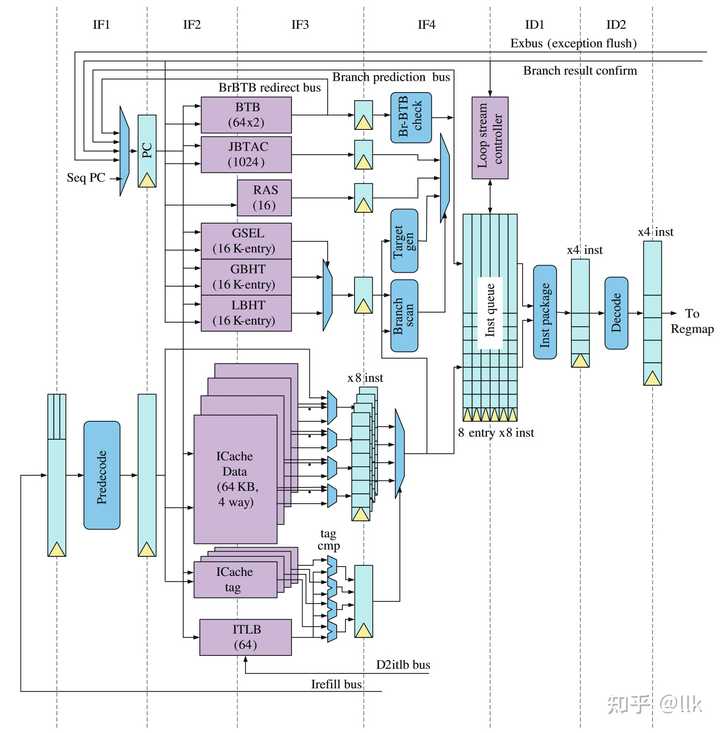
|
|
ÿ�� GS464E �������˰��� 1 ��4 ·������ 64 KB ��ָ���, �仺���д�СΪ 64 �ֽ�, ָ���ı�ǩ�����ݲ���ͬʱ���ʲ�����һʱ�����ڽ������е��ж���ѡ���������ݲ��ֻ���Ϊ 8 ��bank��ÿ��ȡָ��ʱֻ�ö�ȡ����Ҫ��bank, �����˻������ʱ�Ķ�̬���ġ�ָ���ʹ�����ַ������ʵ��ַ��ʶ������������ȡָ��������ʵ��ַת��ͨ�� 64 ��ȫ�����ṹ��ָ�� TLB ���, ָ�� TLB �е�������ҳ�����Ӽ�������, ÿ���� 1 ��ҳ����, ÿ��ҳ�������֧�� 4 KB-1 GB ֮�䲻ͬ��С��ҳ����ָ�������ʱ, ȡָ����ÿ��ʱ�����������Դ�ָ�����ȡ�� 8 ��ָ��, �������� һ����ˮ�����з�֧Ԥ��. ����ָ���δ����ʱ, ȡָ���������������ʻ���ʧЧ����, �ô�ʧЧ���и�����л���ȱʧ����, ����������ظ�ָ��档�ӻ���ʧЧ�ӷ��صĽ�����������ָ��棬 ָ����������� 3 �������в�����, ���� 3 ��δ��� (outstanding) �Ļ����в�����ʱ, ���ɿ��Դ���ȷ�ĵ�ַȡָ���ȡָ����ǡ�����ڴӻ���ʧЧ���з��صĻ�������������ʱ, ����ֱ��ȡ����Ӧָ�������һ����ˮ������ ��, ָ����Ԥȡ�ɻ���ʧЧ�����е�Ӳ��Ԥȡ����ͳһ���, ����ȡָ�����е������С�ָ�������ݲ����л�����Ԥ������Ϣ, ÿ��ָ���Ԥ������ϢΪ 8���ش�С, ��Ҫ����ָ���з֡���֧�����ж��Ͳ���ָ��������ж���Ԥ������Ϣͨ���ڻ���ʧЧ��������ָ���ʱ����ó�, ���洢��ָ����С� GS464E �������˲����˶��ֲ�ͬ�Ļ�����Ԥ���ָ֧�����ת�������תĿ��, ��ͨ����֧Ŀ�껺���� (BrBTB) ��������ָ֧��֮��ȡָ���ݵ��������֧Ԥ�������ÿ��ʱ�����������Դ��� 4 ����ָ֧��, ��ֻ�����һ��������Ԥ��Ϊ��ת�ķ�ָ֧��, Ԥ��Ϊ��ת�ķ�ָ֧��ĺ���ָ�����һ��ʱ�����ڽ��д�����GS464E �������˲��� 3 ��ʱ�������ӳٵ� ��ȡָ �� ��֧�� ѭ���������, �� 1 ��ʱ������ ���ݳ�������� (program counter, PC) ��ֵ����ָ��� �� 2 ��ʱ������ ָ����ѯ���, ȡ����� 8 ��ָ�� * �� 3 ��ʱ������ ��������ָ��, Ԥ���ָ֧�����ת�������תĿ��, ���ȡ���Ķ���ָ���д���Ԥ��Ϊ��ת�ķ�ָ֧��, ����Ҫ���ݴ���ָ������������������� PC ֵ ����ȡ��ָ�Ԥ�������ָ�� PC ��Ҫ���� 3 ��ʱ������, ������ 2 ��ʱ��������ȷ����ȡ���������ָ��, Ϊ����������ʧ, GS464E ��������ʵ���˷�֧Ŀ�껺���� (BrBTB), ֱ�Ӹ���ȡָ��ʹ�õ� PC ֵԤ�����ָ��� PC ֵ�����ȡ����ָ����û��Ԥ��Ϊ��ת�ķ�ָ֧��, BrBTB Ҳû��Ԥ�����Ҫ����� PC ֵ, ��ȡָ�����ӵ�ǰ PC ���˳��ȡָ�BrBTB Ϊ 128 ��ȫ������ ��, ʹ�õ�ǰʱ�����ڵ� PC ֵ�������¸�ʱ�����ڵ�Ԥ�� PC, ����Ԥ����ȷ�������, ��ʹ����Ҫ��ת�ķ�ָ֧��, ȡָ��ˮ��Ҳ���������BrBTB �Ĺ����Ǹ��ݵ�ǰ PC ��Ԥ����һ��ʱ�����ڵ�ȡָ PC, ����������ָ֧��֮���ȡָ����, ���Ƿ�֧Ԥ���������Ҫ������ͬ��ָ�������в�ͬ�����ġ� ��ָ֧����ת�����Ԥ��ʹ��һ����Ϸ�֧��ʷ�� (BHTs), ���� 1 �� 16384 ���ȫ�ַ�֧��ʷ�� (global branch history table, GBHT), 1 �� 16384 ��ľֲ���֧��ʷ�� (local branch history table, LBHT) �� 1 �� 16384 ���ȫ��ѡ����ʷ�� (global branch select table, GSEL)��ÿ��ʱ������ȡ������� 8 ��ָ�����ͬʱ��������֧��ʷ�������� 3 ����֧��ʷ���е�ÿ��� 2 bit ���ͼ�����, ����߱���λ�� GBHT �� LBHT ������ָ����ת����, ���� GSEL �������ھ���ѡ�� GBHT ���� LBHT ��Ԥ�ⷽ�� �����תָ�����תĿ��Ԥ���Ϊ�������: ����������תָ�� (MIPS ָ��е� JR r31 ָ��) ���� 16 ��ķ��ص�ַջ (return address stack, RAS) ����Ԥ�⡣����֧Ԥ��η��ֺ���������תָ��ʱ, ����ָ���ӳٲ�֮��ָ��� PC ֵѹ�� (push) �� RAS �С�����֧Ԥ��η��ֺ���������תָ��ʱ, �� (pop) RAS ջ������ŵ� PC ֵ��Ϊ��תĿ���Ԥ��ֵ��Ϊ�˷�ֹ�ڴ����Ʋ�·����ִ�ж� RAS ջ��ָ���ջ�����ݵĴ�����, RAS ��ջ��ָ��͵�ǰջ���� PC ֵ�������� ʱ����, �����Ծ��� ����������������תָ��֮��ĵļ����תָ��ʹ������Ϊ 1024 ����תĿ�껺���� (jump branch target address cache, JBTAC) ����Ԥ��, �û�����ʹ��ȡָ PC ����ת��ʷ��Ϣ���������� ��ָ�ȡ����, �����Ԥ������Ϣ��ָʾ, ���ղ�ͬ��ָ������, �ֱ�ʹ������ 3 �ֻ����е�ij һ�ֻ��ƽ��з�֧Ԥ��. ������֧Ԥ��κ�, ָ������СΪ 64 ���ָ�������. �� GS464E �� ��������, ���ڸ�ָ����е���Դ��ʵ����ѭ�������� (loop buffer). ѭ���������������ָ����е�ָ���� PC ����, ������ָ�����а���һ�������� 56 ��ָ��ĵ���ѭ��ʱ, ��ֹͣ��ָ���ȡָ, ����ֱ�Ӵ�ָ�������ȡ��ָ���͵������. ��ѭ�������ﵽ���˳�ѭ��ʱ, ѭ���������ᱻ���. ���빦�ܲ�����ÿ��ʱ�����ڻ��ָ�����ͷ��ȡ�� 4 ��ָ��������롣������̵���Ϊ�ϼ�, ���ǽ�ָ���뷭��Ϊ���㹦�ܲ����������ڲ���, ��ʶ��ָ�����͡�����Ҫ�����ļĴ������Լ�ָ�����п��ܰ�����������, ���ڽ������ļĴ����������Ρ� 5.1.2 ָ��������ύ��Ԫ ָ��������ύ��Ԫ����ָ���ڴ��������еķ����붨��, ��������Ĵ�����������ָ����䣬ָ��䣬ָ���ض���ָ���ύ����֧���쳣�����⼸�����ܡ� ������ָ�����Ƚ��мĴ���������, �����ݲ������ͷ�������ͬ�ķ�������С��Ĵ����������Ƕ�̬��ˮ���н���������Ĺؼ�����, ��Ϊָ����ָ�������Ĵ������Է���һ�������Ĵ������� GS464E ����������, ��Ҫ�����������ļĴ�����: ͨ�ö���Ĵ�����ͨ�ø���Ĵ�����HILO �Ĵ�����DSP ���ƼĴ���������ȽϽ���Ĵ�������Щ��Ҫ�������ļĴ������Խ���ӳ��, ͨ�������Ĵ���ӳ��� (physical register map table, PRMT) �����������Ĵ��������Ĵ���֮��Ĺ�ϵ. ����ͨ�ö���Ĵ�����������Ϊ 128 �� 64λ���ļĴ�����, ����ͨ�ø���Ĵ�����������Ϊ 128 �� 64λ���ļĴ�����, ���� HILO �Ĵ�����������Ϊ 16 �� 128λ���ļĴ�����, ���� DSP ���ƼĴ��� ��������Ϊ 32 �� 32λ���ļĴ�����, ���ڸ���ȽϽ���Ĵ�����������Ϊ 32 �� 32λ���ļĴ� ���ѡ� GS464E ������������ 3 �������ķ������: 16 ��Ķ��㷢����У����㷢����и���Դ��������Ŀ���������Ϊͨ�ö���Ĵ�����HILO �Ĵ����� DSP ���ƼĴ���������ָ��ͷ�ָ֧�� 24 ��ĸ��㷢����У����㷢����и���Դ��������Ŀ���������Ϊͨ�ø���Ĵ�����ȽϽ���Ĵ���������ָ��ͷ�ָ֧�� * 32 ��ķô淢����У��ô淢����г��˸������ж��㣬����ķô����ָ����, ���������ƼĴ�������ָ�� (CP0 ָ��) �Լ��ڶ����븡��Ĵ����佻�����ݵ�ָ�� �ӿ��ƹ��ĵĽǶȳ���, 3 ��������о������ƶ�ָ������ƶ������д洢���ݵĹ�������, ÿ ��ʱ��������Ҫ���㵱ǰӦ������ָ���ָ�롣ֻ��Դ�Ĵ������Ѿ�������ָ����ܱ�����, ��ָ���ڼĴ�����������ʱ�ͻ��ȼ����Դ�Ĵ����Ƿ��Ѿ�����������Դ��������û������, ���ָ���ڽ���ָ������Լ��ڷ�������е�ʱ��, ��Ҫ��������Դ�Ĵ�����ͬ�������ǰ�����ߵ�Ŀ��Ĵ�������Ƚ�, ��ȷ������ָ�������Դ�Ĵ����Ƿ��������ʱ��ʹ�õļĴ����Ŷ��Ǿ����Ĵ�����������������Ĵ����š������� 3 ��������ж��������������, ָ�������Դ������ֻҪ���þͿ��Է��䡣�����ڶ�������ѡʱ, ��������ָ�������ߵ����ȼ��� �� GS464E ����������, ָ�˳����������������������ִ��, ����Ҫ�����ύ���ض�����и���ָ����������, ���ӼĴ���������ģ���ȡ����ָ������Ϣ, ������ر�����ˮ���������Ѿ���ɼĴ�����������δ�ύ��ָ�ָ���ڹ��ܵ�Ԫִ����ϲ�д�� (writeback) ��, �ض�����а��ճ���ָ����˳���ύ��Щָ��ض����������ͬʱ���� 128 ��ָ��ض������ÿ��ʱ�������������ύ���ж��˵� 4 ���Ѿ�����д��״̬��ָ�ָ����ύ��Ϣ�������Ĵ���������ģ��, ��������������״̬, ͬʱ����Ҫ֪ͨ�ô��ض������, ��Ϊ�洢ָ����Ҫ�ύ������Ĵ洢�������ݡ�GS464E ��������ʵ���˾�ȷ�쳣, ��ȡָ������ִ��ʱ�����쳣ʱ, �쳣��Ϣ�������ض�����б�������, ֻ���쳣ָ���Ϊ�ض������ͷʱ, �Ž����쳣�����봦����Ӳ�����е��쳣������������: ���쳣ԭ���쳣ָ��� PC ֵ����Ϣ��¼���йص� CP0 �Ĵ�����, �������쳣���Ͱ��쳣�����������ڵ�ַ�͵�����������С� ��ָ֧���ڼĴ���������������ض�����кͷ�����е�ͬʱ����˳��ؽ����ָ֧����С�GS464E ���������еķ�ָ֧��������������� 24 ����ָ֧��, �ö��л��¼��ָ֧����з�֧Ԥ��ʱ��Ԥ��������ָ֧�������ָ��һ������Ҫ�ڹ��ܲ���ִ��, �����������߶��������֧���, ��֧�����д�ص���ָ֧����С���Щ������� JR �� JALR ָ���Ŀ���ַ, �Լ�����ת��ָ���ת�Ʒ���, ������Щ��������ж�����ָ��ķ�֧Ԥ���Ƿ�ȷ. ����Ԥ��ɹ����, ��ָ֧���ִ�н�����ᷴ����ȡָ����, ����������صķ�֧Ԥ����, ����������ָ֧���Ԥ�⡣Ԥ�����ķ�ָ֧�������֮��ȡ������ָ���Ҫȡ������ָ֧����и����ͷ�֧����ȡ������, ���ݶ����м�¼�ij���ָ����, ȷ�ؽ��з�֧ȡ������, ͬʱ����ȷ�� PC ֵ�͵�������� ���С� 5.1.3 ���㵥Ԫ���㵥Ԫ GS464E ���������еĶ��㵥Ԫ���� 1 ����˿ڶ���Ĵ������Լ� 2 ����ȫ��ͬ�Ķ������㵥Ԫ������Ĵ����ѹ� 128 ��, һ���� 8 �����˿ں� 4 ��д�˿ڡ�ÿ������������ˮ���о�����: ���� ִ�ж���ӡ������Ƚϡ�����ָ�����������Ԫ (arithmetic logic unit, ALU), ����ִ����λ��ѭ�� ��λ�ͱ�����ȡ��ض�ָ���ѭ��Ͱ����λ��, λ������Ԫ, ǰ���������, ��֧������Ԫ, ���������ͳ˷���, ÿ�����㵥Ԫ��������Ϊ 1 ��������Ƶ��ִ�е�ָ����� 1 ��ʱ��������ִ�����, ��ͨ��������ǰ���������, ʹ�ô��ڼĴ�����صĶ���ָ����Ա������������䡣�˷�������ȫ��ˮ���, �ɽ��� 64x64�з��Ż����ų˷�����, �����ӳ�Ϊ 3 ��ʱ������, ȫ��ˮ���ʹ��ÿ���˷�����ÿ��ʱ�����ڶ��ɽ��� 1 ���µ�ָ��, ������ 128���صij˻������ GS464E ���������еĸ��㲿������ 1 ����˿ڸ���Ĵ������Լ� 2 ����ȫ��ͬ�ĸ������㵥Ԫ�������˿ڼĴ����ѹ� 128 ��, һ���� 8 �����˿ں� 4 ��д�˿ڡ�ÿ������������ˮ���о�����: ��ʽת����Ԫ (����ִ�� ������תΪ���㡱���������ȸ���תΪ˫���ȸ��㡱 �����ʽת��ָ��), ����Ƚϵ�Ԫ, ���������Ԫ, ���㿪����������Ԫ, �Լ�����˼� (fused multiply�Cadd) ��Ԫ (����ִ�и���ӡ������ˡ��˼ӡ��˼�ָ��), ÿ�����㵥Ԫ��������Ϊ 1 �������и�ʽת����Ԫ���� 3 ��ȫ��ˮ���, ����˼ӵ�Ԫ���� 4 ��ȫ��ˮ��ơ� 5.1.4 �ô浥Ԫ �ô沿���������µ��Ӳ���: �ô�ָ������ mmqueue���ô�ר�ö���Ĵ����� mr�������ô��ַ���ɲ��� memaddr, һ�����ݻ��棬һ������ TLB ���� ���ô��ǩ�Ƚϲ��� dtagcmp���ô��ض������ cp0queue, �Լ����� TLB ���� sec tlb��ֻ��һ�ݵ��Ӳ����������ô���ˮ�߹���ʹ�á���ͼչʾ�˷ô浥Ԫ��ˮ�ߣ� |
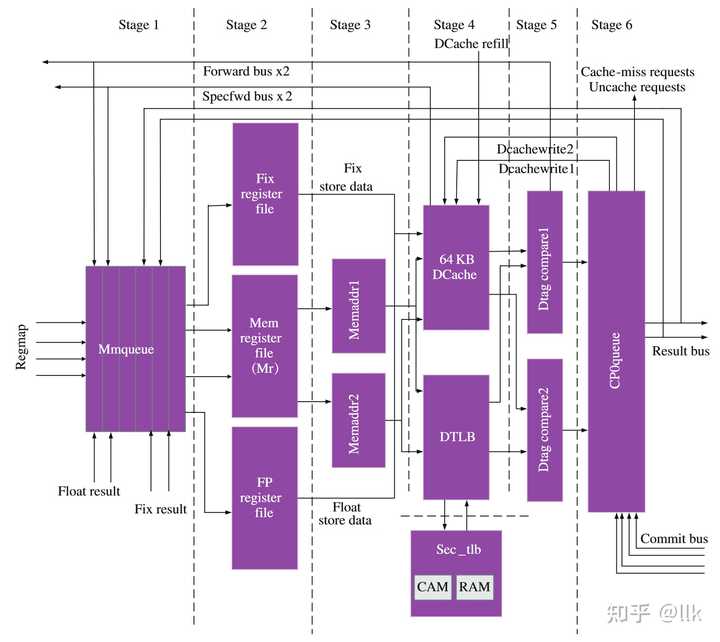
|
|
�ô�ָ������ mmqueue ���ռĴ�������������������ָ����Ϣ, ������ǰ�Ѿ������� ����ָ���������ϵķô�ָ��䵽�ô���ˮ���ϡ��ַô�ָ������������ô沿���е�����һ��ִ��, �洢�����ͼ��ز���һ��, ��ȴ���ַ������ͬʱ������, �ŷ��䵽��ˮ���С������ô���ˮ����ӵ�� 4 �����˿ڵļĴ����� mr �ж�ȡ����IJ�����; һЩ����ָ����Ҫ���Ͷ�������ȥ���㲿���㲿��, �Ի�ȡ�����Դ����, ����, ����洢ָ�� SDC1 ����Ҫ�洢������ֻ����ڸ���Ĵ������С��������͵ķô�ָ��ĵ�ַ�϶������� mr ��, ����Ҫ�Ӷ��㲿���㲿��ȡ�������ô���ˮ�߷ֱ�ӵ��һ����ַ����ģ�� memaddr����ַ����ģ����ݷô�ָ�������, ���� mr �����ļĴ������ݼ���ô�ָ��������ַ (effective address, EA �����ַ)�����ַ��λ�͵����ݻ���ģ�������������, �������ַ�͵� DTLB ģ�������ʵ��ַ���롣 һ�����ݻ������� 4 ·��������ÿһ· 16 KB ��С��˫�˿�����洢�� (random access memory, RAM) ���ɵ�, �����˿ڷֱ��Ӧһ���ô���ˮ�ߡ�ÿ���˿ڸ��ݵ�ַ�ĵ�λ��ȡ RAM �д�ŵı�ǩ������, ���������Ľ������ dtagcmp ���������б�ǩ�Ƚϡ�ͬʱ, �洢ָ����Ҫ�洢�������ڴ˵�Ԫ����, ͬ��Ҳ�͵� dtagcmp ������һ������ TLB ��һ�����ݻ���ͬʱ����ѯ��һ������ TLB ����ʹ�� 2 �� 64�������ַ��Ϊ����, ��ѯ˫�˿ڵ�ȫ������֯�� DTLB, �õ� 2 ���ô�ָ������ַ����Ӧ�� 48����������ַ (physical address, PA ��ʵ��ַ), ������ dtagcmp ģ�������б�ǩ�Ƚϡ�����, �� CP0 ��ص���Ȩָ��, �� MTC0 �� MFC0 ������ DTLB ģ��ִ�еġ�����ʵ��ַ�Ƚ�ģ�� dtagcmp ģ��ֱ��Ӧһ���ô���ˮ�ߡ����ģ�齫���ݻ���ģ������� 4 ·��ǩ�� DTLB ģ��õ���ʵ��ַ���бȽ�, ȷ��һ�����ݻ����Ƿ�����, �Լ���������һ·������·�����ݻᱻȡ��, ������������ �洢ָ����Ҫ�洢������һ�����, �õ��ô�ָ���ִ�н��, ���͵��ô��ض������ cp0queue���ô��ض������ cp0queue ���ճ���ָ������Ϣ, ���� dtagcmp ģ��������ָ���ַ�������� Ϣ, ��ͨ���ع�������ά��������ķô�ָ��֮�����ȷִ����Cp0queue ���˷ô�ָ���ض�����֮��, ��ÿ��ʱ�����ڻ���Ҫд����� 2 ����д�ص� ����ָ��� ��� 2 ����д�صĴ洢ָ������ 1 ���ô�ʧЧ��ָ����������ʧЧ���У������ 2 ���Ѿ��ύ �ұ�����дһ�����ݻ���Ĵ洢ָ��͵�һ�����ݻ����д�˿ڡ�Cp0queue ���Ա������ô�ָ��Ĺ���, ���зô�ָ���������л���ʧЧ������д�ء�Ŀ��Ĵ���Ϊ����Ĵ����ļ������ͷô�ָ���ڴ����ݻ�����ˮ���� dtagcmp ��ˮ������ʱ, ����в²���ǰ��������, ��Ϊ specfwd���ڴ� dtagcmp ��ˮ���� cp0queue ����ʱ, �����·�����һ ��ʱ�����ڵ� specfwd ��Ϣ, �γ� fwdbus ���ߡ������ô����ߵ���� 4 ��������ǰ��������Ϣ�ᱻ �������㷢����кͷô淢�����, ���ò²�������, ʹ��ָ����Բ²�ط��䡣����²�ǰ���²����, ��ᷢ�Ͷ�Ӧ�÷ô���ˮ�ߵIJ²�ȡ���ź� spec cancel, �²�������������: һ�����ݻ���δ���У�����һ�� DTLB δ���У����߸�ָ���� cp0queue ���ع����²�ȡ���źŽ���ȡ����Ӧ�� specfwd �Լ� fwdbus ���ߴ��������к��, �Ѿ��²ⷢ�����Ӧָ��Ҳ�ᱻȡ��, ���ص�����������µȴ�������ᡣ������ ǰ�����Ƶ�������, ���Ե�֪�ô�ָ������������µ��ӳ�: �ô�ָ�����ָ���Լ��ô�ָ��ô�ָ��� load-to-use �ӳ�Ϊ 4 ��ʱ������, �ô�ָ�����ָ��� load-to-use �ӳ� Ϊ 6 ��ʱ�����ڡ� �ô��ض������������ά��������ķô�ָ��֮��ִ��˳��Ļ��ơ���֮ǰ�� GS464 �������������, �ô��ض����ȡ�������ݴ��ݻ���, ʹ�����ݴ��ݻ��ƽ��зô�ָ���ض���ķ���Ϊ: ��һ��ָ�������·�������ض������ʱ, ����ָ����Ҫ������ִ��������֮ǰ�ģ�������صĴ洢ָ���ȡ��Ӧ����; ͬʱ, �������ָ���Ǵ洢ָ��, ��ô����ָ�Ҫ�����Լ������ݴ��ݸ����е��Ѿ����ض��������������ص���ִ�������������ָ���˵��, �û��ƿ��������� ��ȡǰ���������������, ʵ�����������ݴ��ݻ��ƴ��ۺܴ�: ��ָ����ܴӶ���ָ�ȡ������, ���ܴ�����ָ���ȡ�����ֽڵ�����; �洢ָ����ܰ��Լ������ݴ��ݸ�����ָ��, ���ܽ����ݴ��ݸ�����ָ��������ֽ�λ�á�������Ƶ�������ƹ��ڸ���, ���������˶��еĹ�ģ, ��ʹ GS464 ���������еķô��ض������ֻ�� 24 ���С�� �� GS464E ����������ʵ���� 2 ���ô湦�ܵ�Ԫ, ͬһʱ�̿����� 2 ��ָ�����ô��ض������, ���ݴ��ݻ��Ƶ�ʵ�ִ��۸������Խ��ܡ�Ϊ�����ָ��жȣ����ô��ض��������������, �� GS464E ����������, ֻ������ָ���Ƿ���ص��ж�, ȡ�������ݴ��ݵĹ���, ͨ��ָ��ع�������������·���Ļ�������ִ֤�е���ȷ�ԡ�����������ʽ��������: ��һ��ָ�������·�������ض������ʱ, ���ֶ�������ִ��������֮ǰ��������صĴ洢ָ��, ��ô��ָ��ع����ô淢����� mmqueue, ���ȴ��ô洢ָ��д��һ������ ������ٴη���; ���һ���洢ָ�������·�������ض������ʱ, ���ֶ���������ִ��������֮���������ص�ָ��, ��ô����Щָ��ع��� mmqueue, ����Щָ�����·��䡣����, ָ����ص��жϻ����ָ��IJ������ͣ��ô��ַ����Ϣ���о�ȷ���ж�, ����, �� A ��ַ�İ��ִ洢 SH ����������ʹ�ö� A+2 ��ַ�İ���ȡ LH �����ع�����˵��, �û��ƿ�������Ϊ ����ǰ���ͨ����ȡ ����ǰ��� �ķô��ض������������ ��ȡǰ���� �IJ���, �������˷�����кͷô��ض�����е���Ƹ��Ӷ�, ��һЩ����»�����������ܽ���, ����ȴ�����������Ƶ��Ѷ�, ������ͬ���������Ƶ��ʹ�ø���ķô��ض������, ���ӷô�ָ��ж�, ���Ը��õ����̷ô��ӳ١�ͬʱ, ҲΪ֧�ָ���ķô����, �� 256���������ô�ָ��, �ṩ�˿����ԡ� GS464E ���������е�һ�����ݻ����ȡ 4 ·�������ṹ, �ܴ�СΪ 64 KB������, ÿһ·��СΪ 16 KB, ��Ϊ 256 ��������, ÿһ��Ϊ 64 �ֽڡ�һ�����ݻ���ʹ�����ַ����, ʵ��ַ��ʶ, ÿһ����������Ҫ 48���صı�ǩ���洢ʵ��ַ��Ϣ, �Լ� 512���ص��������洢����, ��ǩ�����ݲ��ֶ�ʹ�� ECC У�������������ౣ����һ�����ݻ������ LRU �滻����, ��һ�������б���ѯ����ʱ, ����ʧЧ����������ʱ, �ᱻ���������ѱ��滻�����ȼ�; ���һ������������һ���Ե��µ��ⲿ������Ч, �û����лᱻ�����������ױ��滻�����ȼ���һ�����ݻ�����һ��˫�˿ڵĻ���ṹ, ÿһ��ʱ��������ʵ�� 2 ���ô�ָ��IJ�ѯ������ͬʱ, �洢ָ��ӷô��ض�����з���д�������ʱ, Ҳͨ���� 2 ���˿ڽ���д����, �����ȼ����ڷô�ָ��IJ�ѯ����������֮��, ECC У�����ʱ���Ծ��������ͻ���ʧЧ����������Ҫ�ӵ�һ��д�˿ڽ���д��, д������������ض����ȼ�����, ���Ե����ȼ��IJ������������� ��ʵ��ַ���빤����Ӳ��ʵ������������ TLB ����ɵġ�һ������ TLB ��������, ÿ�ηô����ִ��ʱ����ѯ; �����ɼ����Ƕ��� TLB, ������ TLB ��ָ�� (�� TLBWR) ��ֱ���Ķ��� TLB�� ���� TLB ��һ������ TLB �ǰ�����ϵ, һ������ TLB ��ȱʧ���Զ��Ӷ��� TLB �в��Ҳ�ȡ ��, Ӳ�����Զ�ά��������ϵ�� ����, ָ�� TLB Ҳ�Ǹ��ݶ��� TLB �е���������ġ� һ������ TLB �Ĺ�ģΪ 32 ��, ���� TLB ������ 2 ���������, ���� 64 ��ȫ�����Ŀɱ�ҳ��С�ĵ�ַ��Ѱַ�洢�� (content addressable memory, CAM) ����, �Լ� 8 ·��������ÿһ· 128 ��, ���� 1024 ��Ĺ̶�ҳ��С�� RAM ����, ������ TLB �е�ÿһ�����װ�� 1 ���� MIPS ˫ҳ��һ ������ TLB ��˫�˿ڵ�, �ֱ��Ӧ�� 2 ���ô湦�ܲ���, һ�� TLB ��ѯ����������ʱ, ��ѡ���ڳ���ָ�����Ͻ��ϵ�����ָ������ѯֻ�� 1 ���˿ڵĶ��� TLB������ TLB ��ѯ��Ҫ���� 2 ��ʱ������, �������, ��ô���еĽ����д��һ������ TLB, ���滻����Ϊ����滻; ���δ����, ����Ҳ��֪ͨ�ô��ض�����С���Ҫ��ѯ���� TLB ��ָ����ô��ض�������еĻع�����, ���»ص��������, �ٴη���ʱ, ���� TLB �IJ�ѯ����Ѿ�����, ��˿����ж��Ƿ������ķ����� TLB ʧЧ�쳣�� ���� TLB �пɱ�ҳ���� (CAM ����) �̶�ҳ���� (RAM ����) �ᱻͬʱ��ѯ, ������������ TLB д��ʱ, ֻ������һ���ᱻ��: ���д�����ҳ��С����ǰ���úõĹ̶�ҳ��ͬ, �� TLB ָ�� �Ὣ TLB ����д��̶�ҳ����, ����, ��д��ɱ�ҳ���֡� 64 ��� CAM ���ֺ� 8 ·�������� RAM ���ֶ���������滻���ԡ� GS464E �������˵�һ�����ݻ�����һ��д�� (writeback) ʽ�Ļ���, ���еĴ洢��������Ҫ��һ�����ݻ������д�롣 ���洢ָ�������ʧЧʱ, ��Ҫ���洢ָ������Ļ����д��ڴ������һ�����ݻ���, �ٽ���д�롣Ȼ���ںܶ������, �洢ָ���������������������, ���������˹��̾��Եö���, �������˲��ٵ�ʱ���빦�Ŀ����� Ϊ�˽����������, GS464E ���������������˴洢��� (store fill) ���ơ��û��ƵĹ���ԭ��Ϊ: ���洢ָ����һ�����ݻ����з�������ʧЧʱ, ��ô�ʧЧ����Ὣ���洢������һ������λ�ڻ���ʧЧ�����еĴ洢��仺����, ͬʱ, �÷ô�ʧЧ�����ݻ����� SCache������������Ķ����洢�����ڸû������гɹ���ƴ���˻�����, ��ôֻ���� SCache ����հĻ����м��ɡ��յ��հ�������� SCache ��������ڴ�, �ڽ��ж��һ���Դ�����ֱ�ӷ���, ����ʧЧ���и���������ƴ�������������һ�����ݻ��档�ڴ洢�������ڼ�, ��Ӧ�Ĵ洢ָ������˳���ˮ��, �ͷŶ��пռ䡣����ϳ�ʱ��û��ƴ��һ��������, ������������ͬһ�������еļ��ز���, �������ڴ���������� (�� SYNC �� CACHE ָ��), �洢�����ƾͻ�����˳�����, �� SCache ����һ�������Ļ�����, ��������غ�, �ڻ�������������ƴ�ղ���, ��ƴ�պ�Ľ�����һ�����ݻ��档 Ӳ�����¼�洢���ɹ����Ľ�����ʷ, ���Դ洢�����ƽ����Զ������� GS464E ����������ʵ�ֵĴ洢�����ƿ��������ڶ�˴����������, �����˴洢ָ��µ��ڴ��ȡ, �������洢ָ����ǰ�˳���ˮ��, �����˴�����������ִ�����ܡ� 5.1.5 ����ʧЧ���� ����ʧЧ����λ��һ�������� SCache ֮��, ����� Victim Cache ���з��ʺ���, ʵ�ֻ���ʧЧ����Ĵ����������, ������Ӳ��Ԥȡ��������ɺʹ����� �� GS464E �����������, �Ի���ʧЧ�Ĵ������̽����˶�����ԵĸĶ�, �������ڻ���ʧЧ���е�����ȾӲ��Ԥȡ��������Լ�����֧�ֶ������Ĵ洢�����ơ� ����ʧЧ���й��� 16 ��, ����ö��е���������ô��ض�����з����ķô�ʧЧ����ȡָ����������ָ��ʧЧ�����Լ� SCache �����Ķ��һ��������, ����, Ӳ��Ԥȡ����Ὣ���ɵ����ݺ�ָ��Ԥȡ����Ҳ������ʧЧ����, �ɸö��н��д��������н�������ĵ�ַ��Ϊʵ��ַ������ʧЧ�����еĻ���ʧЧ������Ȳ�ѯ Victim Cache, �������, ��Ὣ��������һ������, ����һ�������滻���Ļ��������� Victim Cache ��֮ǰ��ȡ����λ��; ��� Victim Cache ��ѯδ����, ������ SCache, �� SCache �Ľ�����غ�, ����һ������, ��һ�������滻������Ч���ݸ��� LRU �㷨д�� Victim Cache, ���� Victim Cache �滻������Ч������д�ص� SCache�� ����ʧЧ�������ǻ��Ȳ�ѯ Victim Cache, ��ѯδ����ʱ�ٲ�ѯ SCache, ���ִ��з��ʵ���ƽ����˻���һ����ά���ĸ��Ӷȡ�����ʧЧ�������� SCache �����Ķ��һ����������һ������� Victim Cache ���в�ѯ, ���ݲ�ѯ�����һ�������������, �Ի����н�����Ч��д�صȲ���, ����������� SCache������ʧЧ�����е�Ӳ��Ԥȡ������ SCache ���в�ѯ, ���ݲ�ѯ���, ��Ԥȡ���������ݴ��ڶ����С�����л���ʧЧ�����Ӳ��Ԥȡ�������ͬһ��������, ��ôԤȡ�������ݻᷢ���������ʧЧ������ʧЧ���лᶨ���������Щһֱû�б�ʹ�õ���Ԥȡ���ݡ�������Ԥȡ������ʽ��������κ�һ��������Ⱦ������ͬһ�������еĻ���ʧЧ�������ڻ���ʧЧ�����н��кϲ�, ��ֻ����ͬ�������ݻ���ʧЧ��ָ���ʧЧ������ʧЧ���л���ר�ŵĻ��������ڴ洢�ô�ʧЧ�洢ָ�������, ��֧�ִ洢�����ơ� GS464E ����������ʹ�������ͬʱ֧�� 4 �����ݷ������� 1 ��ָ�����������ʽӲ��Ԥȡ����, ���ݺ�ָ���Ԥȡ��Զ����� ����, ������ʽԤȡ�������֧������ͽ���ģʽ, ʹ�÷ô�ʧЧ������������ά����������Ϣ; ��ָ��Ԥȡֻ��֧�������Ԥȡ, ʹ��ָ��ʧЧ������������ά������ Ϣ�� ��ʧЧ����Ϊ������ 2 ��������ʱ, ���Ὠ��������, ÿ�������������� 3���صĵ���������, ���ڼ�������������Ƿ��ѹ��ڡ�����ʧЧ���������ij��������������, ��ô����������������ļ�������ˢ�µ����ֵ��������������, �Ϳ��Դ���Ԥȡ, Ԥȡ����Ĵ������������������. �������ʧЧ�����ڻ���ʧЧ�����к�Ԥȡ����ϲ�, ֤��Ԥȡ�������, ������ݴ˴�ʧЧ�ĵ�ַ��ѯԤȡ�������Ѿ������ķ�������Ϣ��ָ��ʧЧ������ѯָ��Ԥȡ����, ���ô�ʧЧ������ѯ����Ԥȡ���档�����������ѯ����, ����ݷ����������������Ϣ, ���� 1 ��Ԥȡ����, Ԥȡ����ĵ�ַ��ʧЧ��ַ�����ض�����; �����������ѯ������, ��Ѱ�Ҽ�����Ϊ����������С�ķ�����, ���䶥�档���δ�ܺ�Ԥȡ����ϲ��Ļ���ʧЧ������ Victim Cache �в�ѯδ����, ��֤����Ҫ����Ԥȡ, ��ʱ����ݴ˴�ʧЧ�ĵ�ַ��ѯԤȡ�����еķ�������Ϣ, �����������Ϣ��ѯ����, ����ݷ����������������Ϣ, ����Ԥȡ����, Ԥȡ�����ַ��ʧЧ��ַ�����ض�����; ��������ѯδ�������в�����ÿ�δ���Ԥȡʱ, Ԥȡ��ַ�����ʧЧ��ַ�������������������������ʷ�����������仯, ���������Ĵ���Խ��, ��Ԥȡ����Խ���������ֵ�����������ѽ����ķ������ĸ�������: ��ֻ�� 1 ������������ʱ, �������ޱ��趨Ϊ 4 �������д�С; ������ 1 ��������ʱ, ���������趨Ϊ 2 �������д�С��ָ��Ԥȡ����������һֱ�趨Ϊ 4 �������С�GS464E ��������ʹ������Ԥȡ����, �����ÿ�δ�����Ԥȡ�����IJ���, �ڷ�����Ԥ����ȷ�������Ч������ͬ��, ���Ƿ�����Ԥ�����ʱ, ����Ԥȡ���Ի���һЩ��Ч��Ԥȡ���� ���� GS464E ��������ʹ��������Ƭ�ϻ���ṹ, ����λ��ÿ�����������ڲ���˽�л������һ�����ݻ����һ��ָ���, �Լ����ݺ�ָ��õ� Victim Cache, ����������Ϊ SCache, �����д������˹�����һ��ָ���Ϊ 4 ·���������, 64 KB ����, �����д�С64 �ֽ�, ����滻��һ�����ݻ������ LRU �滻���ԣ�4 ·���������, 64 KB ����, �����д�С64 �ֽڡ� Victim Cache ������һ��������exclusive��ϵ, ����һ�������еĻ����бض��������� Victim Cache ��; Victim Cache �� SCache ά������ (inclusive) ��ϵ, Ҳ������ Victim Cache �еĻ����бض��� SCache �������Ӧ�ı��ݡ�һ������� SCache ��Inclusive��ϵ�� Victim Cache Ϊ 16 ·������, ÿһ· 16 KB, ���� 256 KB, �����д�СΪ 64 �ֽ�, ʹ�� LRU �滻���ԡ�Victim Cache λ��һ������֮��, �ɻ���ʧЧ���н��й���, ��һ�����淢������ʧЧʱ����ѯ�� ��ѯ Victim Cache ʱ, �ȶ�ȡ��ǩ�ٶ�ȡ����·�����ݵķ�ʽ, ʹ�������ӳ�����ȡ���ĵĽ��͡� �ڻ���ʧЧ�����ѯ Victim Cache δ���������, �ɻ���ʧЧ���и����� SCache ����ʧЧ����. ��һ�������д�һ���������滻����ʱ, �ᱻ���� Victim Cache, �� Victim Cache �滻�������ݽ���д�ص� SCache�� ָ����������ݻ����ж����Դ���� Victim Cache ��, �Ի����б�ǩ���е�һ����������������֡� SCache ΪƬ��ĩ������, �����д������˹���, һ���ĺ˴������ͻ�ӵ�� 4 �� SCache �� �� 4 ����������ʹ�á�ÿ�� SCache Ϊ 16 ·������, ����Ϊ 1 MB, �����д�СΪ 64 �ֽ�, ʹ�� LRU �滻�㷨�� ÿ�� SCache ʹ�ô�СΪ 16 ��Ĺ�����������ѯ��ά��. �����һ������� Victim Cache, ÿ�� SCache �Ļ����л�������� 64���ص�Ŀ¼��, ���ڼ�¼�� �����б��ĸ��������˳���, �Լ����������˳��е���ָ���л��������С������Ŀ¼����ƹ�ģ��, ���֧��һ��оƬ���� 32 ����������. �����������к�ָ����֮��, SCache ��������һ������� Victim Cache, ���һ�����ݻ�����еĻ����л� Victim Cache ���е����ݻ����ж��ᱻ�����ô������˳������ݻ����С��� GS464E �������������� SCache ��, �����˻��ڻ���һ���Ե�Ӳ����������ơ�������ʹ�õ�ҳ�Ĵ�С��һ��������ÿ������·��������С�������, �ͻ���ֱ��������, ͬһ��������ַ�ᱻ������һ�������еĶ�������ϡ�Ϊ�˱�֤ӳ�䵽ͬһ��������ַ�Ķ�����ַ֮���������һ�µ�, SCache �ڱ�ǩ���м����˶���� 2���ص�ҳȾɫ��, ���� SCache ��Ƭ����������İ�����ϵ, ��֤���������ֻ�ܴ��������㵱ǰҳȾɫ����ض�����λ���ϡ���һ���ô�����Ҫ��ҳȾɫ�����һ��ֵʱ, �ᷢ������ʧЧ, SCache ���ָ�����ҳȾɫ������֮��, ��ͨ��һ��������, д�ز���Ч����һ������� Victim Cache ֮�еĻ����б���, ��ҳȾɫ���ֵΪ��ֵ��, ���з���, �Դ˱�֤ÿ��������ַֻ��Ӧһ��ʵ�������ڻ���һ���Ե�Ӳ������������� GS464E �������˵Ĵ����Թ���, �ڱ���һ�������������ǰ����, ʵ���˶Խ�Сҳ�ĸ�ЧӲ��֧�֡�SCache �л�Ϊʹ��ԭ�Ӳ���ָ�� (����, LL/SC ָ��) ���ж�˵�ͬ���������������: ��һ�� ��������ʹ��ԭ�Ӳ���ָ����һ��������ʱ, SCache �ڶ�ʱ���ڽ���ֹ�����������ת�ø������������ˡ���ʱ����Ϊ�����, ����ķ�Χ����ͨ�������������á�ͨ���������, �����������ͬʱ����ͬһ���ڴ��ַʱ, ������ʱ���ϴ��п���, �����˾��������������ƿ�����߶��ͬ��������, �����Է�ֹ��ÿ���������˶�ռ��ʱ����̣����Ĺ������ݶ����µĻ��������� SCache �в�ѯʧЧ�����������һ���洢�豸�����ô�������һ���洢�豸�����ڴ�, PCI, SPI �������ⲿ�豸�� ��һ�����ݻ������еļ���ָ���ӳ�Ϊ 4 ��ʱ�����ڣ��� Victim Cache ����, ���������ô�ָ��������� 18 ��ʱ�����ڵ��ӳ٣������ Victim Cache ҲʧЧ������ SCache �����еķô�ָ��, ���һ���������е����Ҫ�� 50 ��ʱ�����ڵ��ӳ�, ���з��� SCache ��Ҫ��ʱ��Ϊ 11 ��ʱ������, �����ӳٰ���������Ƭ�ڴ��ݵ��ӳ�, �Լ�Ϊ֧�ִ������˽�Ƶ�������Ҫ���첽�������������ӳ١� 6 Loongson 3A3000 ��о 3A3000/3B3000��Ƶ 1.2Hz�C1.5GHz��Ϊ4�˴�����������4���ķ�������ִ�е�64 λ��������������GS464E��֧�� MIPS64 ָ���֧����о��չָ�������12 ����������ˮ��; ÿ����2 �����㵥Ԫ��2 �����㵥Ԫ�� 2 ���ô浥Ԫ��ÿ���������˰��� 64KB ˽��һ��ָ���� 64KB ˽��һ�����ݻ���;ÿ������������ 256KB ˽�ж�������;���д������˹��� 8MB �������档 ����о3A2000��ȣ�������Ƭ���մ���о���ʵ�40�����������ⷨ�뵼���28����CMOS ���գ�����������������Ҳ��4MB��ߵ�8MB����ֵ��������24GFlops�������� <40W@1.5GHz�����ɵĽӿ�������HT3.0�ӿڣ�PCI��������LPC��SPI��UART��GPIO������72λDDR2/3-1600��֧��ECC�� 7 Loongson 3A4000 ��о3A4000������о�����з���GS464V��������о3A4000��Ȼ����28nm����, ����Ƶ��ߵ�2.0GHz, �ۺ���������һ����о3A3000������������Ƭ�以����������Ƭ��HT�������������һ�����ϣ��ڴ��������DDR3������DDR4���������֧�ָ������ƣ�Ч�ʴﵽ95%���ϡ���о3A4000/3B4000Ҳ���״���Ƭ�ڼ���©��������ơ�Ӳ�������㷨����ȫ����ģ���밲ȫ���ʿ��ƻ��ƵĴ���������о3B4000����о3A4000�Ļ�����֧�ֶ�·������ |

|
|
8 Loongson 3A5000 ��о3A5000���ú���о3A4000�Ĵ�����ͬ����GS464EV, ����12nm������Ƭ, ��Ƶ������2.5GHz����о3A5000��Ȼ��4�˴�����������о3C5000����һ��16�˴���������о3A5000/3B5000��������˼����������������Ϣ�������ͨ�ô�������������о����ָ��ϵͳLoongArch��LA464�ṹ���ĺ˴�������������о3A4000�������������ż��ݵĻ����ϣ�Ƶ��������2.5GHz�����Ľ���30%���ϣ���������50%���ϡ���о3B5000����о3A5000�Ļ�������HT0�ӿ���֧��һ���Ի����Ա�֧�ֶ�·��������ͼչʾ����оƬ�ܹ��� |
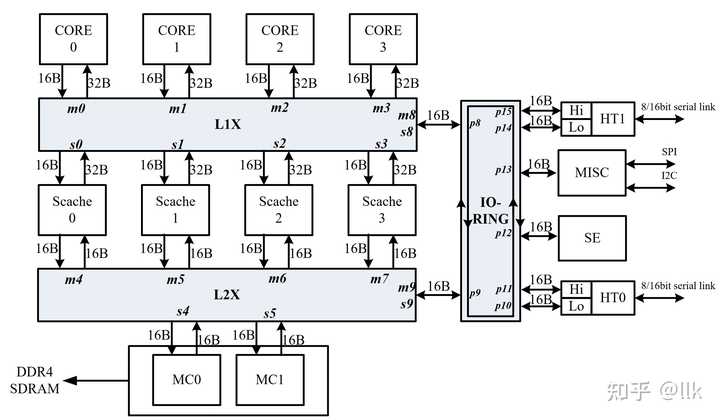
|
|
��һ����������5x5�Ľ��濪�أ�����4���������ˣ�4����������ģ���һ��IO�˿ڵ����ӡ��ڶ�����������5x3�Ľ��濪�أ�����4�������Ļ���ģ�飬�����ڴ��������һ��IO�˿ڡ�IO������һ��8���˿ڣ��ֱ�����4��HT�������������������ģ�飬��ȫģ���Լ��������濪�ء�����HT����������16��HT���ߣ�������Ϊ����8λHT��һ��16λHTʹ�á� ���������ṹ�����ö�д���������ͨ����λ��128���أ��봦����ͬƵ���������˺͵�һ�����濪�ض�ͨ����256���ء� ��ͼչʾ����о3A5000�������滮��ͼ�� |

|
|
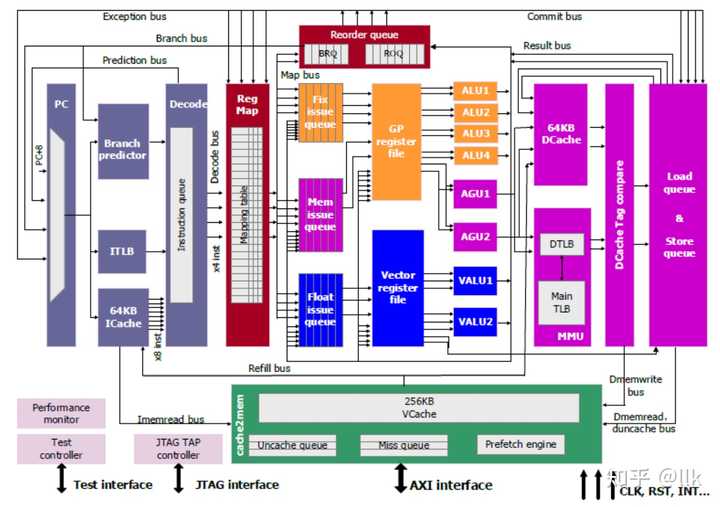
8.1 LA464�������� LA464��һ��4����ij���������������4�����㵥Ԫ��2��256λ��������Ԫ��2���ô浥Ԫ��ÿ��������Ԫ֧��8�������Ȼ�4��˫���ȳ˼����㣻�ô浥Ԫ֧��256λ�洢����.��ͼչʾ��LA464�������˵��ܹ��� |
|
|
8.1.1 �������� Scacheģ������о3A5000�ڲ����д������˹�����L3���棬����16·���������ɻ������ģ��ͻ������ģ����ɣ� �������ģ�� ���������Դ�������DMA�ķ������� �������ģ�� �����Ż����ǩ��Ŀ¼������ 8.1.2 SMP���� ͨ��HT���л����������2·��4·��8·��16·SMPϵͳ������ϵͳ������ַ����Ϊ48λ����ַ��4λ����ʶ���ڵ㣬ÿ���ڵ�ʵ�ʿ��õ�ַ�ռ���44λ����ϵͳ�ڵ���Ŀ����16ʱ����Ҫ����·�����üĴ�������֤û�ж�Ӧ�ڵ�ĵ�ַ�ܹ�������Ӧ�� 9 Loongson 3A6000 ��о3A6000����������о���Ĵ��ܹ������Ʒ������4�������з��ĸ�����6����64λLA664�������ˡ���Ƶ�ﵽ2.5GHz��֧��128λ����������չָ�LSX����256λ������������չָ�LASX����֧��ͬʱ���̼߳�����SMT2����ȫоƬ��8�����ˡ���о3A6000Ƭ�ڼ���˫ͨ��DDR4-3200�����������ɰ�ȫ����ģ�飬���ṩ��ȫ�����������ܣ�SM2��SM3��SM4�ȣ�Ӧ��֧�֡���3A5000��ȣ���Ҫ�Ǹ����˴������ںˣ�оƬ����ܹ�����ͼ��ʾ�� |
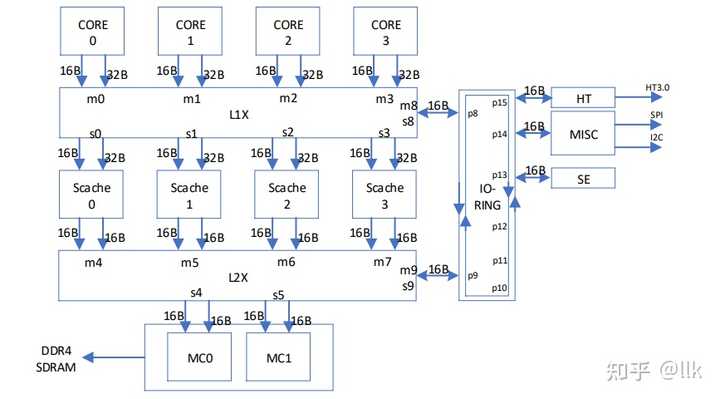
|
|
��һ���������� 5x5 �Ľ��濪�أ����������ĸ��������ˡ��ĸ����� Cache ģ�顢�Լ�һ�� IO �˿����� IO-RING�� �ڶ����������� 5x3 �Ľ��濪�أ����� 4 ������ Cache ģ�飬���� DDR4 �ڴ�������� �Լ�һ�� IO �˿����� IO-RING�� IO-RING ��������˿ڣ����Ӱ��� HT ��������MISC ģ�飬SE ģ�����������濪�ء�HT �������ڼ���һ�� DMA ��������DMA ���������� IO �� DMA ���Ʋ�����Ƭ��һ���Ե�ά���� ���������ṹ�����ö�д���������ͨ��������ͨ������Ϊ 128 λ���������봦���� ����ͬ��Ƶ�ʣ������ṩ���ٵ�Ƭ�����ݴ��䡣���⣬һ�����濪������ 4 ������������ scache �Ķ�����ͨ��Ϊ 256 λ�������Ƭ�ڴ������˷��� scache �Ķ������� SCache ģ������о 3A6000 �������ڲ����д����������������������档SCache ģ��֧��16 �����ʶ��У����� 16 ·�������ṹ��֧�� ECC У�顣 �� ������ģ ��������� �������ģ��scachemanage �������������ģ��scacheaccess��Scachemanage ģ�鸺���������Դ������� DMA �ķ���������������ı�ǩ��Ŀ¼�����ݵ���Ϣ����� scacheaccess ģ���С�Ϊ�����ģ���������ı�ǩ�� Ŀ¼�����ݿ��Էֿ����ʣ����� ����״̬λ��w λ���ǩһ��洢����ǩ����� TAG RAM �У�Ŀ¼����� DIR RAM �У����ݴ���� DATA RAM �С�ʧЧ������ʹ������棬ͬʱ��������·�ı�ǩ��Ŀ¼�������� ��ǩ��ѡ��Ŀ¼�����������������ȡ���ݡ��滻������ �������д������ֻ����һ·�� ��ǩ��Ŀ¼�����ݡ� LA664 �������� 64 λ�Ĵ������ˡ�����о 3A6000 �еĶ�� LA664 ���Լ���������ģ��ͨ�� AXI ���������γ�һ���ֲ�ʽ����Ƭ��ĩ������Ķ�˽ṹ��LA664 ֧��ͬʱ���̼߳���(SMT2)�����ĸ����㡢�ĸ��������ĸ��ô浥Ԫ��ÿ��������Ԫ����Ϊ 256 λ�����֧�� 8 �������Ȼ� 4 ��˫���ȳ˼����㣻 �ô浥Ԫ֧�� 256 λ�洢���ʣ����ַΪ 64 λ��������ַΪ 48 λ��һ��ָ�������ݻ����С��Ϊ 64KB��4 ·�������� Victim Cache ��Ϊ˽�ж������棬��СΪ 256KB��16 ·�������� һ������ʵ����żУ�飬������Ƭ��ĩ������ʵ�� ECC У�飬��֧��һλ������ �ο�����LoongArch-Vol1-v1.02Loongson 3A5000/3B5000 Processor Reference Manual - Multicore Processor Architecture, Register Descriptions and System Software Programming Guide, n.d.Wang H., Wang W., Wu R., Hu W., 2015. ��оGS464E�������˼ܹ����. Sci. Sin.-Inf. 45, 480�C500. https://doi.org/10.1360/N112014-00292Hu, W., Wang, J., Gao, X., Chen, Y., Liu, Q., Li, G., 2009. Godson-3: A Scalable Multicore RISC Processor with x86 Emulation. IEEE Micro 29, 17�C29. https://doi.org/10.1109/MM.2009.30W. Hu et al., "Godson-3B1500: A 32nm 1.35GHz 40W 172.8GFLOPS 8-core processor," 2013 IEEE International Solid-State Circuits Conference Digest of Technical Papers, San Francisco, CA, USA, 2013, pp. 54-55, doi: 10.1109/ISSCC.2013.6487634.W. Hu et al., "Godson-3B: A 1GHz 40W 8-core 128GFLOPS processor in 65nm CMOS," 2011 IEEE International Solid-State Circuits Conference, San Francisco, CA, USA, 2011, pp. 76-78, doi: 10.1109/ISSCC.2011.5746226.Gao, X., Chen, Y.-J., Wang, H.-D., Tang, D., Hu, W.-W., 2010. System Architecture of Godson-3 Multi-Core Processors. J. Comput. Sci. Technol. 25, 181�C191. https://doi.org/10.1007/s11390-010-9315-3Hu W W, Tang Z M. Microarchitecture design of the Godson1 Processor. Chinese Journal of Computers, April 2003, 26(4): 385-396.Hu W W, Zhang F X, Li Z S. Microarchitecture of the Godson-2 processor. Journal of Computer Science and Technology, March 2005, 20(2): 243-249.Loongson 3A6000 Processor Reference Manual - Multicore Processor Architecture, Register Descriptions and System Software Programming Guide, n.d. |
|
������û�ã����ý���6�»��μ�һ����ر��������ǻ�����о�������ٶ���Ϣ����¶�� �����õ��Ļ����Ǻų����¼�������о3a3000 4���ģ�����8g�ڴ棬500g��̬�� |
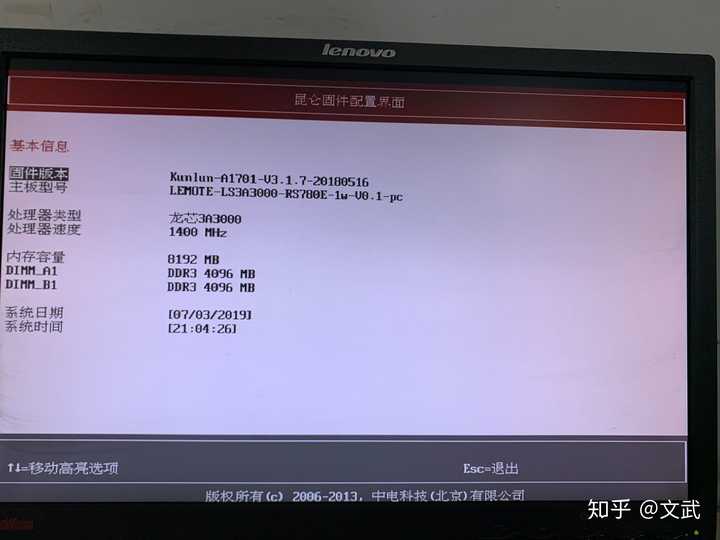
|
|
bios���濴���������ġ� ˵˵����ʹ��Ĭ��ϵͳ�����顣Ĭ��ϵͳ���б���������棬��������docker��Ҫ�ں�һ�������ڴ�ĵ���֧�ֻ��ɷ������汾������ϵͳui�����Ȳ��������ۡ� �����������ܣ�����ѹ������û�⼫�ޣ���jvm��������Ŀ����Ȼ��δ��ר���Ż�ʱ��gui�ͻ�������ۿɼ��Ŀ��١�ͬʱcpuռ�ü�������� ��Ȼ��Ҳ����ר�ŵ����ܲ��ԣ��Դ������ܲ��Խ����ʾ����fpu��쳲���������������mһ�¡� |
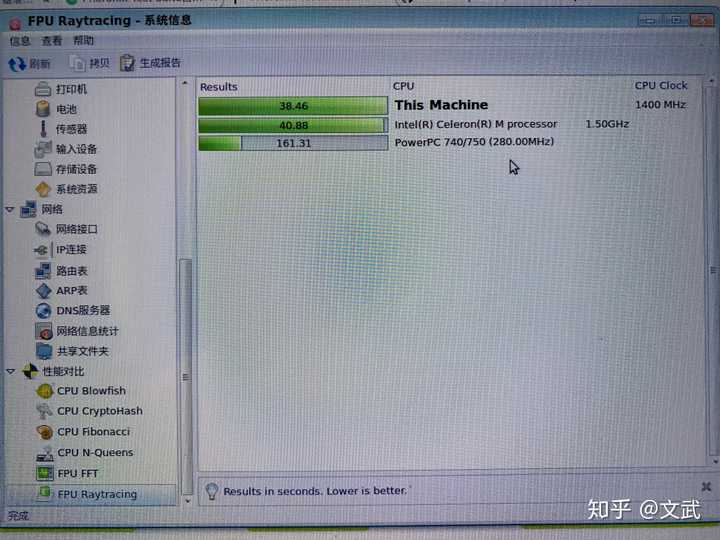
|
|
|
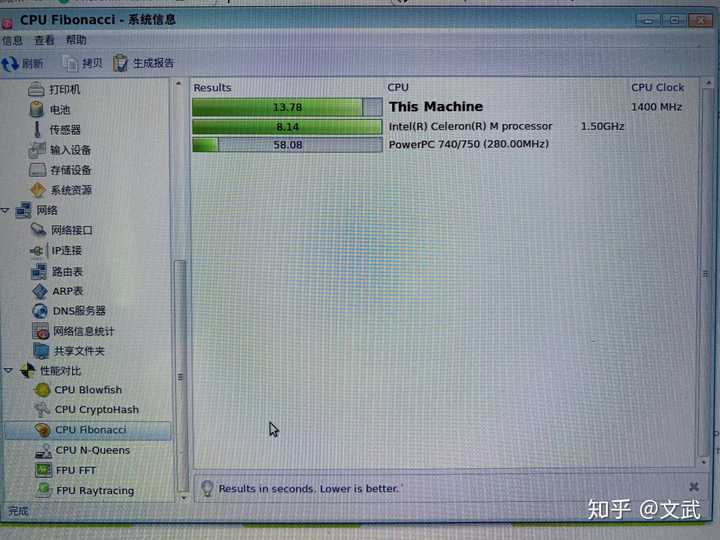
|
|
���Ծ�������ܸ���û�취����Ŀǰ�������������������Ҳ���ǻ��������ִ��������ύ�ȡ� ������һ������������Ϊ������ͻ����������߲���������Ͼ��㲻��ϣ���Լ���9012����ĵ��Ը�10��ǰ���ԸɵĻ ���ο�����ϵͳ����ڡ� �����������ض���Զ������Ϊһ���ϸ�Ŀ�������Զ��ϣ���û�Ϊ���������� |
|
|
| [�ղر���] �����ر��ġ� |
| ���� �������� |
| ������ۻ�Ϊ���ɵ��ԣ� |
| ��ο���С��Sky Nomad С����̣� |
| С��Ϊ�β����ţ� |
| codex��windows��������ֻ����wsl�в��ǡ� |
| Ϊʲô����û�е��գ� |
| ��ο���ij��touch����ƽ������������ |
| �������������� |
| ��23��������������Dz���߯���ˣ� |
| �Ż�Ӧռ����ռ�8������㣬���ϰ�װ��ʮ |
| С�������ĸ����ɹ��� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
|
��������:
��ӰƱ��
����Ȧ
����
����
����
�����
ӡ��
�ɼ�
��س
����
��ˮ
��Ǯ�ҽ���ר��
����
˫ɫ��
����ĸ��
����
ƹ����
�й�Ů��
����
nba
�г�
�ܲ�
����
���
��ɫ
�Ϻ��п�
80��
����: ���� �����ֶ� ������ķ�ȴ� �ʼ������� ����ͼ˹ ���� ����� ���� �ﰺ ����ʥ�ն��� ���� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ֪ʶ�� |