| |
|
|
|
| 知识库 -> 数码 -> 三星高管剧透GPT-5 高达 5 万亿参数,这对模型性能有哪些影响? -> 正文阅读 |
|
|
[数码]三星高管剧透GPT-5 高达 5 万亿参数,这对模型性能有哪些影响? |
| [收藏本文] 【下载本文】 |
|
GPT-5有 3-5万亿参数,由7000块B100炼成!这究竟意味着什么? |
|
5万亿是2200亿的22倍 如果计算资源是指数级增加的可能远不止22倍的gpu,按照这个逻辑估计就电费都付不起 所以如果属实模型肯定发生质变了,甚至可能不再是gpt模式 |
|
我家里放了一张4090,机器两万多块,跑了一个90亿参数模型,上下文增加到32k响应就会明显变慢,微调勉勉强强,训练之前要先降精度。吃瓜群众感慨GPT5有5万亿参数,我仰慕openai有一层楼那么多的显卡。 第一,目前GPT没法在产业上盈利。目前除了从投资人那里赚估值和投机的钱,GPT没法从产业中赚到钱,收费会员那点儿盈利连电费都不够。虽LLM的未来有无穷想象,但目前也只是想象。 第二,国内算力不行,被芯片卡脖子,但卡的不是很给力,华为计算卡不如英伟达,但差的不是很多,乐观点说,或许华为三年就能在算力上消灭代差。 所以,现在这个形势下,让openai砸钱,继续表演力大砖飞,替中国探探路,也没什么不好。2000年曾发生了“互联网泡沫”,如果今年美股没抗住,未来历史书上也有“大语言模型泡沫”。 |
|
想起一个笑话 “一个富翁不识字,便请来一位老师教自己的儿子识字。 老师写一画,说:“这是‘一’字。”写两画,说:“这是‘二’字。”写三画,说:“这是‘三’字。”富翁的儿子听了,说:“这还不简单,我已经学会了,哪里还需要老师。”于是富翁便辞退了老师。 没多久,富翁想请一位姓“万”的人来家里喝酒,便一早让儿子写请帖。没想到儿子写了很久都没写完。父亲去看,发现儿子正在“奋笔疾书”,一边写一边抱怨:“姓什么不好,偏要姓万!我从早上写到现在,才写了五百多画!” |
|
纯用户角度,GPT4也就这样 之前吹的说做本科题考研题啥的,实测一坨,积分都算不明白有时候,专业性稍微强一点基本上能把公式写出来就谢天谢地了 比如说自控,它知道流程图信号转换,知道求闭环传递函数的方法,也知道劳斯判据,概念啥的比我都懂,好了,拿来做题:根据信号流图求闭环传递函数,判断系统稳定性,直接就拉了 你说他不会吧,他能给你写一堆,但是仔细一看感觉过程都在瞎诌,拿来干活还不如simulink靠谱 目前大模型,啥都懂一点,啥都不精,娱乐性拉满 真要生产力还得是专门领域针对性的训练ai 当然,要是能MATLAB或者Multisim之类的软件能内置个ai,我一句话,给我图出了,哪怕不对我也手动改改能用,这妥妥的生产力提升,比什么虚了吧唧的大模型靠谱多了 |
|
未来的人工智能,人能参与其中优化的可能性越来越小了,感觉几十万亿的参数已经是人类能组装机群算力和语料库训练的极限了。再增加参数,任何一个优化都会跌入差不多的局部最优点。 参数架构想要继续优化,大概率只能和遗传一样,每一个版本随机突变一些节点,创造一个极限复杂的对抗环境或生存目标,让人工智能一代一代迭代下去,用时间换进化了。 而且真通用人工智能还看不到任何一个解决方案,自学习好像也只处在理论和实验室阶段。大家关注人工智能好像只知道GPT,实际上人工智能是个纷繁复杂超级学科(是个大坑),靠语料库训练的GPT只是创造一个文本处理的半神,他真不一定能思考怎么躲避危机等其他功能。 人工智能这个大方向可以做优化的方向太多太多了,大家只把精力投入到看得到尽头的GPT,其他没有那么闪耀,拥有更多可能性的方向就会被埋没掉。不要只关注冷兵器的发展,也要看到热兵器的无限前景。 |
|
这是一个非常可信的数字,因为最近发现两个信源都在证实这一点。同时也说明这个模型是个大麻烦。 |
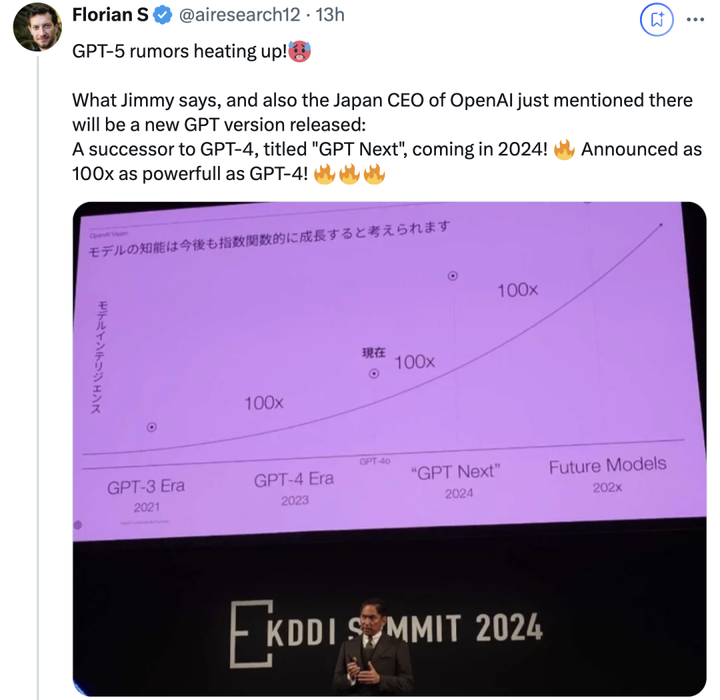
|
|
OPEN AI 日本CEO |
|
|
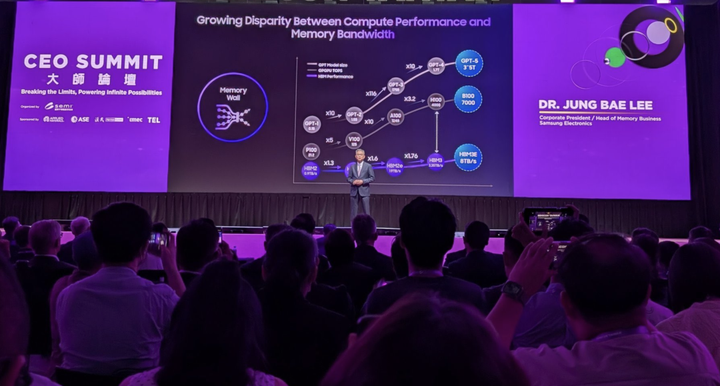
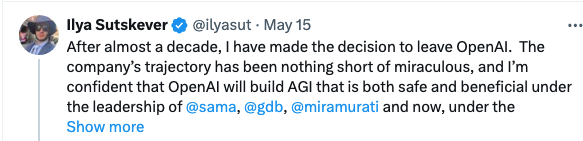
三星的 首先Ilya在2024/05/15离开OpenAI时发的Twitter表明,他已经看到了AGI的迹象,这个肯定是GPT-5或者它的后来得GPT-6或者更高的版本。所以GPT-5肯定是真的。 |
|
|
再有就是从Scaling Law来看,GPT-4是一个MoE模型,每个2200亿参数,16个Experts,合计是一个1.8T(万亿)参数的模型。所以,下一个Scaling Law的结点很明显是一个单一万亿参数的模型。最终的目标肯定是人脑的传说连接极限1000T(千万亿连接)。 所以,这个GPT-5高达5万亿左右的参数是一个极有参考意义的数字。但是真的要运行起这个参数量的模型来,恐怕是一个极大的问题。 Nvidia最强性能的GB200 NVL72(13.5 TB HBM3e),训练7000块GPU需100台GB200,成本约3亿美元(每台300万美元,未加价)。运行也只能依赖GB200 NVL72,因为分散到H100或A100会极其复杂。训练相对简单,OpenAI从V100到GB200经验丰富,但推理阶段的低成本优化是前所未有的挑战。即便量化到8Bit,模型仍有5T大小,4Bit也需2.5T,比GPT-4更庞大。GPT-4优化到GPT-4o耗时一年多,GPT-5可能需要更久。对OpenAI而言,这更多是工程挑战。 但是对于中国的模型团队来讲,恐怕面临的问题更多。 最直接的问题就是算力,很明显我们现在手里那怕是有万块A100的集群,也不太可能用来训练5T的模型了。这个300台的GB200,已经是万块A100的显存的2倍。更何况这中间还有一个很明显的利用率衰减。所以,这样一个算力现在对我们来讲已经是一个麻烦事了。 然后就是工程团队,相信这个只是个小麻烦。毕竟几个大的团队都是有万块GPU的集群经验了。所以这不是事。 数据,我坚定的认为某些行为已经造成了中文数据的自然分布的不完整性。这会给中文数据的使用带来极大的麻烦。它可能很难用其它语言翻译到中文来补充来解决这个问题。 所以,我们要建立这样一个规模的模型,短期内恐怕最大的可能居然是Meta的下一次开源?但是你真的相信那个商人味满满的马克・埃利奥特・扎克伯格,会把一个接近AGI的模型开源?尤其是当它很明显,小的组织及个人是没办法使用的情况下? 无论如何,这都是一个特别明显的信号:我们得开发自己的有竞争力的大模型!同时,这对于任何一个从事IT相关的人来讲,AI 释放的机会开始具象化了。 从现在开始,你每一天的努力方向,都应该转向AI,越早完成AI方向的知识积累,那就意味着自己越早变成AI时代的生存者和获利者。 毕竟在未来 AI 不一定取代你,但是会 AI 的人会超于你取代你。 有一说一,会 AI 的人才很值钱,尤其是程序员等技术岗位,但值钱的代价是你要掌握一个相对系统的有门槛的东西,这自学起来不容易,所以找到一个优秀的高效的学习资源是很重要的,可以看看这个大模型应用开发公开课,主要面向的就是想系统性学习AI大模型的同学。会体系化地介绍开源、闭源大模型的技术路径,以及在此基础之上的应用开发技术栈。像如何fine-tune模型、Langchain技术等等都会有全面涉及,能让你很快养成自己的大模型相关的能力与知识体系的建设,入口在下边↓ ??技术岗高薪必学:AI大模型技术原理+应用开发+模型训练 ¥0.00就业无忧 |

|

|

|

|

|
|

|

|

|

|

|

|
|

|

|

|
|

|
|

|

|
|
" style="display: none;"> 我呢,认真听了两堂课。听的是Transformer这个模型的介绍,也就是现在AI的基础与差不多全部了,听完你就能对Transformer有个不错的了解。你还可以在后续的课程中学习微调大模型以及构建自己的大模型应用。 反正呢,不要觉得可有可无,这或许就是你入局大模型的一个契机。 |
|
原本有点怕了 一看一堆卖课的 心安了 |
|
目前只有卖显卡和卖课程的挣钱了。还有很远的路要走。 |
|
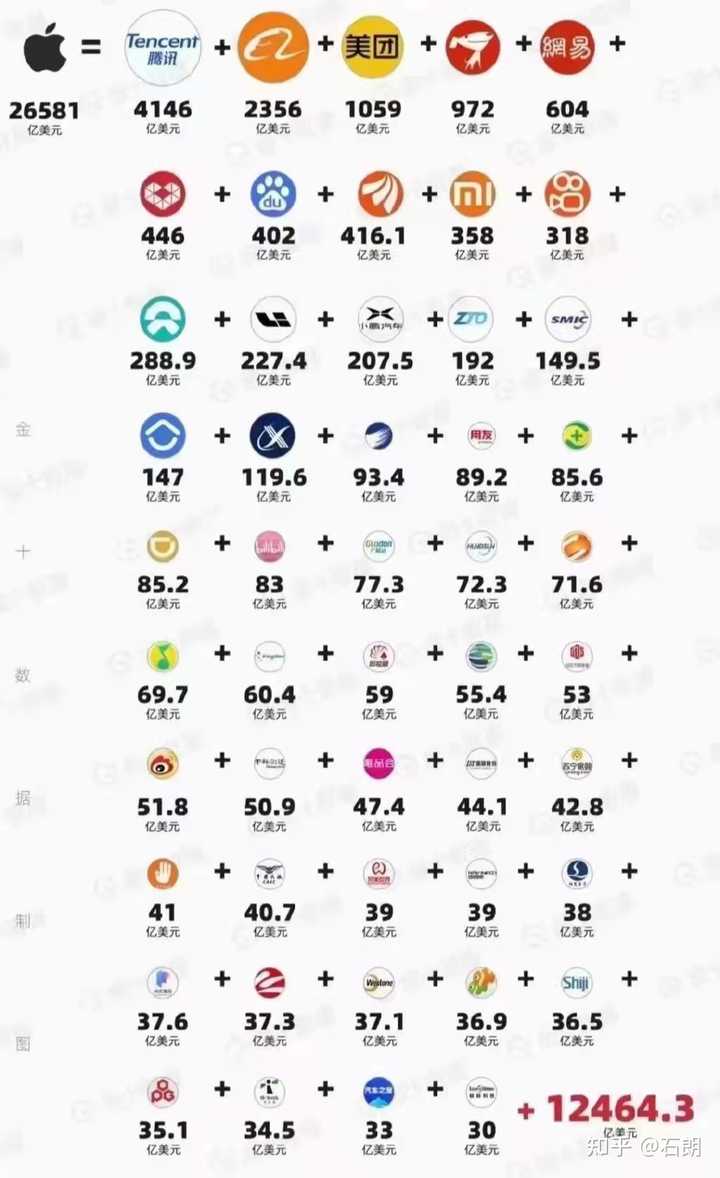
这下我们可怎么抄?但是我有一计,我们按兵不动,一定能遥遥领先! 首先,我们先把投入AI的钱抓紧投入的雄安新区的建设,然后再划拨200万亿,全力投入到雄安,完成基础建设。绿化率,美感,植物多样性都要保证,一定要漂亮! 然后首都开始把一些大型企业,人多的企业迁移过去,至少搬走1000万左右,这样北京常住人口就少了3分之一,然后交通,医疗,教育等资源就宽裕了,环境也变好了,空气也变好了,这样领导和专家心情都好了,心情好了,自然就可以着手开始搞AI这方便的东西,大概2750年左右,我们的AI是一定超过美国的,因为我根据央视报道的新闻,约翰霍普金斯大学的统计,美国的枪击死亡人数还是持续上升的,到2750年几乎就没人了,但是我们人多!就拿今年研究生毕业的统计来看,又是持续增高的!AI的研究需要什么!任何研究的基础归根结底是人,我们人多,他们人少,小小美利坚,拿下! 其次,延迟退休最大化,我们通过加班已经造就了一批20多家科技公司值一个苹果公司的成就,那如果加班+延迟退休最大化,也就是加班+不退休,毕竟我们骨子里就是勤劳认干服从性好的人,我们用命和他们拼,全民搞AI,每人都做算法题二叉树,递归遍历,我们用if else判断死磕transformer,虽然transformer它抬头,但是我们全量判断!这里我给各位写个示例代码: 这段代码的解读就是:假如你问我吃饭了么?可能有几百种问法,类似你是生活在上海的陕西人,你哪怕问到了“侬吃了甚”,这都被我提前判断到,你问出的任何问题都在我的if else判断之内,所以我们的CNGPT迅速做出回答。chatGPT它虽然5000万亿参数,平均到每个人身上也就几万个if else的判断,串休几天,轻松搞定~ |
|
|
最后,就是复合赛道超越,国外的AI现在都是再奔着逻辑的方向去发展,就像特斯拉车的视觉来应对路况,我们某大厂小厂都是怼24,48个雷达上去雷达探测,不是一样也卖的很好么?那么AI同理,虽然国内大多数模型,某度,某通,上来先去各种爬虫CSDN,爬完了没有答案就是没有答案,不给逻辑,不会也瞎回答,但是这是一个新的赛道,假如,我们用AI暂时先去GPT上问一遍答案,再中西结合一下,加上我们的话术,以GPT的答案做抓手,大力夯实,既要快又要好,赋能我们的AI,然后把融合好,润色好的回答呈现给用户,是不是更优秀的一种AI? 0924补充: 2017年,transformer论文发表,同一年雄安也开始规划 2008 年 9 月 28 日,猎鹰 1 号在马绍尔群岛的欧姆雷克岛 (Omelek Island) 上成功发射,08年《汽车产业调整与振兴规划》 |
|
感恩,只有他们能反复证明大参数模型比小参数模型给力,我们这种卖卡的业务才能活得滋润。 |
|
5G全球十几亿人使用,结论是没有实际应用,是个错误路线! 轮到AI,还在发展阶段,就已经是科技之光、人类的未来! |
|
知乎拿到通稿的速度比黄仁勋还快 |
|
大模型的玄学色彩越来越重了! 这天文数字般的参数是算法自己管理的吧 或许AI能产生自主意识的变数, 就藏在浩如星汉的参数里, 只是现在还不够多而已。 就如有机物到单细胞到多细胞… 再到动植物最终到智慧生物那样! |
|
居然有人天真的觉得 GPT 现阶段不挣钱,你仔细想想,你多少天没用百度与Google了,这就是为什么国内外的各种 GPT 免费让你用的原因。因为在科技领域,你永远猜不到,你的对手,来自于什么赛道。 就像国产操作系统与国产数据库,他们打破脑袋也想不到,把他们从半死不活的状态,拯救成为香饽饽的,居然是乌国。 |
|
没有任何影响!注意,我说的是任何! 准确的说,GPT甚至没把3.0时代的饼画圆。 真觉得GPT代表AI未来的人我问你一个简单的问题:GPT哪怕在安卓手机上实现了超过各家厂商语音助手的能力了么? GPT能与苹果的捷径,Mac的自动工作流,win,mac的脚本语言联动实现操作系统的补强么? 哪怕是现在的GPT能做到最简单工作的强检验么(即内容永远按照预设格式不会给出超出预期的响应)。事实上,横亘在GPT及其类似物上最大的问题永远是,其没办法哪怕是在最简单的AI问题上做到绝对正确,甚至没办法保证输出格式的绝对正确。 那么这个问题,GPT5能够解决么?这是通过加参数能解决的事情么? 笑死,哪怕是现在,哪怕是那些口口声声自己工作已经完全离不开GPT的,靠推广GPT赚钱的博主也无法回避一个事实:GPT需要人!准确的说,需要人作为输入,输出以及格式的检验,这点就决定了GPT只能做到人类的补强,而完全做不到程序流程的补强,但是说实话,现代社会……提高人的执行效率对于生产力的释放太微不足道了。 我的职业是程序员,直白的说,我们这个职业可能是全世界仅次于文学工作者最依赖GPT的职业了。经过这几年对于无数种GPT及其类似物的使用,我可以得出一个简单的结论:GPT能帮你提高效率,前提是你能提炼需求,GPT不能帮你解决你不理解的问题,原因是GPT解决问题的前提是你能理解并准确的描述问题,程序员世界的GPT等价与超高阶全局模糊搜索引擎,它足够靠谱的前提是世界上真的在某个地方有某个人合理的解决了这个问题,并且发布到了网上。 你完全可以争辩说GPT写的很多代码你在网络上都没有对应的源码,但是,相信我,只要你看过一次GPT给出的似是而非的答案你就会明白,就是这么个事儿。 |
|
这问题下的回答有点像五年前聊电动车。。。 新能源全行业在季度增长率20 30打着滚发展了.大部分人觉得是笑话 整个中国gdp的三分之一四分之一的资金 几万亿美元的掌管者砸向ai了 月薪万元的人觉得他们是傻子,是泡沫 分歧是宝藏的大门 |
|
我们要训练一个ai模型来训练ai模型 |
|
看了一圈回答,只要前三段里面有加黑加粗字段的,还有隐隐约约吹的,或者明目张胆吹的,直接拉到最后都是卖课的。 |
|
很多行业人都乖乖的,沿着欧美的技术逻辑路径思考问题,这都是傻逼。 哪怕用欧美人的思维也不必沿用二进制的芯片组和软件。 苏联人的三进制,还有量子计算,都是未曾深入开发的蓝海。 算力不会扯我大腿的问题,问题就是什么模式和底层芯片的运算规律。 人工智能比喻为需要到达目的地,距离一万米。 有很多方法和技术路线 一万米,可以蚯蚓打洞到达 一万米,可以用蜈蚣的波动法,走到 一万米,也可以青蛙蹦蹦跳跳,到达 一万米,也可以鸟雀飞翔过去,抵达 一万米,也可以声波到达 一万米,也可以超音速到达 一万米,也可以光速抵达 一万米,甚至可以空间折叠 ―――――――――――――――――― 人工智能,目的是为人服务。 为了探索宇宙服务,所以方法多的很。 目标从未改变,但方法一直在改进。 |
|
奥特曼不自己营销了,改成让别人营销了,看来股票还没抛完 |
|
还能说明什么? 说明人类需要量子通信和量子计算机和核聚变 不然现在所谓的AI才哪到哪? 不就是模型大数据吗 能模拟人脑的一个思考吗? |
|
如果消息为真,只能说明提升很大,其实现在的其实相当于力大飞砖。 以前的玩AI的,什么几亿参数都是觉得自己了不起了。但是到现在是属于小模型都算不上的玩意。所以当时200亿的ChatGPT 3.5一出作为核弹级别的大模型让大家眼前眼前一亮。所以暴力提升参数确实有用。GPT4令人失望的原因是其实模型参数没有什么大幅提升,主要是使用了蒸馏模型,等效参数提升不小,结果是OpenAI把牛皮吹过了。 最后,爆料5万亿真就5万亿吗,GPT-3.5上市的时候还不是一堆吹1750亿参数吗,最后微软论文曝光只有200亿。 |
|
22万亿参数,这个参数由谁来控制,一些参数的值有个稍微偏向性的定义就可能导致灾难性结果吧。这条路是不是走错了额。一个人能够保证一天核对正确1000个参数的值就很了不起了吧22万亿要消耗220亿个工作日,就是10亿人需要工作22天还要确保参数完全准确,出错概率太高了。谁能保证每个人的立场完全中立。这根本就不是人工智能 |
|
如果真是5万亿参数,那openAI的订阅费远远不足以覆盖成本。不缩小模型尺寸,倒闭只是时间问题。 |
|
如此强大的算力需要非常贵的硬件支持,还要消耗非常多的能源。 小时候看的『魔方大厦』有一集叫『鹦鹉博士』,gpt-5应该比鹦鹉博士强一点,但它的算法并不会产生真正的智慧,参数再多算的再快又有啥意义呢? 人类将如此多的资源投入到这么一个不环保的项目中去,不知道意义何在? 有这钱还真不不如花在教育上,非洲,南亚,拉美还有大批没办法接受现代教育的孩子,一张4090显卡的钱可以让许多孩子受到完整的教育了吧,培养出更多年轻科学家不比在已有的知识里瞎折腾更有意义吗? |
|
只要算力够强,ai就可以产生自我意识 但是算力太弱了,至少对于人类来说 人类的大脑相当于超级显卡,但是cpu,内存,硬盘都太拉了 这个超级显卡早就超越了语言可以描述的范畴,总而言之,就是比最先进的超算中心还先进,并且功耗极低 盲目发展ai或许真的会毁灭自己 |
|
GPT一天天就搞这些概念,现在sara都还没法用呢,GPT什么时候能用了告诉我就行. |
|
首先要看所谓的5万亿参数是指 MoE 的每个子模型有5万亿还是总共5万亿。如果说每个子模型5万亿,大概就知道现阶段这不是一个值得严肃讨论的问题。等有了证据再说。如果是说总共5万亿,那和现在的情况也没有本质差别,光从参数数量上看并没有给训练带来很大的新挑战。 另外知乎里这种 AI 新技术相关的问题下充斥着卖课的()()和满口跑火车的混子,所以提醒一下试图在这里学到一点东西的初学者,这些主要由 AI 生成 + 掺杂一些私货的答案基本没有参考价值。看到各种暴论要知道分辨,不要轻信。 另外吐个槽,某些又菜又爱装的混子,比如某个上来第一句就号称“4090显卡跑 90亿参数模型都勉强” 的()()。就这么简单明显的问题被人质疑后就开始疯狂转进各种狡辩。我的评价是此人的逻辑水平尚不如 90亿参数(9B) AI 模型的胡言乱语,大约能接近 20亿参数小模型(2B)的水平。 |
|
Bob Martin其实说的很对。 当机器像人一样思考,编程技巧将会过时 《新程序员》:我了解过您此前对 AI 代码的一些评论。在您看来,大语言模型有时还不错,有时也挺蠢的。虽然 AI 的代码解释帮了一些忙,但您仍然表态它不应该被盲目信任。 Bob 大叔:是的,程序员很容易过度依赖像 Copilot 这样的工具,看到它们生成的代码就不加批评地接受,这很危险。你需要保持批判性,虽然其中的部分代码还算可以,但大多数时候使用 AI 生成的代码需要非常谨慎。所以我的建议是,要小心,把它当作工具来使用,并且始终记住,如果使用不当,工具也会伤害你。 《新程序员》:那么,对于刚开始学习的程序员,他们应该如何利用 AI 成长呢?我曾经在采访中听到过两种截然不同的观点,一种是认为编程新手应该全面拥抱 AI;另一种是认为 AI 会毁掉初级程序员,因为这些人没有能力判断 AI 代码的好坏。 Bob 大叔:这就像初级飞行员不应该使用自动驾驶一样。请先学会如何驾驶飞机,然后再在不需要关注细节的时候使用自动驾驶。AI 也是一样的道理。初级程序员不应该一开始就依赖 AI,因为他们还不知道如何判断输出的代码质量。很多时候,那些代码不仅糟糕,而且就是错的,根本不能工作。 我真正担心的情况是,初级程序员接到一个任务,他们会选择用 AI 来实现。AI 给出代码猴,这些新手总是会想:“嗯,是 AI 给的,一定没问题”,然后丢掉工作。所以我的建议是,在职业生涯的前几年,甚至应该逐渐减少使用 AI。 《新程序员》:现在,越来越多的 AI 生成代码被用在不同的项目里。您是怎么在代码质量和生成效率之间平衡的呢? Bob 大叔:我的平衡方式是先使用 AI 生成代码,然后再清理它。我可不会让它往项目里面塞糟糕的代码。所以呢,如果 AI 生成的代码能用,还能通过我的测试,那我就会毫不犹豫地回过头来重构、清理并改进它。比如改变命名,提取一些函数,调整结构,诸如此类。 因为我本来就不指望 AI 能生成很棒的代码。所以我会清理它,把它变成我自己的代码。这样一来,它就是我的项目了,是我写的代码。 《新程序员》:大约五年前,有人问过您“软件工程中哪些趋势被高估了?”,而您当时骂了一顿微服务(Microservices)。五年后的今天,有没有其他被高估的趋势? Bob 大叔:现在被高估的趋势当然就是生成式 AI 了,毫无疑问。它是新生的事物,而任何新事物都会被高估。五年后,大家回头再看就会马后炮一句:“我们可能确实高估它了。” 这就是常态。 《新程序员》:您的老熟人 Kent Beck 在 AI 浪潮兴起的时候说过一句话。他说自己不情愿地使用了 ChatGPT,并发现自己 90% 的技能现在都不值钱了,而剩下 10% 的价值涨了一千倍。生成式 AI 到底有多大的帮助? Bob 大叔:说实话,我没觉得 AI 特别有用。在最简单的情况下,它还算有点帮助。比如当我在做一些很基础的编码工作时,AI 会给出一些代码,我会瞄一眼,觉得还行,就接着往下做了。接着,AI 往往会跟着上下文内容继续工作,直到一旦事情变得有意思起来,AI 就越来越不靠谱了 ―― 越是复杂的事情,它就越帮不上忙。 AI 可以处理一些小事,但如果我想让它重构和改进设计,就完全不行。此外,写测试的时候,AI 也帮不了多少忙。 原文https://mp.weixin.qq.com/s/k_keaUdp9E5bUuLV4nCI9w |
|
挺好,真要是这样AGI直接2025年实现,比预想还快了两年。 |
|
经常用AI的人会非常依赖它,离开它就会什么也做不了。 一件事,使用AI者首先需要考虑不用AI怎么做,后面用AI去优化。而不是一开始就让AI帮你干活。 |
|
如果性能还是没有比较显著的提升,是否意味着transformer的能力已经到头了 |
|
C4数据集的量真的撑得起这么多参数吗,一度以为LLM叠参数的时代要到头了,长远来看我还是看好Meta和立昆哥 |
|
所以这消息为什么出自三星高管之口? |
|
参数大战真是越演越烈!最近,三星高管的一句"剧透"又让科技圈沸腾了 ―― GPT-5可能拥有高达5万亿参数,还要用上7000块最强算力的B100芯片?这消息一出,立刻引发了业内热议。 说实话,这数字确实够震撼的。从GPT-3的1750亿参数,到GPT-4的未公开参数量,再到现在传言的5万亿 ―― 这增长速度,简直像坐了火箭。不过,参数量暴增背后,还真有不少有趣的话题值得聊聊。 首先,这么大的参数量意味着什么?简单来说,就像给AI装了个更大的"脑袋"。理论上,它能记住更多信息,处理更复杂的问题,甚至可能在推理和创造性方面有质的飞跃。但实际效果如何,还真得等模型问世才知道。 再说说这7000块B100的配置。作为英伟达最新的AI芯片,B100的算力确实强劲。不过,训练这么大规模的模型,光是电费就够吓人的。也难怪只有顶级科技公司才玩得起这种"豪华配置"。 但说到底,参数量也好,硬件配置也罢,都不是衡量AI能力的唯一标准。就像餐厅不是菜量大就一定好吃一样,AI模型也需要在架构设计、训练方法等多个方面同步提升。 【友情提示】 聊了这么多高精尖的AI话题,不知道你是否也对AI应用感兴趣?数标标API代理平台提供稳定的海外模型访问服务,欢迎各位开发者体验。无论是GPT系列还是其他主流大模型,都能轻松调用! 你怎么看这场参数军备竞赛?也许未来的突破点不在于简单地堆砌参数,而是在于如何让AI思考得更接近人类? {本文生成于gpt4o模型} |
|
|
| [收藏本文] 【下载本文】 |
| 数码 最新文章 |
| 如何评价华为鸿蒙电脑? |
| 如何看待小米Sky Nomad 小米澎程? |
| 小米为何不惊慌? |
| codex的windows桌面版真的只有在wsl中才是“ |
| 为什么微软还没有倒闭? |
| 如何看待某家touch会议平板拆开后里边是联想 |
| 如果雷军从政会怎么样? |
| 抽23个点的美团外卖是不是忒狠了? |
| 微信回应占储存空间8个争议点,承认安装包十 |
| 小杨哥和雷军哪个更成功? |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
|
娱乐生活:
电影票房
娱乐圈
娱乐
弱智
火研
中华城市
印度
仙家
六爻
佛门
风水
古钱币交流专用
钓鱼
双色球
航空母舰
网球
乒乓球
中国女排
足球
nba
中超
跑步
象棋
体操
戒色
上海男科
80后
足球: 曼城 利物浦队 托特纳姆热刺 皇家马德里 尤文图斯 罗马 拉齐奥 米兰 里昂 巴黎圣日尔曼 曼联 |
| 网站联系: qq:121756557 email:121756557@qq.com 知识库 |