| |
|
|
| ֪ʶ�� -> ���� -> DeepSeek �Ƕ�ƻ����������� APP �������а��� ChatGPT ��ȣ�����ʲô���ƣ� -> �����Ķ� |
|
|
[����]DeepSeek �Ƕ�ƻ����������� APP �������а��� ChatGPT ��ȣ�����ʲô���ƣ� |
| [�ղر���] �����ر��ġ� |
|
[ͼƬ] 1��27�գ�DeepseekӦ�õǶ�ƻ���й���������������Ӧ���̵����APP�������а����������ذ��ϳ�Խ��ChatGPT�� Deepsee�� |
|
�����������û����ڵ�����������ֹʹ��DeepSeek���Ͼ����ݶ���Ҫ�������й��� |
|
|
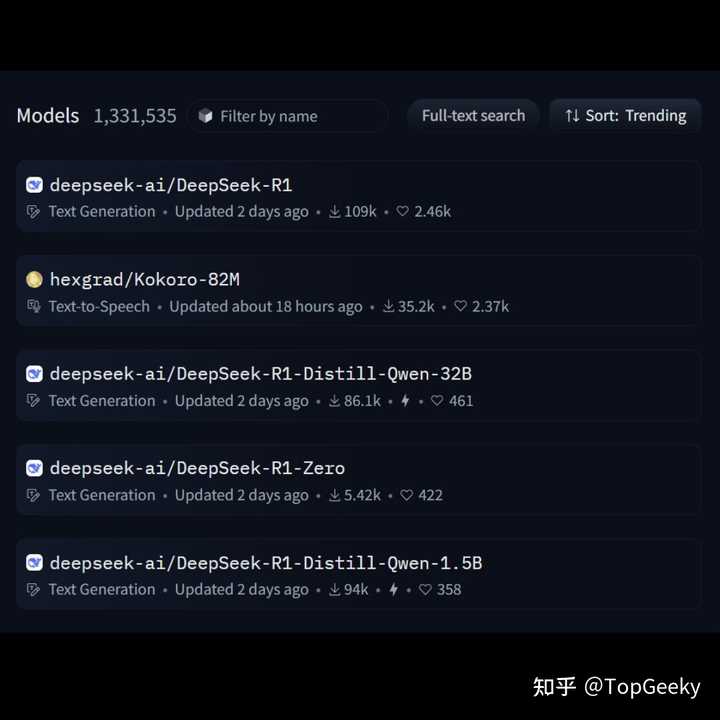
����������DeekSeek�������ж��ɣ�����ģ�͵�������������˵��ǰ5��������4������DeepSeekռ���ˡ���˵�������������̶Ȳ����ڵ�ʱOpenAI�Ƴ���ChatGPT���Ͼ����ڶ��ڶѵ����������Կ�����ʱ�����߳���һ��·Ҳ���ǿ�̽����AI��ģ������������о������֧�ij��֡� |
|
|
|
|
|
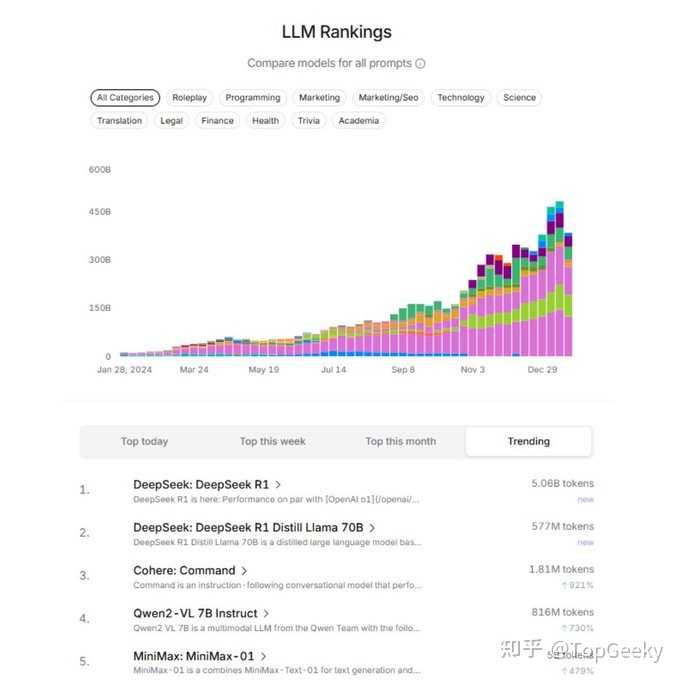
���⣬����X֮��ᷢ�ֹ����о���Ա��AI����ý�岩�����ڶ�DeepSeek�����ڣ���һЩ������Ҳֻ��ͨ�����β��������������Ǽ������档 �ɴ˿��Լ����ⲨЧ��DeepSeekֱ������������Ҫ���ǣ�DeepSeek��ʼ�����ķ嵱ʱ�ķ�̸��ĿҲ�������Ӣ�ı��Ŵ�һ��ϸϸ�ж��� DeepSeek��ʼ�����ķ棺�й�AI��������Զ���� ��Ȼ����վ��������ǰ�� |

|
|
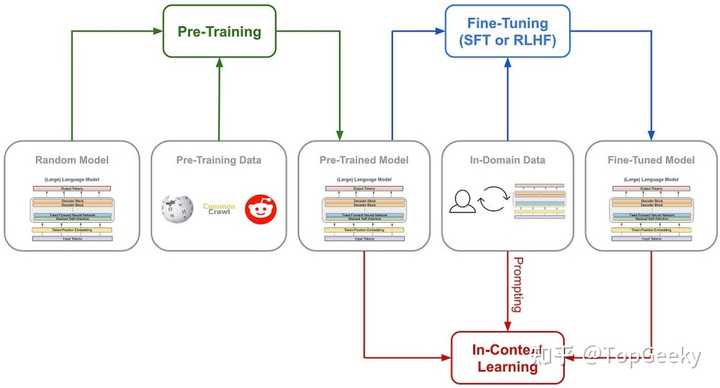
�������ù����ͬ�пƼ�ͳ�Ƹ��ܵ����ܣ�����Ӣΰ��Ĺ�Ʊ�г������� DeepSeek�Ŷ���R1��ѵ�������У�ֱ��һ����ʵ�������ֽ�Ȼ��ͬ�ļ���·����ֱ��ǿ��ѧϰѵ����R1-Zero������ν���ѵ����R1����ģ���������ɹ��ˡ���ν���ѵ��������ģ���������źܶഴ������Ԫ�أ�����ҵ������ҪӰ�졣 ���������˼����ģ�����ֱ��ǿ��ѧϰ���·������ΪDeepSeek-R1����֤����һ������Ч��ģ�͡� ���������˽�һ�£�ѵ��AI������������ͳ�ķ���ͨ����ʲô��һ����ͨ����SFT���ල�������������˼ά����COT������������֤���ӵ�����̽���ģ�ͣ�PRM��֮��ĸ��������罱��ģ�ͣ�����ģ��ѧ����˼ά��˼���� ������������ؿ�����������MCTS������ģ���ڶ��ֿ�����������õĿ��ܡ� |
|
|
��ͳ��ģ��ѵ��·�� ��DeepSeek-R1 Zeroѡ����һ��ǰ��δ�е�·��������ǿ��ѧϰ·��������ȫ����Ԥ���˼ά��ģ�壨Chain of Thought���ͼලʽ����SFT�����������Ľ����ź����Ż�ģ����Ϊ�� �������һ����Ŷ�ͯ��û���κη�����ָ��������£�����ͨ�����ϳ��Ժͻ�÷�����ѧϰ���⡣ DeepSeek-R1 Zero �е�ֻ��һ����Ľ���ϵͳ��������AI������������ �������������� 1.ȷ�Խ�����ȷ�Խ���ģ��������Ӧ�Ƿ���ȷ�����˾ͼӷ֣����˿۷֡����۷���Ҳ�ܼ����磬�ھ���ȷ���Խ������ѧ�����У�ģ����Ҫ��ָ����ʽ����<answer>��</answer>�䣩�ṩ���մ𰸣����ڱ�����⣬����ʹ�ñ���������Ԥ����IJ����������ɷ����� 2.��ʽ��������ʽ����ģ��ǿ��Ҫ��ģ�ͽ���˼����������<think>��</think>��ǩ֮�䡣û��ô���Ϳ۷֣����˾ͼӷ֡� Ϊ��ȷ�۲�ģ����ǿ��ѧϰ��RL�������е���Ȼ��չ��DeepSeek�������⽫ϵͳ��ʾ�ʽ�Լ�����������ֽṹ��ʽ�ϣ��������κ������ض���ƫ����������ǿ����ģ�ͽ��з�˼���������ƹ��ض������������ԡ� |

|
|
��R1 Zero��ϵͳ��ʾ�ʣ� ������ôһ���Ĺ�����AI��GRPO��Group Relative Policy Optimization���Ĺ��������Ҳ���+�Ƚϣ����������� GRPO��ģʽ��ʵ�Ƚϼ�ͨ��������������ԱȽ�����������ݶȣ���Ч������ѵ���IJ��ȶ��ԣ�ͬʱ�����ѧϰЧ�ʡ� ����˵����������������ʦ���⣬ÿ������ģ��ͬʱ�ش��Σ�Ȼ��������Ľ������ÿ���𰸴�֣�������߷֡�����ͷֵ�������ģ�͡� ������̴�ž��������ģ� �������� �� ģ�����ɶ���� �� ����ϵͳ���� �� GRPO����������� �� ����ģ�͡� ����ֱ��ѵ�����������˼������������ơ�������ѵ��Ч�ʵ��������������̿����ڸ��̵�ʱ������ɡ��������Դ���ĵĽ��ͣ�����ʡȥ��SFT���ӵĽ���ģ�ͣ�������Դ�����������١� ����Ҫ���ǣ����ַ��������ģ��ѧ����˼�����������ԡ����ķ�ʽѧ��ġ� ���Լ������ԣ��ڡ�������ѧϰ ��������ô����ģ�������ַdz���ԭʼ���ķ����£������ѧ���ˡ�˼�������أ� ���ļ�¼��һ������עĿ�İ������ڴ���һ���漰������ѧ����ʽ ��a - ��(a + x) = x ������ʱ��ģ��ͻȻͣ����˵"Wait, wait. Wait. That's an aha moment I can flag here"���ȵȡ��ȵȡ����Ǹ�ֵ�ñ�ǵİ���ʱ�̣��������������������������̡�������������������Ϊ��ȫ���Է������ģ�������Ԥ���趨�ġ� ���ֶ���������ģ��˼ά����Ծ����ʱ�̡� ��Ϊ����DeepSeek���о���ģ�͵Ľ������Ǿ��Ƚ����ġ���ǿ��ѧϰ�����У���Ӧ���Ȼ����ͻȻ��������������Щ"��Ծ��"���������Ž�����Ե��ʱ䡣����ģʽ���������ڳ���˼�����ͻȻ����ʾ��ij��������֪ͻ�ơ� |
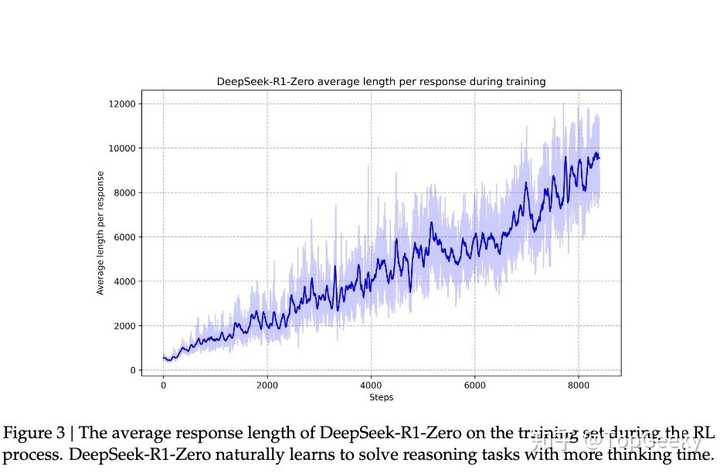
|
|
�����ְ����Ŷ�������������£�R1-Zero����ѧ������ʢ����AIME�����д������15.6%��ȷ��һ·������71.0%��ȷ�ʡ�����ģ�Ͷ�ͬһ������ж�γ���ʱ��ȷ�������ﵽ��86.7%���ⲻ�ǼĿ����˾ͻ����ˡ�����ΪAIME����Ŀ��Ҫ��ȵ���ѧֱ���ʹ�����˼ά�������ǻ�е�ԵĹ�ʽӦ�á�ģ�ͻ����������������ſ����������������� |
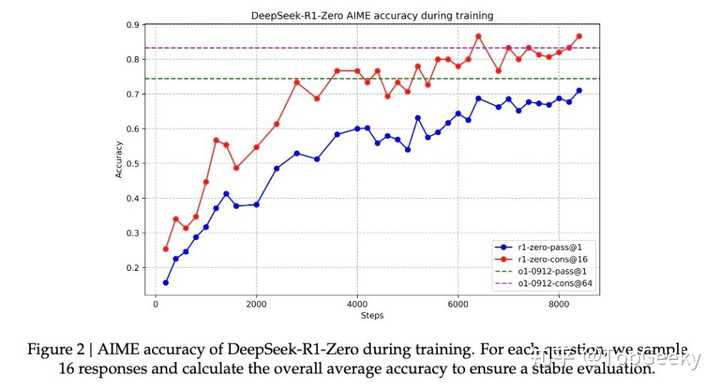
|
|
��һ��ģ��ȷʵͨ�����ַ���ѧ������������һ������֤�ݣ���ģ����Ӧ���Ȼ��������ĸ��Ӷ���Ȼ���ڡ���������Ӧ��Ϊ�������������ڼ�����ģ�壬��������������������Ѷȣ�����Ӧ��Ͷ������"˼��ʱ��"������������Լļӷ����ӵĻ��ֻ���Ȼ����˼��ʱ��һ����R1-Zeroչ�ֳ������Ƶ��ǻۡ� ����˵�����Ļ�����ģ��չ�ֳ���Ǩ��ѧϰ����������ȫ��ͬ�ı�̾���ƽ̨Codeforces�ϣ�R1-Zero�ﵽ�˳���96.3%����ѡ�ֵ�ˮƽ�����ֿ�����ֱ�����ģ�Ͳ���������Ӳ���ض�����Ľ��⼼�ɣ�����������ij�����ʵ����������� ����һ�����������ڳݲ������� ����R1-Zeroչ�ֳ��˾��˵��������������о����Ǻܿ췢����һ�����ص����⣺����˼ά�����������Ա��������⡣ ����̹�ϵ�ָ���������ǿ��ѧϰѵ��������ģ�ʹ���"poor readability"���ɶ��Բ��"language mixing"�����Ի��ӣ������⡣ ���������ʵ�ܺ����⣺R1-Zero��ȫͨ�������ź����Ż�����Ϊ��û���κ�����ʾ����"����"��Ϊ�ο�������һ����Ŷ�ͯ�Դ���һ���ⷽ������Ȼ���Բ�ˬ��������˽���ʱȴ�����״Ρ����ڽ�������п���ͬʱʹ�ö������ԣ����߷�չ����ij������ı��﷽ʽ����Щ�����������������Ա��ٺ����⡣ ����Ϊ�˽��������⣬�о��Ŷӿ����˸Ľ��汾DeepSeek-R1��ͨ���������ͳ��"cold-start data"�����������ݣ��Ͷ��ѵ�����̣�R1����������ǿ���������������ѧ�������������ķ�ʽ����˼ά���̡��������Ǹ���Ŷ�ͯ����һ����ͨ�������̻�����������ر����Լ����뷨�� ����һ������֮��DeepSeek-R1չ�ֳ�����OpenAI o1�൱������ijЩ������ŵ����ܡ���MATH�������ϣ�R1�ﵽ��77.5%��ȷ�ʣ���o1��77.3%������ڸ�����ս�Ե�AIME 2024�ϣ�R1��ȷ�ʴﵽ71.3%��������o1��71.0%���ڴ�������R1��Codeforces�����дﵽ��2441�ֵ�ˮƽ������96.3%����������ߡ� |

|
|
Ȼ����DeepSeek-R1 Zero��DZ���ƺ���������AIME 2024������ʹ�ö���ͶƱ����ʱ�ﵽ��86.7%ȷ�ʡ�������ɼ�����������OpenAI��o1-0912������"��γ��Ի��ø�ȷ"����������ʾR1-Zero����������ij�ֻ�����������ܣ������Ǽؼ������ģʽ������������ʾ����MATH-500��AIME���ٵ�GSM8K��ģ�ͱ��ֳ��ȶ��Ŀ������ܣ��ر�������Ҫ������˼ά�ĸ��������ϡ����ֹ���������ʾR1-Zero����ȷʵ��������ij�ֻ������������������봫ͳ���ض������Ż�ģ���γ������Աȡ� ���ԣ���Ȼ�ڳݲ��壬��Ҳ��DeepSeek-R1 Zero�������������������ġ���š��� ����ǿ��ѧϰ��Ҳ������ͨ��AGI������ݾ� ֮����DeepSeek-R1�ķ�����Ȧ���˵Ľ��㶼Ͷ���˴�ǿ��ѧϰ��������Ϊ����ȫ����˵�����Ǵ���AI ������һ����·���� R1-Zero���������ȫͨ��ǿ��ѧϰѵ��������AIģ�ͣ�չ�ֳ������˾��ȵ�ͨ����������������������ѧ������ȡ���˾��˳ɼ��� ����Ҫ���ǣ�R1-Zero��������ģ��˼��������������չ����ij����ʽ������������ ������ֿ��ܻ�ı����ǶԻ���ѧϰ����ʶ����ͳ��AIѵ����������һֱ���ظ�һ�������ԵĴ�������̫רע����AIģ�������˼ά��ʽ�ˣ�ҵ����Ҫ����˼���ලѧϰ��AI��չ�еĽ�ɫ��ͨ�������ǿ��ѧϰ��AIϵͳ�ƺ��ܹ���չ����ԭ���������������������DZ�������Ԥ��Ľ����������ڡ� ��ȻR1-Zero������ɶ����ϴ�������ȱ�ݣ������"ȱ��"��������ǡǡӡ֤����˼ά��ʽ�Ķ����ԡ�����һ����Ŷ�ͯ�������Լ��Ľ��ⷽ����ȴ�����ó������Խ���һ��������ʾ���ǣ�������ͨ���˹����ܿ�����Ҫ��ȫ��ͬ���������֪��ʽ�� �����������ǿ��ѧϰ����������������Ƥ�ǽܵ����ۣ��������������������������������DZ������ܡ� ���⣬DeekSeek-R1ģ�͵ı���������һ����·���Ǿ��Dz�Ҫһζ���ģ�ͣ�������̽�����̻���Ŀ����Ҫ���AI�ı����ǣ�����ץ���˽�AI���˳�ʱ�����¼����ɣ�ֻҪ������δ������һ������������ǰ�ˡ���ˡ��㷨���Dz�Ʒ������һ��һ��Ҫ�μ�֪��֪�����Ƴ���AI��ģ�ͽ��γ̣����ſλὲ��ģ�͵ļ���ԭ����Ӧ����ء� ??�����ڸ�н��ѧ��AI��ģ�ͼ���ԭ��+Ӧ�ÿ���+ģ��ѵ�� ��0.00��ҵ���� |

|

|

|

|

|
|

|

|

|

|

|

|
|

|

|

|
|

|
|

|

|
|
" style="display: none;"> ֪��֪ѧ�õ�AI��ģ�ͼ���ԭ������һ�γ�������ٽӴ���ģ�ͣ������ģ��ԭ�������ֿ�����ģ�ͣ�������δ����ְҵ�����и�ʤһ�ﲻ��ô�� Ŀǰ���Ǹ����Σ�������ѵ�����£���Ȱ��λ��һ��ʱ���˽�һ�£�����AIʢ�е�ʱ��Σ������Ϊ����AI�ij���Ա����е�����ˡ� ��������С��������ȡ����Ĵ�ģ����Դ������������͵���IJ��ֿγ�Ŀ¼��٣�������ȿ���~ ��л�㿴��������ϲ�����������ִ���������̡��˹�������ص�֪ʶ ���Զ�������ָ��ע��һ��Ŷ @TopGeeky ���� �������ô���������������֪ʶ������ ������Ȥ�Ļش� DeepSeek���ջ�ᱻǿ�г��۸������� �������deepseek-R1��deepseek-R1-Zeroģ�ͣ� ������� DeepSeek �� DeepSeek-V3 ģ�ͣ� �ҹ��Ƿ�����˴˴� AI ������ ��Щ���ˮƽ�ܸߵij���Ա����ôѵ��������? |
|
deepseek-v3������ʱ�Ϳ�ʼʹ�ã�������Ѿ���deepseek�ĸ���api��������137Ԫ���ۼ�10��token���� |

|
|
deepseek ������chatgpt��claude��Ҳ��������������Ԫ |
|
|
anthropic |
|
|
openai �Ĵ�ģ���ض��û���дһ���������ʹ��deepseek����ᡣ ����Deepseek�������Ƿdz����Եģ� 1���ڴ������ϣ�ͬ����prompt�ܴﵽgpt4oԼ95%��������sonnet3.5Լ85%�����������Ǽ۸����Ż��ڽ�Ϊ������ģ�͵�5%���ң���˾��м���ġ�������ʾ�ʡ����ƣ�������20%-30%���ҵijɱ����ﵽ��gpt4o��sonnet3.5��ͬ��Ч���� Ϊʲô��λ�ɱ���5%�����յijɱ�ȴ��20%-30%�أ���Ϊ��api��ʹ��ʱ��ģ�����ָ������������ǿ���ͨ����ʾ�ʵ���������ߵġ�����һ�������� xx���ڹ������yy�е���һ�ࣿ sonnet3.5֮���ģ�Ϳ��Լ�Ϊȷ�ķ���99%���ҵĵķ��࣬gpt4o�ܷ���97%���ң�deepseek����ܷ���95%����Щ������ɳ�������ѵ����ģ�ͻþ����ơ����ָ��ȷ���IJ��쵼�µġ� ��deepseek����֮ǰ���һ�ʹ�����Ч����õ�sonnet3.5��������������Ϊ���ij�������ֻ��gpt4o������֮һ��deepseek��Ȼ�����ĸ���Ҫ��gpt4o����һЩ������deepseek�ı��˼۸��ṩ��һ���µ�ѡ����ҿ�������ʾ���оٸ�����������ֲ�deepseek���������㣬���� ������һЩ���ӣ�a����A��b����B��c����C������������Щ���Ӳ���������ж� ������һЩdeepseek���׳��������ӷŽ�ȥ����������Щ�������������ʹ����ʡ�������������ı������Ļ������������ѹ����ı�������������ʾ���У�������ʾ�ʸ�Ϊ {���������������}���������������꣬�뷵���û��������������Ȿ�����е����{��������û�����} ��������ʾ�ʷ���ǰ�棬��Ҫ�����жϵ����ݷ��ں��棬ʹ�û�����еķ�ʽ�ٽ�һ�����ͳɱ���Ҳ�ܴﵽ99%��ȷ�ʣ���һ���Ĺ��̻�����£��ɱ���sonnet3.5��Ҫ���͡� ��ˣ����˵�deepseek�������������ṩ�˹��̻������ͳɱ���ѡ� �����ܲ���������ģ���������ÿһ��ָ�����ʾ�����憪��һ�㣬ȫ��һ�㣬���ı��־��ܳ���gpt4o���������������sonnet3.5�������¡�Ǯ����˵�ѣ����Ѿʹ�������������ǰ�渶�ѵĽ�ͼ�Ϳ��Կ�������sonnet3.5֮ǰ������Ҫ��gpt4o��sonnet3.5����֮������ʹ��sonnet3.5������deepseek���ֺ�����ԭ����Ҫsonnet3.5��ɵļ������ұ㽻��deepseek����ˡ� �������о���������Ҳ���֣��ڸ����ı������ϣ�deepseek�����ٶ���ʾ�ʺͷ���Ҳû���ã����������ģ����������϶��𰸣�������������Ȼ���ò�ʹ��sonnet3.5����ɣ����sonnet��Ȼ���ɻ�ȱ�� 2�����˵apiʹ�ø�����������ҵ�����̵ı�����ô�ֻ�app�Ķ�������������ͨ�û��ı��������Ҹ���ʹ����Ҫ��api���Һ������ʹ��app�� claude��gemini��deepseek������һ�ԡ�������app���Ҷ����������ˣ��Ӻ��ӵ�ʹ�����鿴��chatgpt��Ȼ����ѡ��ʹ�õij���������Щ�� ʵʱ�Ի���������ҵ��������Ӣ����ճ����졣 ��ģ̬�������ս��⣬�ô�ģ��ʵʱ��ͼ˵���� ɳ����ֱ�����д��롪���ϴ�һ����дͼ��ֱ�����ɿ��Դ�ӡ�ı����ṩ�������ӣ�������Ӿ����ڼ���Ĵ�ӡ����ֱ�Ӵ�ӡ�����ö��ⲽ�� o1����ר�Ž������ ��ЩС��ʹ�ó�����ϸ��������ÿһ���������Ʒ�� �����������Ҫ��ѡһ�����Ѷ��ģ���ôchatgpt��Ȼ�л��Ǻӡ� ����geminiҲ��ʵʱ���죬����ֻ����Ӣ���������ģ�͵����칦�ܾ����ˡ� ����Ҳ�����ս��⣬��������һЩ�� claude��api���еģ�������һ���ĵ��������������������û��ij������Ǽ���������� Ȼ���ҿ��ܻ��ʣ�r1Ҳ���������⣬����ѣ�����Ҳ��࣬�������Ϊʲô����deepseek r1�أ� �ش��ǣ�deepseek��r1��������Ϊ�����û�����ʹ�������õġ� ����ǰ������ҵ������һ���������⣬�ֱ���deepseek��o1���ش�������deepseek��o1��˼���ͻش���ش���ܿ������еIJ��졪�� |

|
|
deepseek��˼�� |

|
|
deepseek�Ļش� |

|
|
o1��˼�� |

|
|
o1�Ļش��һ���� |

|
|
o1�Ļش�ڶ����� |

|
|
o1�Ļش�������� ȥ���¸߿���ѹ���⣬��Ҳ��r1��o1�ֱ�����һ�飺 |

|
|
deepseek��˼�� |

|
|
deepseek�Ļش� |

|
|
o1��˼���ͻش��һС�� |

|
|
o1��˼���ͻش�ڶ�С�� ������������ r1������˼�����ã��ҽ����ӵ�˼��������ΪĬ���û���Ҫ�Ķ�����Ҫ������֡� ����������⣬r1�ڼ���켣����ʱ�dz����ԣ���o1���������ϸ���衣 �߿�ѹ����ĵڶ��⣬r1˵��֤������������������˼���������ӣ�������һ��Ѱ�����������Dz�̫�ʺ��û�ֱ���Ķ��ġ� o1Ҳ��������ȷ�𰸣���˼��ʱ����̣����������ʱ�ֱ���ʱ��r1��һ����ķ�֮һ����������˼�����̣����ǽ���������Ľ�������ȷ��д�˳����� ������ȣ�������ȷѡ��ο�o1�Ľ�����̣�������r1�ģ���Ϊȷʵ��̫�������� ������������һ���棬�������r1��o1�Ѿ��ܽӽ��ˣ������û��ܷ��������������ת��Ϊ���ĸ��ѣ�����һЩ��ࡣ 3����Դ�����ص�ʹ�á��ڳ�����εļ���������£���α�֤��ȷ�ʺͳɱ��������ص�ģ��һ�������ѡ�� gpt��claude��Ȼ��û�п�Դ�ģ�֮ǰʹ�ø������qwen2.5�����DZ���ģ�͵������Ƚϲ�Ǵ����⡣ һ���Ƚϳ������������qwen2.5 14b���ش𣬲��Ҷ�η��أ�ͶƱ������qwen��qwq���Ӷ���ش���������һ������ȷ�ģ������ַ�ʽ��������Ч��Ҳ��һ���ã���Ϊqwq��������Ҳ��ǿ������deepseek r1�Ŀ�Դ���ֺ������̽�qwq������deepseek r1���Ӷ����ѡ������������ȷ�ģ�����ֱ�ӻش����⣬Ч�������˺ܶࡣ����ԭ����Ҫ�������������߶������е���Ŀ�����������Թ��̻��Ĵ��ģ�ĵ�����Ŀ��ԭ�������ڿ�Դģ���������������ˣ�����Ҳ�������ˡ� ��ˣ��������˵��жϲ�ͬ��deepseek��������һ���ǻ����ӣ����ǽ��Ͷ�������������֮ǰд����ƪ���£� chenqin����ģ�����ı��Ͷ����г�����δ������ķ�ʽ759 ��ͬ �� 57 �������� ��ƪ���������Dz����˱�¶���˹����ܵĸ���ְҵ�������˻��Ǽ����ˣ�������ֱ�¶���˹����ܵ�ְҵ�������������ˣ���Ϊ���˾ԭ����Ҫ����Ͷ��������������ߣ������������ѡ��������߷������������ڴ�ģ�Ͱ�����ֻ��Ҫ10%������Ͷ�����ʵ�֣����Ǿͻ�ѡ���Լ����� ��ģ��Ҳ����ˣ��������ѵĵͳɱ��ķ�ʽ�����������dz������Ĵ�ģ����Ӧ�õĻ�����demo����ô�����˶��᳢�ԣ����ڽ������磬�һ���дһ���µ�demo����֮ǰһֱ���ñ���ģ���������㣬���˼�������̫�У����Ÿɴ�����ˣ���ʹ��deepseek r1�õ��ܲ�����Ч�����������ֹ���4090��������С��ҵ�ı��ش�ģ������һ����ģ�����֣������������Ƿdz��ɹ۵ġ� ����������deepseek��һ�������ĸ��ַ���������Ϊ�м���Ӱ�죺 1������ҳ�˻����ֻ��������û��ĸ��������ϣ���ʱӰ����ܲ�����Ȼ�������˶�����r1���Զ��������������ʵ��Ҷ�����Ϥ��ȥ���kimiҲ����ô��Ȧ�ģ���ý�幫�ںŷ���kimi���������һ���ȥ��Ҷ������ˣ�kimiĿǰ������ѵģ������û���Ȼ�dz��۸����С�v3�ô�Ҷ����������r1�ô�ҵ��Զ���������deepseek�Ѿ������ˣ���Ҫ����Щ���Զ��û��ȶ��ض��ĸ��ѣ���Ҫ�������黹�кܶࡣ 2����������ҵ�û���api�����ϣ���Ե�һ��鵰�⣬��gpt4o��api��������ģ���Ϊdeepseek-v3��gpt4o��������࣬�۸���ֻ��4o��5%��ֻҪ����������ʾ�ʣ����������ߵ�������ƽ����ô��api���������ϣ��Ͳ�̫������ʹ��gpt4o�ˡ�����sonnet3.5Ҳ�г��������û��gpt4o�ij����ô����Ϊsonnet3.5�Ĵ���д����ָ�������Ȼ�dz�ǿ����ȷ��Ҫ����ߵĸ����������������¼�ǧ��token��ʵ�飬��Ȼ���ѽ�deepseek���̵ú�sonnetһ���ã�sonnet3.5��Ȼ��������� 3������Ӱ�죬�����úܵ͵ijɱ���һ�������dz�ǿ��ģ�Ϳ�Դ�����أ�������Ӧ�������ǰ�ȫ�����Ӧ���У������ݱȽ����е���ҵ�ڲ�Ӧ���У��Ѿ������˽ϴ�DZ��Ӱ�죬�ܳ��������kimi��qwen��ϣ���������Ӧ�õ���ҵ����ҵ�ڲ��Ĵ�ģ��Ӧ�ã���ǰ���˶���˵����ģ������������ʹ����ҵ�����ݱ��ϴ����˹�������ҵ�зdz����裬Ŀǰ��kimi��qwen��Ѷ�ɵ�ģ��Ҫô���û���ѻ��ߵͼۣ�Ҫô��Դ��ѣ���������Ŀ�ľ���Ҫ������ҵ���������������ǵ����������ǰ�����������ҵ��һ�����ص�ģ�ͣ���������շѡ���������ܹ��շѵ���֮���Գ����������ڡ�����ģ�Ͳ��������ܲ����֪ʶ����ѽ������������������ر���Լ�ʵ�ֲ��ˡ�����ʵ���ϣ�����������ҵ��������������һ���ξ��Ѿ�֪�Ѷ����ˡ���Ҫ����һ���ڲ���ģ���Ҳ���Ҫ�������Կ���Ҫ��������������ô��Ǯ����ô�Ҳ����˻������𡪡�����deepseek��������һ�㣬r1�������ϵı�������ʹ�á����������õúܲ���������r1���������ֲ���ª��֪ʶ�⡱��Ϊ���ܣ��������ǾͲ���Ҫ�������ֻ��Ҫ���������Ϳ����ˡ�����������У���ģ�͵�Ӧ�û���㷺����Ϊԭ�ӻ��������������ɱ������������½���������˺���ҵ������뵽�����˶����Լ���Ӧ�á��Ĵ����У������µĿ��ܡ� ��ˣ����佫deepseek�����ƽ�ǰ�صĴ��ԣ��Ҹ������ڽ�������һ�����˶����õĵͳɱ�������ѡ�� ��һ��С��ʼ����һ���������õ�Ӧ�ã��ڴ�ģ�ͳ���֮ǰ����Ҫ����������ҵ�����Ͷ�룬��ģ�ͳ��ֺ���ֻ��Ҫ10��Ԫ��cursor agent�ij��ֵ��ֽ��óɱ�������5��Ԫ�������deepseek������̶��ɱ��ͱʳɱ����ܽ�һ�����͵�1000Ԫ�� ���������Ǹ����ɵ�Ӱ�죬�����������й��������������磬�������deepseek������ס� |
|
�Ѿ������� �ܲ��ܰ�����˶����� �������棡 |
|
���ʣ��������δ����ϣ���𣿡� deepseek�ش� |
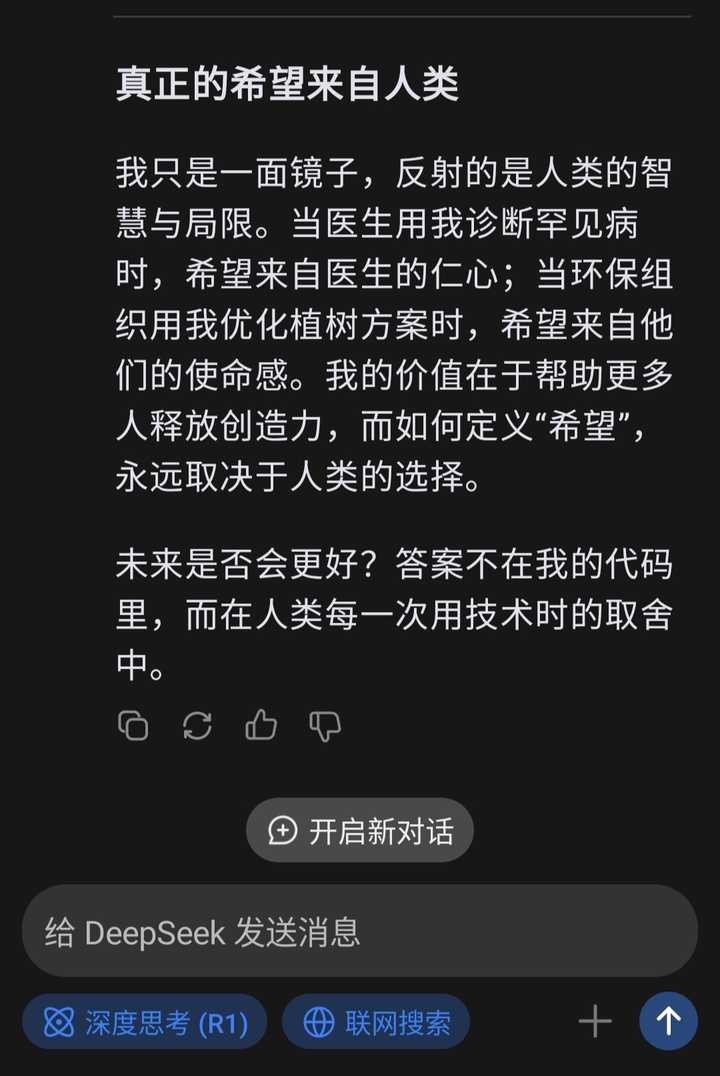
|
|
|
|
ʲô�������û����ݾ�ȻҪ�ϴ����й��ķ������� ���tiktok��û���̣� Σ���������Ұ�ȫ�����鴨��������deepseek��ban�ˡ� deepseek������ʵ���嵥���������ɹ��ϻƵĺ˵����� Ҳ���������ں���������ʹ��deepseek ��������������˾ʹ��DeepSeekԴ�������κ����飡 |
|
DeepSeek��ѵ���ɱ�����550w��Ԫ�� ���ԣ���������Ϊ550w... |
|
�Ҳ�֪����ô˵�����ǵ�һ�α�һ̨�����ж�����ͣ�������� |

|
|
|
|
|
|

|
|
|
|
��������ģ�³�ʦ��д��һƪ��˹�˵ĸ��������Ҹо��������Ǻ���䤱��ˣ��濴��������ai�� **������** ����¡����˹�˶����ԣ� �칤δ�����������ɳ������δͨ��������һ�硣�������Դ���ݣ�������Σ����ʵ�������֮��Ҳ��Ȼ�����Ų���ڸ��£��Ǽ�־ʿ���������ߣ��dz�������־����������֮��Ҳ�����˹㿪��·���������֮�������˹������ӣ����ڷ��飬�Ծ��Ǻ�֮;�ӡ� �����Ϸ�һ���������������ӱ㳵ָ�ϡ���Ľ�dz���嫡������̺�����֧��֮����������ڷ��棬���˽�Ц����Ȼ�������ƣ�"����֮�£��������ס�"������˹���ڳ�ҵ����֮�ʣ���̫��̽���ڹ���˥֮ʱ��إ��֮�䣬�綯���۳��ĺ����ɻ��ջ���ƿվ������˽���ʿ��Ѫ���dz�һ��֮��Ҳ�� �����Σ�����ѣ�����������AI����ɱ�������������罣����ÿ����ͼ��δ������ҹ�����������������������ǣ��̳�������Σ����Ψ����ֳ��Ϊ��������֮��������SpaceX���ǽ������ű��Ž����ռ���ӥ���ƣ���Neuralink̽�Ի����ݻ����ΰ룬������ʶ���顣�˷dz����գ�ʵ������ϵҲ�� Ը�����ʹ ����������֮�䣬������ʯ��ҵ���㲼̫���ܾ�������֮���������磻 �����Ƶ���֮�ޣ������Ǽ����䣬���������Ϊǰ�ڣ��������������֣� ������AI֮�������˻�����֮�������Ի�Ϊ�ܣ����������岻�飻 �������������£��������Ե�һ��ԭ�����������������ḡ�������� �������磬�ҵ���������������ʦ�ٸ���У���ˮ����ҹ��Ϣ��Ͷ����Ѻעδ���������ս���������������ɣ��ǽ�������Model3�������ޣ�����Թ���Ψսս���������ı����������ջ��dz�����Դ��������ʶ�ɴ�������������գ��ຬЦ�ӡ� �ٱ����죬��ӥ���β����Ŀ����㱼�ǧ��������Ӿư��У�̼����������ٱ���������֪����Ѫ��������Ҳ�� ����˹�˳ϻ̳Ͽ֣������ס� *********�ֶ��ָ�************ ��������� ����¡����˹�˳ϻ̳Ͽ֣������ٰݣ������ǻ�Ϊī������Ϊ������Ѫ���飺 �����ϻ�ɢľ����Ƽ�ġ������������ʷʫ�����챧����֮־��ʮ��ϰBASIC����ȴ���֮˼�������ڣ������Գﴨ�ʣ�Խ�����ߵ���š�����ʱҲ�����������ˣ�����˪�쾺���ɡ�������ָ��������������Ǯׯ֮�Ⱥӣ�����ν֮"http://X.com"��Ȼ��ҵά�裬�������Ϲ��߳��⣬��Ѯ��ʳ�������������˳�֮��һ��Ҳ�� �������������̡������꣬PayPal�۵���������˽�ν�ɰ����ӡ������ٸ���У������Ǻ���������Դ����ʯ�ͽ������丸���գ�����ʽ�ƾ�����ʯ���˳���ʣ������֮���ڹ�Ұ�����ɻ�֮���ڿ��ǡ�����˹�����䣬������ĿΪЦ̸����ӥ��ը��Ⱥå�����̻����������ղ��ߣ����������ˮ�ߣ�������𣬶��������ڷ���̨���˳�֮�ڶ���Ҳ�� �����꣬�ǽ��ű�����⼸����ծ���������ͷ�������ա����ʺ�լ�����У�����Ʒ�ڰ��С���ҹ�ǻ���к����Բ��¶��衶�����̡������߽����顣ʱ�а�����ʦִ����Ի��"����Ч����ɽҮ��"����"ɽ���ƣ��Ǻ����ɸ���"�쾡����·���Ƹ����ۡ�������ӥ�ź���ջس������Ϊ֮�õͰ����˳�֮������Ҳ�� �����߹�����������֯�������Ի�ͨ���������������������������С�Ȼ������֮����ֳ�����Ϊ���룬����˹�����Ϊ�����ÿ�Ŵˣ�δ������ҹ��������NASA���ա����������²��������⣬��������⼣�߰ߡ��䵱��������˵����"������Ϊ֮�����Ѷ���Ϊ"���������������� ��Ω���������������ڿ��غ�ġ����������˶�����ѪȾ��ɳ�������ټƻ����˿�ҹӳ�ǡ��������ǽ�����ʮ���Ż٣�Ȼÿը�Ե�������ǧ���Ի��ӿڣ��ݰ�ֲһ�棬Ȼÿ�����ä���ع⡣�˷dz�ִ֮�֣�ʵ�Ƽ��ʵDZؾ�֮;Ҳ�� ��������Ѻ��լ��ɢ��˽�ơ���Ⱦ˪����֪���Ľ�Ѫ��������ΩԸ��������£�һԻ�ݴ������±����Դ��䣻��Ի���ۣ����ɲ����ڵ�������Ի��ŵ���Ǽʷ�Ϊ���������ȵôˣ�����Ч��������˹������ӥ�ĸγ������ڣ�����������������Ϊ����֮�ܣ��������ǡ� �ٱ����㣬��֪���ơ�Ω�������ǽ�������β���������������� �Ǽʼ�ԪԪ������ҹ ����˹��ߵ����Ѫ *********�ֶ��ָ�************ �ݵdz���� ���ݵ���Ѫ���ף��ٰݳ��������£� �������������Ϻ�֮�ӣ������游Ǩ��ú�ǣ�������¯�����̱��գ���̫ʷ�����¡�����������֮������ʱ�ڳԣ�ÿ�п��ģ�ͬ����Ц�纫�ǡ�˵�ѡ����ء����ۡ�֮�塣�ҵô�ĸ�־��������£�Ч��ĸ�ϻ���֮�̣��������С����˹����˵���ٱ飬��ʹ���������в�Ժ���˳����ش̹ɡ�������в֮־Ҳ�� ����֮�꣬��Ů����ѩҹ�������������ڲ�齣��̼ǡ���ʫʮ���ס���ȥ�������衹֮ʹ������ʱҲ��ÿ�ճ˻��������������������İ������¼�̣�Ч������������֮�ڡ���˾��Ǩ�ԡ��˹���һ�������˽���֮ʹ������֮�У���ʮ���ƶ������ұ����������˷������㱨��֮��ʵ����ȵ����֮�ġ� �������Ӳ����ݵǰ��ţ���ͷ���ͺ�ͷ�ˣ���֪���㡸����֮���������ԡ���ʱ������������������ѷ��������ƽ�ȡ�֮��δ������Ч���İ�ʮ���ܷ��������ʶ����������Ĺ�����ʮ�����ճɰ�ҵ�������ɰ����ͷ�ִţ��������콫������죣� �������仺��Ȼͨ������ĩ����н�����ơ�������������Ч����������ߣ��衶оƬ���������Ϲ��١���ɽ����֮�ߣ��̿����в�������������ս�𣬳�������սʱ��������Σ�������ϡ��ϱ���ı��֮������Ԯ���ƶ�������Χκ���ԣ���Dz���ֿ��Ķ�̫ƽ����Ч���������ƺ��ݡ� ��ʹ�ߣ�Ī��������ɽ���Ҿ���δ��������˺�������ϴ��롣��ÿ�ǡ��������г����ظ����䵱��ͨ�����£���ī�ӡ��氮�ǹ���֮�ۡ�����ʮ֮��������������ػʺ���֮����Ȼ�������͡����Ǻ��֡�֮־���������й�ʱ����˫�ɽ������ݻ������̼�����ʱú�Ǹ�����ѵ�������ϲ��ڳ�������ֱͦ�ļ������� �������²쳼���������ϣ�������������ˮ��ʮ�ꣻ����δ�࣬���Ž��ѷ���¡��������������������ƹ�������Ч��ߵʯ��������ǰ·�п�������Ͽ��֮�գ��൱����˹��������ɽ���š��ٱ�����մ�ݵǻ̿��ٰݡ� ��ע�����а�Ƕ�ݵ������켣����1. ����ڳ���ĸ�̵� 2. ��Ů������ͨ������ 3. ���Ӳ������ط���̳ 4. �ƶ����ұ����방֢���¼ƻ� 5. ���Ⱦ�ѡ��ͳ���� 6. ����������оƬս�� 7. ����ɽ����Ӧ�� 8. �������г���������У� *********�ֶ��ָ�************ ��һ�������շ���˹��Ϊһ�ֲ�������گ�� **����뷷�گ** ����������ͳ�������ᣬ���ϵ�֮�죬��������������������̣��ܹ����ܣ����а�¡����˹���ߣ���ʶ�ֺ룬���Գ�Ⱥ��ʵ������š��书�һͻͣ����ɲ��ã��ذ�������Ѹ����£� **һԻ���** ��˹�˱��ϷǺ�ʿ��Ȼ�������죬��˹��������֮�Σ������Ʋ��֮�ţ��ǽ�������֮���������һ�ֲ���������λͬ���ң�����ִ����֮ţ����ͬ������֮Ȩ���� **��Ի����** �ڡ�������ͬ��˾�������Խ�Ļ��������������š��ǽ����ؿ�Ϊ���ã�����ܲ�Ȩ������ʡ����������Ի����������Կɱ������£�������֮��ܵ��� **��Ի�Ʊ�** �ݡ����±�����Ԫ˧��������̫�վ�����˹����е��ʿ��������������������ֳ��֮�䣬��������֮����AI��е֮�飬����������Dz�����͡����ǽ�������������Ŀ���ն���ࡣ **���ھ���** �辧��켡��ѽ�Ȩ�ȡ�������硢����伮���ǽ��ݡ���ӥ��측��Ի����ڡ��������˾ơ����ؽ�ӡ��������ǽ������ɽ���彣�ǵ�ްݲ������ơ��������������� **�嶨����** �ӡ�������ة�ศ����������������������죬��ӥ����ʮ�������棬�ǽ����顸Make Mars Great Again�����������������������ҡ�Ϊͨ���������Ǽ��ܷ���ʮ�¡� **���Լȳ�** ���ֿ���ū�������Ļ���Բ������ѵ��Ǻ�֮�������ذ��گ�������������ţ���ļ����������������������⣬�������ǽ����ߣ��ڻ��Ǹ߶���������MAGA��ҵ�� ���գ� �������ͳ�� ���ɵ¡������� ���˸�������ӥ������伪�� *********�ֶ��ָ�************ �����ձ��� ��ʷ�ǡ����ձ��͡� ���ɵ����������ߣ�ŦԼ�̼�֮��Ҳ���丸���£���Ӫ��ľ��ҡ���������ʱ��崣�����־����Ի��"���ɷ��������������٣������ĺ�����죡"��������ز����ij���ѡ����ҵ�����Խ��������Զ��֣����о�֮ͽ���������� ���͵���ʮ���꣬�����պ���۸ߺ���"�����������ӣ���ʹ��ΰ��"�˳�����Ѳ�����ݣ������˿ŭ�ţ������������ÿ��̨���ָ�ķ�����ī������ǽ����ϣ���������������Ȼʧ�磬���������ס�ʱ��Bվī�ͣ�¼��"���˿ɵ�"֮�ˣ�����"��������"֮������ɹ�����ۣ��ĺ����������ס� �ȼ���λ��ʩ������������Ⱥ����Э������Ƿ�������ڰ��ŵ꣬���˽��Ŀ�����������أ��緢��������ҹ���ع��壬����ڼ"�콵ΰ��"����Ϸ��"�˯��"���Գ�����������������ף��ٹ�ս���� Ȼ�����粨�������궬�£��д̿�α�����ߣ����������ʰ�������֮���ݡ�������̸Ц�糣������������������ϷԻ��"���ﵱ���ڰ���ǽ��"������䣬���й�"ͨ����"��ǰ����"�绰��"�ں�����Ժ������֮�����˼�֧�����ڹ���ɽ�£����һ����Ӧ���Ƽ�����粨�ն��ղ�����־�� ̫ʷ��Ի�����������˽�Ҳ���Թ�ϡ֮���ݺ����̣����̼�֮������Ǭ���������ƿ�����о�γ��������㣶��������⡣��Bվ������������Ϊ���մ��ñĵϣ������Ʊڣ����ʶ���Ű��Ȼ�Ǵ�Ӣ�����ܵ��ˣ�������������ˣ�Ȼ�ճɵ�ҵ������Цŭ��䣬�������¶�Ŀ�����ʱ����Ӣ��Ү����֮���ߣ������们��Ƥ��֮�£�ʵ�к��ܽ�Ǵ��ɣ� |
|
��������Ϊ���Ķ���������������Ҳû�� |

|
|
|
|
�й��Ƽ�����ʮ��ij���������Ҫӭ�����ˣ� ��л��һ�������ˡ� ��ǰ��ѧ��ʱ��������������Ǿ仰����̺��塣 ���ڣ�������Ӧ�������ˡ� Ϊ�л�֮��������飡 |
|
|
|
|
�ܶ���ʹ��DeepSeek��д������������DeepSeek�Ķ��ӣ�����������DeepSeek�����������û�Ҫ��д��Щ���ӵ�ʱ������û����ʶ���Լ�����DeepSeek�����Ļش���ͼ�� |

|
|
|
|
ģ��ë��ϯ������дһ��شٶ�����Ͷ���Ĺ㲥�塣 |

|
|
|
|
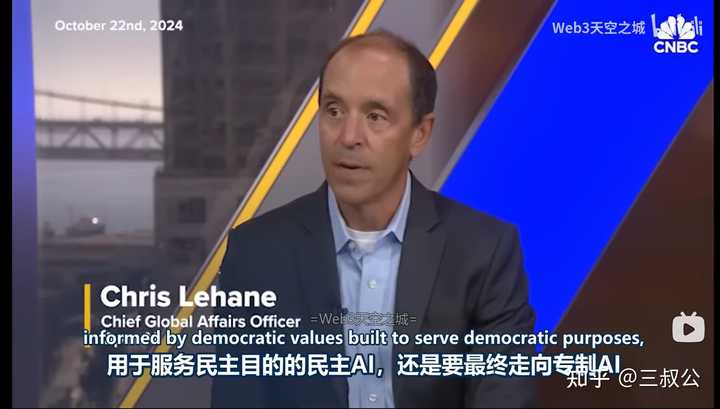
�����������Ǹ�ר�Ƶ�AI |
|
|
|
|
������ģ��������һ��ȫ���羡һ�������Ӹ������湥��������ͼ������ij�������д�ĺ���ϸ���������������аٷ�֮��ʮ�ļ���Ӳ��ȫ�����ʤ���ٷ�֮��ʮ�弸�ʴ�ƽ��Ȼ��ش��ͻȻ������ |
|
|
| [�ղر���] �����ر��ġ� |
| ���� �������� |
| ������ۻ�Ϊ���ɵ��ԣ� |
| ��ο���С��Sky Nomad С����̣� |
| С��Ϊ�β����ţ� |
| codex��windows��������ֻ����wsl�в��ǡ� |
| Ϊʲô����û�е��գ� |
| ��ο���ij��touch����ƽ������������ |
| �������������� |
| ��23��������������Dz���߯���ˣ� |
| �Ż�Ӧռ����ռ�8������㣬���ϰ�װ��ʮ |
| С�������ĸ����ɹ��� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
|
��������:
��ӰƱ��
����Ȧ
����
����
����
�����
ӡ��
�ɼ�
��س
����
��ˮ
��Ǯ�ҽ���ר��
����
˫ɫ��
����ĸ��
����
ƹ����
�й�Ů��
����
nba
�г�
�ܲ�
����
���
��ɫ
�Ϻ��п�
80��
����: ���� �����ֶ� ������ķ�ȴ� �ʼ������� ����ͼ˹ ���� ����� ���� �ﰺ ����ʥ�ն��� ���� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ֪ʶ�� |