| |
|
|
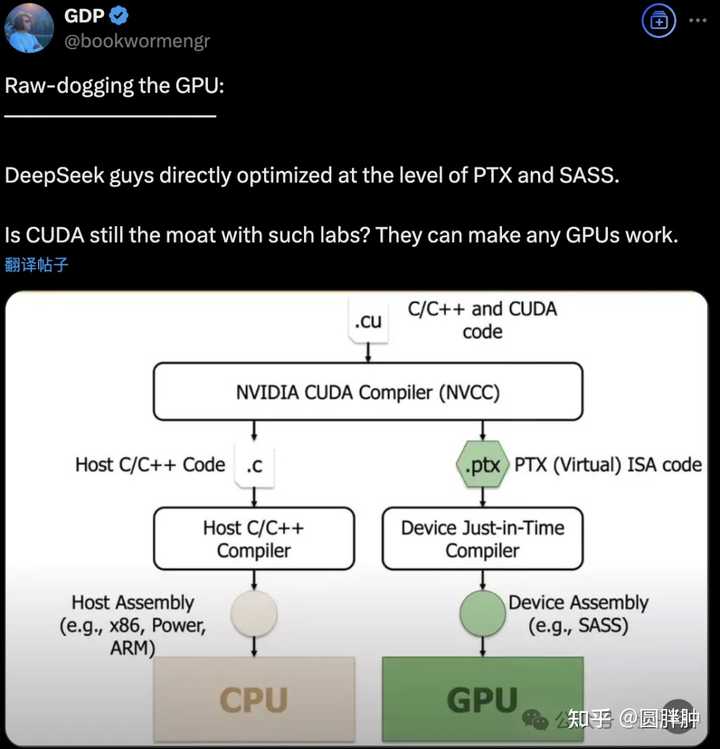
| ֪ʶ�� -> ���� -> DeepSeek �ƿ� CUDA ¢�ϣ����Ӣΰ�� PTX �����Ż�ʵ��������ܣ�Ӣΰ�ﻤ�Ǻӻ����� -> �����Ķ� |
|
|
[����]DeepSeek �ƿ� CUDA ¢�ϣ����Ӣΰ�� PTX �����Ż�ʵ��������ܣ�Ӣΰ�ﻤ�Ǻӻ����� |
| [�ղر���] �����ر��ġ� |
|
Ӣΰ��ոմ� DeepSeek-R1������4����Ԫ�����л����������������µ�ѹ���� Ӳ��ý��Tom��s Hardware���������������飺 DeepS�� |
|
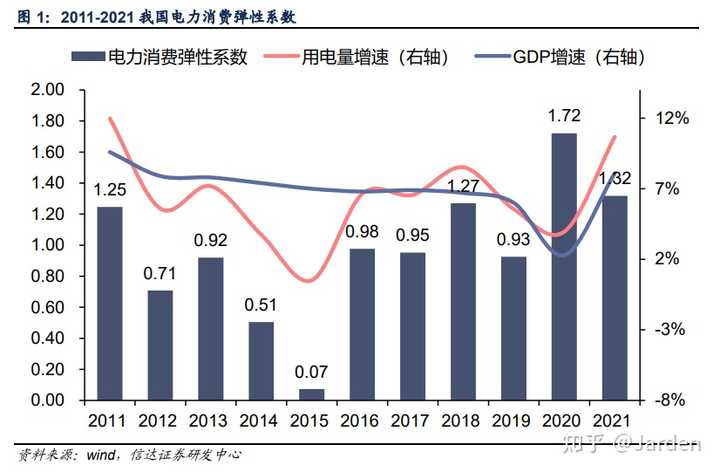
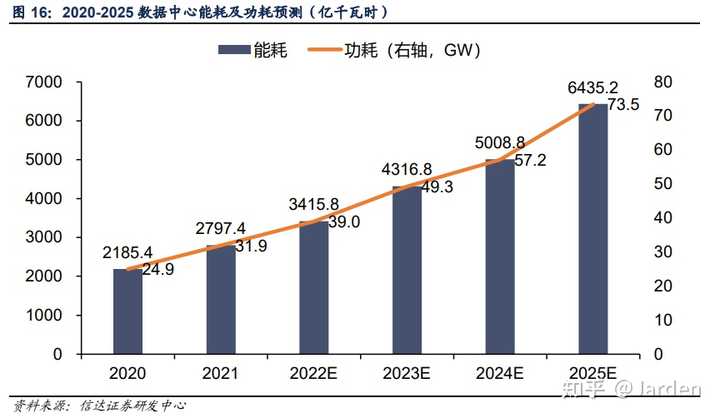
����Ϊ�ģ�DeepSeek �ƹ� CUDA ʹ�� PTX�� ʵ���ϵģ�DeepSeek ͨ���� CUDA ����������һ�� PTX �������Ż� CUDA ���ܣ�Ȼ��������ֳ� CUDA ��������ϣ��ڿɽ��յĿ���ʱ��������˿��������ɱ�� GPU ������������ Ӣΰ��Ļ��Ǻ��� CUDA ����̬�������� CUDA �������� PTX �� CUDA ��̬��һ�� CUDA ��̬������ API �ͷḻ�Ĺ��������Ӵ�Ŀ�Ϳ��֧�֣�����Щ�������Կ���̬�϶����������ơ� PTX �� CUDA �Ļ�࣬���������Ϊ CUDA ��һ��һ�����뵽�Կ�������ִ�еĴ���ģ�PTX �� CUDA ����һ���� �ֽε��� PTX ��������ָ�� PTX ���뵽 CUDA ��������� ����������PTX ��������������� PTX д PTX �Ŀ���Ч���ر�ͣ�PTX ����ֻ�������Ż�ijЩ�ؼ����֣�������Ƕ�� CUDA �����ʽ���ڵġ� PTX �ǿ�оƬ�� PTX �϶����ǿ�оƬ�ģ�AMD ����֮��Ӧ�ĸ����� GCN ISA�� ���� PTX �Ƿַ��ӵ��� CUDA �����Ľ���� PTX��Ҫ�Ǽ��� PTX ���Կ����������� CUDA ����������м������Լ��Կ������ˣ���ʵ�ϣ����� PTX �ȼ��� CUDA ���ѡ� ��⻤�Ǻӵĺ��� ��������˵��Ӣΰ��Ļ��Ǻ�һֱ�������ø��죨�������������Լ��ܵø��죩�������������Կ��������� CUDA ��̬�Ķ���̫���ˣ�������̬�Ķ������֮����̫ƶ��ˣ�DeepSeek ����¼�����û��˵�� CUDA ���Ǻӵ���ʧ����������֤�� CUDA ���Ǻ���Ȼ��̡� ֻ�е������¼�����ʱ�����Ǵ�������Ļ��Ǻ���ʧ������ �����Կ����������ܳ���Ӣΰ������ƻ�Ϊ�Ʋõ��µ���̬��Ǩ�㣨������ȫ���� N �������ȿ�ʼ�ظ������ӣ����ḻ��������̬CUDA ���Ǻӻ����� ��ʵ����ҵ��һֱ������ CUDA ������Զһ�Ҷ���ģ�������Խ��Խ���ҵ��ʼ�� AMD ���Կ��������������ࡣ������Ǩ�Ƶ������Կ��ijɱ�̫��������Ӣΰ�����Խ��Խ�ѿ���N ��Խ��Խ�����㣬���Ǩ�������ۿɼ��ġ� ���ǣ��������²۵ĵ���ǣ�DeepSeek �� PTX ����£��ʹ��� CUDA ���Ǻ���һ���ϵ��û�У������������Ӧ���� CUDA ���Ǻӵ����֡� ӲҪ���Ϲ�ϵ������δ�������Կ�����̬��ҪһȺ��ˮƽ�Ĵ�ҵ����������DeepSeek ���Ը��Ļ���������������������������飬�������ܲ���ʵ�֣���Ҫ������ DeepSeek ���ڵĸ��������Ƿ�Ը��Ϊ��������Ǩ�ƣ������������Կ�չ�ֳ��㹻��DZ���� ���ǣ�CUDA ��λ��ҡ�����������֮���� DeepSeek ����һ���ϵ��û�У��� PTX ���Ż� CUDA ��������ǰ�Ϳ�ʼ���ģ�ڸ��ˣ�������Ȼ�� CUDA ���Ǻ��ڲ������飬����ͻȻ���ó�����ƴ������һ�����¡� ���������ˣ����������������������Ҿ���������ĵ㲻�ǻ��Ǻӣ����dzDZ�����Ҳ����ѵ���õ��Կ�����������������һ����Ϊ Nvidia �ɼ��µ�����Ҫԭ�� DeepSeek �Ƴ��� Nvidia �Ĺɼ��µ���ζ��ʲô DeepSeek �����һ����ӱ���㷨���� 1/10 �ijɱ��� N ���������ѵ����֤��ѵ����ģ�Ͳ���Ҫ��ô���Կ�������Ϊѵ����ģ��һֱ���� N �������� Nvidia �Ĺ�Ʊ���������� Ҳ���� N ����Ȼ��ѵ��ʱ��������Ŀǰ��ģ�;�����Ҫ��������δ��ѵ������Ҫ���Կ����ܻ���� �����Խ�������������N ������������ܻ���Ϊѵ������Ҫ���Կ����ٶ����١� ���ܼ�������Ϊ�� CEO �ڵڶ��������һ������˼�Ĺ۵� ����˹��ۣ������������ˣ�ú̿���������������Դʹ��Ч�ʷ����������������������� ����۵���Ϊ���������������Դʹ��Ч�ʣ�Ч����߽�������Դʹ�óɱ����ɱ��½��̼�����Դ����������������������ܳ���Ч�����������Ľ�Լ�����յ�����Դ���������ӡ� ��һЩ���Ӿ��ǣ� ���������������ú̿������Ч�ʣ�����ÿ��ú̿�����������LED ���������ȴ�ͳ�����ܣ�ȫ�������õ��������������ҵ���Ч����������ͥ���õ������������������ĵ���Ч��ߣ����������ܺ��������� ������Դ��2020-2025 ��������������չ�� |
|
|
�õ�������һֱ������ |
|
|
�ܺ�һֱ�������� ������۵�����Կ���˵��������������Ŀǰ���۹��ǿ������ġ���Ȼ Nvidia ��Ʊ�µ����ܵ��й��Ƽ�ʵ�������������Ƽ���ҵ�������֮���Ӱ�죬������ȫ��Ӧ�����г����Կ���������Ŀ����� |
| ��DeepSeek�����ƹ���CUDA��������ʦ������ʣ�Ӣΰ�ﻤ�Ǻӻ�����?www.zhihu.com/question/10949909331/answer/90240945794?utm_psn=1868767916519981056 |

|
|
��ǰ����ش�ʵ�ڹ��ڳ��ܻ������ڵ����Dz���������llm�Ϳ�ʼ�������졣 ptx�����cuda���ײ�ģ���nv gpu��������ԡ� ptx�����cuda���ײ�ģ���nv gpu��������ԡ� ptx�����cuda���ײ�ģ���nv gpu��������ԡ� �������������һ�㣬����֪����ν�ƹ�cuda��ʹ��ptxʵ���ϲ����Ǻ�nv��ź�����Ǹ���ȵ��Ż��� ԭ�е�ģ��ִ�в㼶: ģ�Ͳ����Ӳ�ʵ�ֲ�(cublas, cutlass, ��дcuda, �Զ�����cuda, һ����˵����Щ���ʵ�ֵ�)���� ��ν�ƹ�cuda��ָ������ʵ�ֲ������д/�Զ�����ptx������һ��kernelʵ�֣���������Ŀ���Ǹ���ȵ��Ż�����ptx��������ȫ����nvidia�ı�����ʵ�֣���Ŀǰû���κ���֪���߿��Դ�ptx���뵽����ƽ̨�Ļ��㡣��cuda���������й�����������µģ������Ѿ�֤���ǿ��еġ����˻�Ϊ���ƹ�cuda�Ļ��Ǻ��������cuda�����ptx���Ǻ��� �����Ҫ�ƹ�cuda����İ취���������Ӳ������ƽ̨����֧�֣���ʵ��������˾Ҳ����ô���ġ� ��������ʵ��һ�������ֽ�����֧�ֲ�ͬ��gpu������һ������ptx����������ֽ���һ������뵽ptx��ִ�С������������ڵ�gpu��û��һ��ͨ�üܹ���Ҳ��ʵ�ϲ���֧���κγ̶ȵĽ���ִ�У��������������ֱ��ʵ��һ����ƽ̨���ӿ�/���ӱ�����û���κ����ƣ�����Ҳ����������������������� |
|
����ǰ�ڰ����ʱ����ʶһЩ���ز������ѣ���ʱ�����ǻ����Ұ�����������Ǽ��������ĸ��������ֻ��������������û��һЩ�����ϵĴ��� ���ҿ�������ptx�ƿ�cuda���Ǻ�������ظ��ʱ���Ҿ��뷢�����˵������Ӧ��һ�д���Ҳûд���� |
|
1.deepseek�ƿ�cuda��������cython�����ƿ�c���ԡ� 2.��cs������Ա��ԭ���Ǹ���Ц�𰸵ģ��������⣬cs������Ա���ˣ�һ�ɿ����ʱ��������������Զ�����Ͱ�� ��cppд��ʱ�Ӵ���ʱ��ż��Ҳ��Ҫ��c���������x86���������������ܣ���ô�������ˣ����ֺͼܹ��Ļ����任mips��arm��sparc���������� cuda�������Ǹ�c�⣬ptx��������nv�ܹ�gpu��ר�������룬дcuda��������ȥ�� ��ptx��java�����м��룬��������x86�Ļ���ܱ�ļܹ������У�˵�����˻�����IJ��У���д�����ˣ��ɵ��İɡ� |
|
�ֿ�����̽�����ԭ���ˡ� Ц�����˵����ݺ��ö����ۣ����˱�¶����ϡ��֮������ô���������PTX�ƹ���CUDA�� |
|
���� ASCII ��дС���ģ��ƹ���Ӣ��ɹ�ͻ�� English �����������˵ķ����� ����ʮ�����Ʊ�ʾ���������ɹ��ƹ�IEEE754�������������ⱻISO/IEC��֯�����ӡ� |
|
PTX��ʵ��Ӣΰ��GPU���м�ָ�����α�CUDA�ͣ���һ���Ǻ�Ӣΰ���GPU�߶Ȱġ� deepseekʹ��PTXֻ��Ϊ�˶Գ������ܽ��и߶��Ż�����˵���ֳ���һ�����Կ�������Ԫ�������ݵ�ѹ��/��ѹ�����Դ˴��������Կ�֮�������ͨ�Ŵ��������ֶ�Ӳ�����ܵļ���ѹե����������Ա�ķ�� ������˵��deepseek�ij���Ա�����Լ��ij����г�ֵ�������ƿأ�û�а��Լ��Ĺ�����ȫ�������ֳɵ�CUDA�����档����������˵������Ӳ��ƽ̨Ӧ�ò���ʲô���¡� |
|
������Ǹ�����˵������Ҿ��ú�����������㻹���������Ĺ���ʦҲ˵������һ�����㻹��ѧ�������պ��ڰɡ� |
|
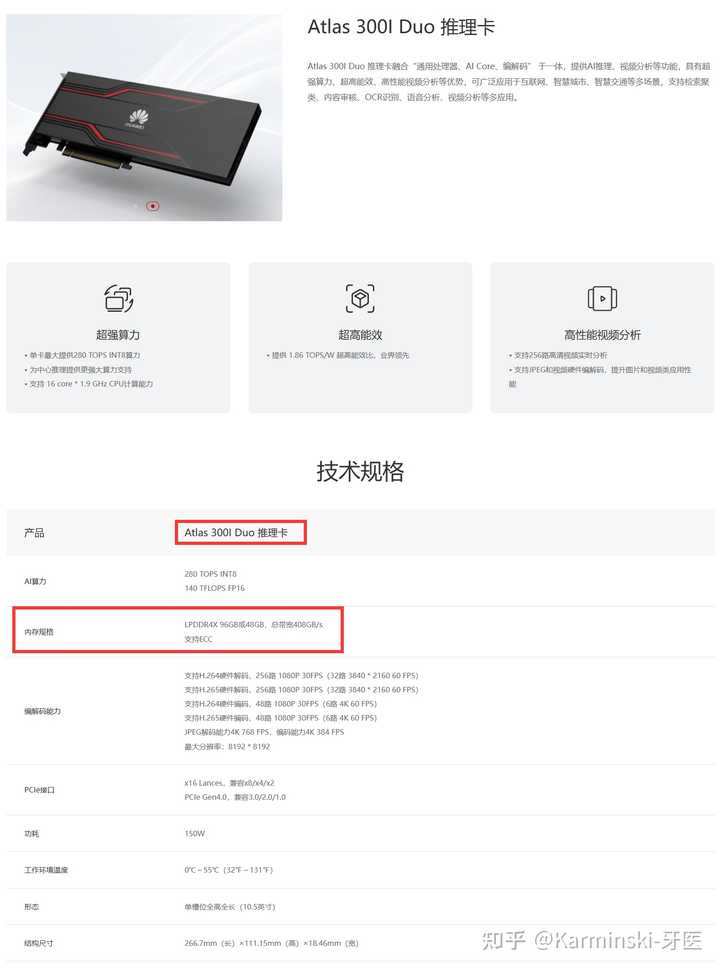
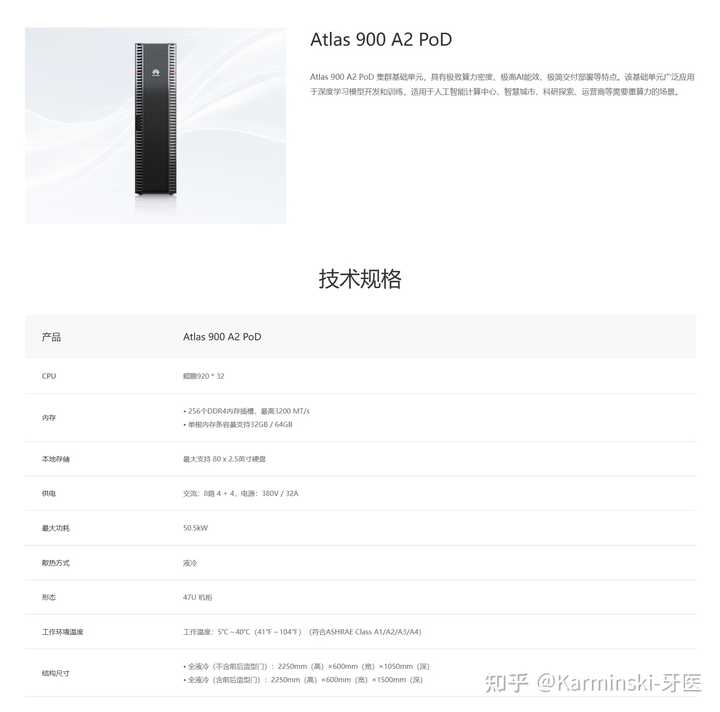
�ĵ�����ģ���������ȷ����� DeepSeek-R1 �û�Ϊ�N�ڣ�������Ⱥ��Ŷ�� ���ݻ�Ϊ�ٷ���Atlas���N�ڣ� 300I Pro ����������ӵ�� 140 TOPS INT8 �� 70 TFLOPS FP16����������㹻�����ã����ؼ����ڴ���ʹ����LPDDR4X 24 GB���ܴ���204.8 GB/s������ζ������ԭ����FP8�汾��DeepSeek-R1��ŵ������Ȳ�����װ���µ�����, R1��������37B���� 4 token/s. |
|
|
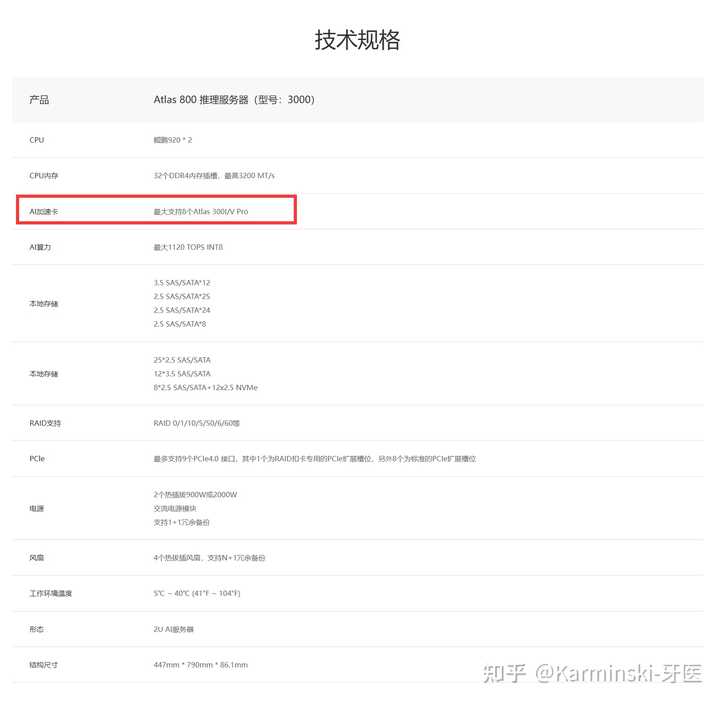
Ȼ����2��һ�ͺ� Atlas 300I Duo(һ��PCB����2������)���ڴ淭����LPDDR4X 96GB��48GB���ܴ���408GB/s�� |
|
|
��ô���Ǽ���һ�������װ��DeepSeek-R1��FP8 ����800GB���㣩, ����� 8.3 ~= 9 �鿨�������ٶ������� 72 token/s ����ô�����װ�����ٶ���ʵ���ã��Ȳ����Dz����� ����װ�Կ��ķ����� Atlas 800 �����������Ǹ�8����������RAID�����и�PCIe 4.0 ����8��Ӧ���Ǽ��ޣ���Ϊ��Ҫ����������ô����Ӧ���Ǹ�˫����16���ļܹ����ܴﵽ��ͱ��������ڴ�ﵽ 1.5TB ����. �����ٶ���128 token/s Ȼ��Ϊ�ĕN�ڼ�Ⱥ����Ӧ����16̨2U��Atlas 800����˵���������12TB�����ڴ�, �����ٶȼ�����1024 token/s�����ÿ���û���60 token/s�� ��ô�����ϵ�������17���ҡ������������50.5kW�� |
|
|
��ô����������������˼�ģ��������վ� 1000 ���û�Ҫ��DeepSeek-R1, �����Ҫ���ٷ�����? ����ÿ���û���ƽ�� token ������� 500������������token����������ô60 token/s �ĵ��û�����Ӧ����Ҫ 8.3s���ܽ������ɡ����Ǽ�������1000���û�����ƽ��������8Сʱ�ڣ���ôÿ��������ƽ��ֵ�� 10000000/(8*3600)=347.2 ��ÿ����Ҫ����348����. �����������㵥̨��������QPS, 17����/8.3s ~= 2.048. ��ô���վͿ��Եó�, ��Ҫ�ķ�������Ϊ 347.2/2.048 ~=169.5 ��170̨��������Լ11����Ϳ��ԣ��ܹ���������550kW. ��������õĿ��N�� 910b ��? ������ʹ��HBM2e �ﵽ�� 1.2TB���Դ����, ���� 64GB. ����Ҳ��8��, ��ôֻ��Ҫ���30̨�������Ϳ��ԡ����Ҳ��4����4U����������8̨�� ��ע�⣬��ֻ�ǻ�������, ʵ��Ϊ�˶�ס��ֵ����, ����Ҫ���Ը�3-5������Ȼ�Ʒ���ĺô�����ֱ�ӹ�������������ͺ��ˣ� |
|
�Ȼ���ȱ�Ӯ��DeepSeek Ӯ�ķ���ܶ࣬�����Ӯ��Ӯ��ͷ�ˡ� ��Ϊ PTX �Ż�ʵ�����Ǽ���Ӣΰ�ﻤ�Ǻӵġ���Ϊ PTX �Ż�ʵ�����Ǽ���Ӣΰ�ﻤ�Ǻӵġ���Ϊ PTX �Ż�ʵ�����Ǽ���Ӣΰ�ﻤ�Ǻӵġ� ��������ת��Ӯ�����������ѧϰ����ȫ������ Java ��������ķ���. ������ģ��, �������� Python/C++, ʹ�õĿ���� PyTorch/GGML. �����ǵ��õĸ��� CPU/GPU ������, ��Щ����һ��ʹ�õͼ����Ա�д, ����תΪ���. �� CPU �ϵͼ����Ծ��� C, ������Ծ��� NASM. �� Nvidia ���ϵͼ����Ծ��� CUDA, ������Ծ��� PTX. CUDA ����ͼ������ڱ�Ŀ��ϻ���ת��(һ��� lower), ���� PTX ���ּ������ij�ֿ��Ļ��, ת����û�����. ��Ϊ��Ŀ�, ����N��, ������ȫ��ͬ��ָ�, ����û����. ��������Ż���Ǩ�Ƶ���Ϊ�ĕN��, �����ϼ�����Ӣΰ�ﻤ�Ǻ�. ����Դ� DeepSeek �Ŷ������˽� Nvidia ���ĽǶ�Ӯ Ҳ������Ϊ DeepSeek �ܶԕN��910 ��ͬ���Ż������ĽǶ�Ӯ ������Ŀ���������Ӯ������ 3000 �˵���, ������ı���ס��. |
|
���� ˵��������߶���û���κκô�����˱���Ŀ�IJ������ۣ��������������ۡ��һᾡ����������ϸ�ں����ʣ�������Ⱥ��ϲ���ּ��������������� �ұ�ҵ��һֱ����GPU��������������дCUDA��AI����������ͣ���ڱ�ҵǰϦ�����ⲿ�ֿ��ܱ�����ƫ������λָ���� �����������ֹ��ɣ������Ƕ���Ŀ���������������ۣ�����ǶԱ��������ɴ������۵�����ۣ�����Ǹ��˷��ӡ� ���� 1. DeepSeek�����ƹ���CUDA��ʹ�ø��ײ�ı���������Ż��� ��Ҳ������"����"��ô���ȵ���������Ϊ�����ҵ����٣��ڲ���ϵͳ������������У���C++, CUDA����ͨ�������������߳���������HPC����ʦ�Է���ˮһ�����ճ���ÿ���ܹ��ϸ��������ƽ����Ĵ���ѧ������������ܡ� ���ο���PTX�ǹ���ָ�������Ҫ���M1������������ز�һЩָ��IJ��������ú����塣 �ҵ�һ���½Ӵ�CUDA��ʱ�����ҵ�ͨ��CUDA������ﲻ������PTXָ��������Ż�����Ļ��ᣬ������20%������������dpsk�Ĺ���ʦ��˵�ز���ʲô���¡� �ٴ�ǿ��PTX�ǹ����ģ���ֱ�Ӳ���PTXҲ����ֵ�ô�С�֣��Ҽǵ�Triton, TVM��XLAҲ��ֱ������PTX�����ǽ���LLVM��NVPTX��˻�ȡ�� ��������������ʵ���ҷdz�����ֱ��дPTX������NV�Ļ��Ǻӡ�����۵㣺 PTX�ĵ��ǹ��������������������LLVM NVPTX����Ǵ��ڵ� 2. ��ʹ��Ӣΰ���H800 GPUѵ��DeepSeek-V3ʱ����������Լ��������132����ʽ�ദ������SMs���е�20���ijɸ�����������ͨ�ţ������Ǽ����������ƹ���Ӳ����ͨ���ٶȵ����ơ� ����������Warp-Specializationд������CUDA C++Ҳ����ʵ�֣�ֻҪ��if-else�ò�ͬWARP/CTA ID���߳�����ͬ�����顣����NVGPU�����������첽ָ���setmaxnreg���Ǵ�ɱ�����ɲ���������ۣ�����Ϊ����Ⱪ¶��C++�ӿڡ� ����仰����Ϊ�Ҿ������е������������ΪWASPͨ����ֱ��дCUDA��ʵ�ֵġ�������Ϣ����PythonҲ��дXD Enabling advanced GPU features in PyTorch - Warp Specialization?pytorch.org/blog/warp-specialization/ |

|
|
�������۵�PTXԼ����Java�ֽ��룬���뵽�������̵ĸ���*pu�ܼ� ���ɣ���ͬʱ�߱�HotSpot C2��GPU�������������顣 Ϊ�������п��ö����ҽ���һ�£�HotSpot��һ��Java�������ʵ�֣�����ճ�ʹ�õľ������APP�ĺ�̨��������HotSpot�ϣ���C2�������н�Java�ֽ�������X86��ARM�������JIT�������� PTX��ʹ�÷�����Java�ֽ���Ҳȷʵ���ƣ�PTX����ֱ������Ӳ���ϣ�����ͨ��JIT���뵽�����Ļ��SASS�����С� Ҳ����˵��PTX���ֽ��������һ���������е�IR���м��ʾ������Щ�˿���������LLVM IR���죬������ƪ������Ҳ�����Ʊ���: ���ĵ�С������PTX��SASS���������ӽ�241 ��ͬ �� 34 �������� �������в��������Խ��ۣ�����б�Ǹ����˵PTX��IR���ǻ����ҳ����������GPU�����ľ��飬PTX���ֽ��롢LLVM IR��ȫ����������Ķ�������Ҳ������д�����ĵ��Ķ�һ�¡� ������ƪ������Ҳ˵����PTX��SASS��ʮ�����ƣ�ָ��ṹ������һ���ģ�ν�ʲ�����+���ݲ�������������Ϊ�˱����NV GPU�Ļ�����Ƶģ�����Ũ���NV GPUӲ��ϵ��ϵ�ṹ��ɫ�ʡ���֮��LLVM IR��JAVA�ֽ���Ϊ�˷���ת��Ϊ����ȥ��Զ�ĸ�ƽ̨�Ļ�࣬���DZ���߱�ƽ̨���ԡ������ϵij�����Ͳ�һ�����ݱ�ɵ���̬��Ȼ��ȥ��Զ�� ����ʱ��������Ampere���ô�PTX��д��һС�θ����ܴ��룬���ҽ���ֱ������Turing��ʱ����������������ˣ�����ʵ�ڲ���ͬ��PTX��LLVM IR��Java�ֽ�����ȡ� �ٴο������Ǵ��ĵ���һ���� LLVM Language Reference ManualThe Java Virtual Machine SpecificationParallel Thread Execution ISA Version 8.7 ��������������ֲ����������Ӳ�������׳̶ȣ��ҵĽ����ǣ�ֱ����ֲCUDA���� ������ȷ���ǣ�PTX�Ǻ�NV GPUӲ���߶Ȱģ����Էdz����ر�̣�����һ��PTX�����������ǵ����̵߳�������Ϊû����ֲ���飬��ʱ���������뵽�Ŀ����������ǣ� ����ֲ��SIMD/CPU�ܹ�ʱ��������Ҫ��ȫ����������������ο�<Whole-function vectorization>�����Ѿ�����ϸ�ڣ����Ҳ£���SIMD���Ȳ���32ʱ����Ҫ���и��ӵĿ������仯�������ǵ�Irreducible Control Flow Graphʱ�����ѡ��������е�Produce-consumeд������ѩ�ϼ�˪������ֲ��ASIC�ܹ�ʱ����Ȼ��˵PTX��SASS���д����Ż�����������PTX���ֵľ���������O0��Ч�����������̴�PTX����ݵ�Ŀ�ģ�ʮ�а˾���Ϊ�˰�����Cutlass�����߶��Ż��ֿ�Դ�Ŀ⣬�㷺Ӧ������multi-stage��tiling���Ż���ת�뵽�Լ�ASICӲ���ϣ��Ҳ������ȵý�PTXָ��ӳ�䵽ASIC����֧�ֵ�ָ�ͨ������GPU��ָ���ϸ���ȣ�������ḻ; ��Ҫ���ָ���������ƥ������Σ���������ָ��֧�ֵĿ��Ȳ�һ����ASIC�Ŀ���Ҫ��һ�㡣����ֲ��SIMT�ܹ�ʱ��AMD GPU�������ǣ����Ҽǵ������ṩ��CUDA->HIP�ķ��빤�ߡ���֪������ZLUDA������Ŀ�ṹ�Ͽ�����ͨ������PTXת����LLVM IR��ʵ�ֿ�ƽ̨�ģ�����ҳ����OpenCL�ĶԱȣ�������˵��û��̫��˵����������Ϊ������Ŀ��о��������� �����С�������Ʒ����֮���������ء� Ȼ�����������⣺ Kernel�����ܣ���Ҫ�ڲ��жȺ;ֲ���֮��Ȩ�⣬�����������ٸ�CTAͬʱ�ܣ�Thread/Warp��ι������ݣ���Щ���ؾ�����Ƭ����Դ(��share memory�ͼĴ���)ʹ�õ�������ʹ�õ����־�����kernel�����д�������缸��stage���Ƿ�Ҫѭ��չ�����ֿ�Ĵ�С�ȵ�...������Ҫ�ﵽ�۵����ܣ�����Ҫ�������kernel�����ʹ�õģ������ptx�����ת���Dz����ġ����嵽ÿһ��PTXָ���ϣ�Ӳ���������Ҫ���ǣ���Ҫ��Ӳ����ֱ��ʵ��ÿһ��PTXָ�����ͨ������ģ���Լ���ο���ģ����ɵ���ʧ��Ӳ��ָ���Ƿ���ѭPTX����ʽ�������Ƿ����ӿ���ָ��ִ�е�ν�ʲ�������������ӣ�register file����ˮ�������ƣ��Ƿ�֧��data forwarding�ȵȣ�NV GPU���е��ڴ�㼶��ô֧�֣�PTX ISA������ArchӰ�������ԭ��Arch�����ںϣ����ʺ�����Ϊ��Ҳ��֪���𰸣��Ҿ��ú��ѣ������������ǣ����������Ǿ��ü���֮���Ե����ڲ�д��ƪ����ҪҲ�������������ISA��Ӳ���ͱ�������Ӱ�죬����ֻ����ש�����һ���Ҫ����һЩ���ϡ� ������֪����Щ�Ŷ�ͨ��PTXת�뵽�Լ�Ӳ���ϴﵽ���൱�ɹ۵����ܣ����õ���Ampere�ܹ�PTX�����Ĺ������Ͽ��Ե�֪��Hopper��һ���ʵķ�Ծ����δ��֪�κ���Hopper֮��ɹ��İ����� ������дPTX������д�����һ�࣬��������CUDA �Ϲ�������Կγ̵�ѧ������д��࣬��������ͬǰ��䡣��һ��������۵�������ϵ�����������������CUDA��һ˵����NV GPU��дCUDA����Ӧ������һֱ�����кܶ�����AMD���N�ڵȹ�������д���ӣ���Ȼû��CUDA��������û����Ҫ�����ڱ�Ŀ�дCUDA���� �������ǣ�����CUDA��ʵ��NV GPU��̣�����ֻ�ñ�ʾ��л���Ҹ���������Ϊ������PTX������CUDA��дNV GPU������е����š� Freestyle ���û��ĽǶȣ��Ҿ���CUDA��ϵ��ţ�Ƶĵط���: ���伴�õ����顣��cublas/cutlass/cudnn���ָ����ܿ⣬�Լ�pytorch�ȴ������������������á��̼�ǰ������һ�����������̼��㿨�����⣬�Ͳ��ڴ������ˡ����ʵı�����顣дkernel�������߳̽Ƕ�����ģ��dz��������֣��Ҽǵ�����дnbody����ʱ��ֻ�Ǽ���ֲCPU������ܼ�ʮ�����ٱȡ�����ʱ�϶���Ҫ�˽�����Warp/CTA����ڴ�㼶���Լ����ӵ�API������ʱ�Ѿ��гɾ��ˣ�η��������ʣ����ǿ��Ĺ�����������Nsight��NVCC��Nsight��ķdz�ǿ���ù���˵�ã��Ҹ����ŵ�ʱ��������Ѹ���ҵ�ƿ�������ҵı������������鿴��������profiling���ߺ���ֱ��ָ������/�λ����ƿ��������ṹð��(Structure hazards)�ͺ����Σ�ǿ���profiling���߿��������°빦����������ߵ����ٶȡ� �ع�ͷ������dpskʹ��PTX��̣��иı������κ���״��û�С����������Ǵ������廹����CUDA��д������ͨ��NV������������֧������ȡPTX��Ҳ����Nsight����λ����ƿ�����������Ȼ��Ҳ�п����DZ�������֪���������ȱ�������֪����֪ʶ���������ݵ������������߳̾������Ҷȵȣ�������PTX�ֲ�ֱ������ǡ���Ļ��ָ� ÿ��һ��ʱ�䣬���µ������CUDA���������ܿɹ۵ı�����Գ���ʱ��������CUDA������ˣ�NV�군�˵��۵�����ͨ�������¼�������ȥ��֤�� �Ƿ��ƹ���PTX��99.9%�Ķ�û�ƹ�����������NV�Ĺ���������ʵ�ִ���ͱ�̷�ʽ���ڲ��ֳ���������ǿ��еģ�����Triton�����ò��ᣬ�û������Ǹ����Ǽ����ˣ���������������Ա�͵õ�ͷ���ˡ�ʵ��������չʾ��Benchmark����֪�������Ե�ͨ���ԣ���Щֻ�м�Kernel����һЩֻ�й̶����͵ļ���Kernel����GEMM, GEMV��Element-wise�ȡ�����Ŀ���ڽδ�����Dz�֧��̫�����ͳ�������ʵ����ֻ����Ϊ�����ֶΡ� ���⣬�ܶ����ѱ����ϵ�ṹ��Ӳ���ŶӵĹ��ף��·���������оƬֻ����»�ľ����̨��������ˣ�����Ϊ���ԡ����Ҷ��к�������������������ԡ���ϵ�ṹ��Ӳ��ʵ�����ߵ�ȷ���Ӱ�죬���ճ��ֵ��û���ǰ��Ч����������һ������������ã���һ��ֻ����ģ���ҿɷ��ģ� �������ϵ�ṹ?book.douban.com/subject/7006537/ |

|
|
�������ⷽ����һЩͨ���������������һ��֮�ԣ����ӿ۹����� ��RT core��Tensor core�������ƺ�û��ʲôͻ���Եı仯�����Ľ�����������Ƥ�飬�Լ���������Ӧ�ı��ģ��ת�������Ϊ��Ӱ�����ºͶ���Զ�ģ������������ܼ�Ч�� ����ҿ���ijЩ����˵��PTX��ο��Է������ռĴ����������Թ��� |
|
�ƹ�cuda����˵�˵���������Щ��֪�������˽�.cu����ִ�й���Ҳ������ ��ֱ��ʹ��ijЩnv���ӿ�����ƹ��𣬺ܶ���������flash-attn��ʹ����ˣ�֪�����ӿ����̬ʲôλ���� ��Ϊ������/Ӳ����˾����������Զ�һЩ������˵����Щ�ܶ���û����������cuda��̬һ���֣���nv���ⲻ��Դ�� ����AI����ջ�ֲ㣺 model��hf�ϵĸ���ģ�� �ֲ�ʽ���ٿ�ܣ�megatron & fsdp & deepspeed����������zero3/tp-pp pytorch��python��ˮ�㣬python�����Ե���c++������dispatch�� ad�Զ��֣�torch allocator��ncclpgͨ�ţ�����оƬ��������Ӳ�����ϸ�����������ģ�ͨ��privateuse1���key����ͬ�������ʵ�֣� cuda���ӿ⣺cutlass��cublass��cudnn���Ⱥܶ�cudaԭ������⣬��cuda-toolkits����кܶ�������⣬���������õģ�Ҳ�Ǵ�cuda������д���ӿ�Ĺ�����cudaӦ����̬�������boost��c++11�����������c/c++ so�� cuda runtime && cuda��������.cu��������У�nvcc/gcc��c cuda code�����device��ִ��sassָ����Ӵ��fatbin��ͬʱ��Ҫ��Щfatbin���͵�device�ϣ����������ִ�����̣���ptxֻ��nvccһ���м�IR������ǿ��Զ����ġ����������gcc�������ӣ��Լ�elf�������У�ֻ����cpu��os��cpu�ϣ���cuda��������device�ϡ� umd���û�̬������һ���Ǻ�cuda runtime�����һ�𣬵���Ҳ����ֱ���ṩumd��̽ӿڣ��dz��Ѷ�����ϸ����ֻ��оƬ��˾�����з�������ʵ��cuda��������Ҫ�Ĺ����� kmd���ں�̬���������ϲ��ṩioctl/rw�ӿ� why�������c/c ++ linkers and loaders���Կ�ֻ�Ǽ������һ�����裬��Ҫ�ں�̬������kmd�������豸���ṩ����/���ݽ���������kmd̫�Ͳ㣬��Ҫumd/runtime�ṩuser api ����ʱ֧�֣�����device��ʶ��Ķ�����cubin��ô�����豸���Դ���䡢����copy��kernel��ôkick���첽�����ô�õ����쳣����� ��ȷ������cuda���������֮����дgpu����c code��kernel function����nvcc�������Ӵ����cubin��.cu��ptx��sass��������ͨ���������͵�deviceִ�У���ptxֻ��������м���deepseek�������£�����c/c++Ƕ��asm���Ż��� ��֮��ptxֻ��һ��lower IR�����ڻ�࣬���ԱȽ�ϸ���ȿ��ƴ��룬��д���ʹ�����ˮƽ�ˣ�һ����һЩ�ȵ�code������ptxȥ�Ż�������Ҫ�����������ѿ�ִ�г���device���Һ����첽ִ�У����ӿ���ʵֻ��cuda��̬Ӧ�ò㣬runtime/�����Ʋ����ģ�����˵��pytorch֮���ˣ�ds infraǿ��v3 paperд�ģ�ptx��ľ�ţһë�� ps��V3��R1����paper��deepseek��cuda��Ӳ��������������˾������top1�ģ��ܶ������Ƿ����ޣ���Ҫ����Ϊ���ǵĹ��������Աȼ�openai �������������Ի��۱ܿ�����û�����£���ңң���ȳ�û��Ȥ����֪��Ϊɶ�⻰��Ҳ������һЩ����ɷ�ʣ����������ˣ�ñ���ѱ��Լ��졣 |
|
�ܶ���û����ʶ����ζ�Ӣΰ��ij���ж�� ��ʵ��gpu�����£�����˵���gpu��ȷ�е�˵����ƣ���Ϊ��������оƬ�ģ���̨���縺��ľ�Բ����ҵ��������ЩоƬ��ҵ������intel���⣬���������϶���оƬ����Ƴ�������Ӣΰ�ƻ����amd����ͨ��Щ gpu��ʵûɶ�ر��ӵģ�gpu�ı��ʣ������ܲ��д���һ����Լ������оƬ gpu �Ա� cpu������һ�����Сѧ����һ�����ڣ��������һ�����Сѧ����һ������ͬʱ��10000���Ӽ��˳���ѧ�⣬һ�����Сѧ���϶��Ƚ�����ÿ죬��Ϊһ�����Сѧ�����Բ��м��㣬������һ�����ѧ��ֲ�ɼ�ʮ�������IJ��֣�Ȼ����ÿ��Сѧ������һ���֣�����ɼ��㣬���ǽ������֮�£����Ҫ���ö��ˣ���Ϊ����ֻ��һ���ˣ�cpu�����Ǹ����ڣ�gpu������һ�����Сѧ����cpu���Dz�����gpu�ļ��㣬���Dz��еĺ��������٣������㲻�� ����Ϊ���챾����������Ӣΰ����ɣ�������̨��������ģ�����Ӣΰ��ĵ�����gpu��ƣ���ʵû��̫��Ļ��Ǻӣ�����gpu�Ķ���ǣ�����������gpu���Ʒ�ģ�Ҳ����asic������xpu��tpu��Щ��Ҳ�кܶ����ҵ������ ���û��cuda������ν��������̬���ǺӵĻ���������оƬ��Ƴ�Ҫ������Ʒ����Ҳ���Ƿַ��ӵ��� �����deepseek���˼�ʲô���أ� ����Ȥ��deepseek�����ƹ���cuda��ֱ��ʹ��gpu���ֽ���Ҳ����ptx���룬Ȼ���ٽ������IJ��サ��gpu��jit����������ִ�� ע������Ĺؼ��֣��ֽ��룬jit������ ���ܺܶ��˶�����Ϥ�ˣ��ԣ�java�������ԭ���� ����java���ֽ�����Ҫ�DZ����cpu��ָ��ִ�У�������˵����gpu �ܶ��˲���֪�����ǣ�gpu��ʵҲ�Ѿ����������ֽ����jit���� ����Ϸ�д���ʹ�õ�shader����������Ϸʱ��Ҫ����shader���ɣ��Ǹ����ǰ�shaderԴ������һ�ֽ���spir-v���ֽ��룬Ȼ�����ɱ�������ˣ����䷭���gpuָ�ִ�� ��Ȼ��Ҳ����ֱ�ӷ��벢��spir-v�·���������������ע�⣬shader���Ե�Դ����Խ�С�������spir-v�Ļ����ֽ�������Ҫ��Դ������٣����Ժܶ���Ϸ����ѡ����shaderԴ�� �����һ��ִ�е�ʱ������룬������ῴ���Ƚϳ�ʱ��Ľ�����ʾ˵���ڱ���shader ������������Ϸ������ֽ��룬Ҳ����spir-v ��cuda�õ��ֽ�����ʲô�أ� ����ptx |
|
|
�㿴��ptx����һ���Dz��Ǿ���jit�����������������һ���ֽ��룬��spir-v�Լ�java�ֽ���һ���� ֻ���������jit����������˷�����ai��gpuָ�java�ֽ����Ƿ����cpuָ�spir-v�Ƿ������Ⱦ��gpuָ�� ע�⣬�����ptx�������gpuָ���������ʵ��gpuָ�����Ҫ��ʱ����֮�����ִ�� �����deepseekֱ��ʹ��ptx����̣���ζ��ʲô�أ� ���deepseek������ptx��̣��Ǿ���ζ��cuda���ڱ�ú��ޱ�Ҫ�� �����Խ��ͳ�Ӣΰ���gpu��ָ�� ����Ҳ�Ϳ��Խ��ͳ�����gpu������asic��ָ�� ���仰˵������������ǿ�ƽ̨��ȷ��һ��˵�����ǿ�gpu��aiоƬ�� Ҳ���ǣ������Խ��ͳ�Ӣΰ��gpu��ʹ�õ�ָ�Ҳ���Խ��ͳɱ���Google����tpu��ʹ�õ�ָ�Ҳ���Խ��ͳɱ��粩ͨxpu����ʹ�õ�ָ�Ҳ���Խ��ͳɻ�Ϊij��оƬ�ϵ�ָ�� ������ֱ�Ӹɷ��˱�����ǰ��Ҳ����cuda��nvcc�Ĵ��ڼ�ֵ������ ����ΪʲôӢΰ���ƱӦ���µ��� �����ԭ�� ����ע����һ�����е���⣬����˵�IJ��ǰ�ptx���������оƬ������tpu��xpu����ָ�����˵����Щ����ai�����оƬ�Ļ�����Ի��߽�ָ�����ʵ���Dz��ģ�deepseek������ptx��̣���Ҳ����������оƬ��ָ���������ָ���̣���Ϊgpu��ָ����Ա�cpu��Ҫ��gpuֻ���ܹ�ͬʱִ�и����ָ�������˵����ָ���жิ�ӣ���һ��˵�ˣ�gpu��Сѧ����cpu�ǽ��ڣ������һ��cpu��ָ�����gpuҪ���ӣ�������ai��gpuָ�����һ����Ҫ����һ�㣬���Ե�����tpu��xpu��npu��ר�����ڴ���ai�����оƬ����ЩоƬͳ��asic��Ҳ����Application-specific integrated circuit������Ӧ�ü��ɵ�·������asic��������ai��оƬ�������������оƬ��Ҳ������asic����Ϊ��Լ�ָ�����ô���������Ժĵ���С��������Google��˵����tpu�ĺĵ�����gpu������֮һ ��Ϊasic��ָ�����Լ��������ƣ���Ҳ�ܺ����⣬��Ϊ������ͬһ�������У�������ds�ܹ���ptx��̣�����ζ������Ҳ��������asic��ָ���̣����������һ��poc��proof of concept����Ŀ����֤�����ҿ�������������Ŀ���ҿ��Բ���cudaֱ��ʵ�ִ�ģ�ͣ��������˼ Ȼ������aiоƬ��ָ�����ࣩ������ָ�Ҳ�����м��룬�ֽ��룬����ͳһ��������cpu��java���ֽ��룬gpu��Ⱦ��spir-v����Щ�ֽ��붼�õ��˹㷺��֧�֣�aiоƬ���ڻ����ڸ���Ϊս��״̬�У�Ӣΰ�ﵱȻϣ���������Ҷ��������������cuda��������ptx��������оƬ�������dsֱ������ptx���Ǹ����㣬�����cuda��ptx��gpuʲô�ģ������Ƿ��㲻�ɣ�����Ҳ���ԣ���˵�Ѿ��ڸ���Ϊ��оƬ���������� ��Ȼ�������ҵ����ָ�Ҳ��ͳһ���ǽ������п��ܣ�����һ������java��jcp��gpu�ϵ�vulkan��khronos������һ����������ai��оƬ��ָ���һ����������ƣ��Ӷ�����java���ֽ����Լ�gpu��spir-v������һ������Ȼ�����aiоƬ���ṩ�������ֽ���jit��ʱ�����ָ�ִ�е���ôһ������ ��ds���֤���ˣ��ҿ���ֱ����ptx�ϱ�̣�������ڸ����������ң�Ӣΰ�ﲻ���DZ����Ψһ����Ը�����Ͳ��룬��Ը����룬����Ҳ����û���Ͳ��У�����Ը�������Ǿͱ���������������һ�����Ը���ȥ���������˼ �����ڽ�����������java�ֽ����spir-vһ��ͳһ��aiר������ָ������������������� ������������֤����Ӣΰ������������DZ���Ʒ��ͬʱҲ���й��ij��ң��ڽ������ܳ��ֵı��ƶ��ϣ������㹻�Ļ���Ȩ��Ӣΰ��һ���Ӵӱ�������һ����ѡ�� ��һ�����죬�������㣬����������ô���ֽ��룬���Ƕ������ֽ��� Ӧ���ܹ��뵽һ�� �Ǿ��� ��Щ�ֽ���֮�䣬�ܲ��ܻ��෭�밡�� ��Ȼ���� ���������Ѿ��в��ټ������������������ֽ���֮��ķ��� ����java��babylon��Ŀ������ͨ�����뷴�䣬��java���ֽ��뷭��������ĸ�ʽ ����spir-v�ֽ��룬����������Ѿ�����Ƶ�� |

|
|
�ҽ�ͼ��ȫ�ˣ��������� ����˵�����java��ǰ�ؼ�����Ŭ���ķ���֮һ �������Է����spir-v����ȻҲ���Է���������κ�һ�ָ�ʽ��ֻҪ��Ը�� ������֮ǰ�Ľ�llvm��ir�����java�ֽ������Ŀ����graal��sulong��������Ŀ�������� https://github.com/oracle/graal/blob/master/sulong/README.md?github.com/oracle/graal/blob/master/sulong/README.md ����ֻҪ��Ը�⣬�����м��룬�ֽ��뷭����κ�һ������Ҫ�ĸ�ʽ����˵��ָ�������ִ�� ���������Dz�����չ�Ծͱ�cudaҪ��ö�ö��ˣ� ��Ȼ�����˶�֪��Ӣΰ������ĭ��ֻ��û�뵽������ô�죬���� ��˵һ�� �������˻��ֱ����д����Ļ�����������¸е����� ��Ȼֱ����ô��������� ����Ҳû���������ô���� ��Ϊ���ڴ�ѧ��ѧ�Ļ�࣬�Ǹ����� cpu ��ָ� ��һ�ξ�˵�ˣ�cpu�ǽ��ڣ�gpu��Сѧ������˼���ǣ�gpu��ָ������cpu���ԣ���Ҫ�� ������ ai �ϵ� gpu ָ�������ͨ gpu ��ָ�����Ҫ�� ������������ȣ����� cpu ��ָ����� 200 ����ָ�� ��ô gpu ��ָ���������϶������ 200�࣬����ֻ��100�������������٣����������ֲ���Ҫ����֪���� cpu ָ���پ����� �� ai �õ� gpu ָ������ͨ gpu ָ���������٣�����Google��˵���� tpu ���ܺ�ֻ����ͨ gpu ������֮һ ��ô�������������ȣ������ gpu ��100 ��ָ���ôai �õ�ָ���Ƕ������أ� 30���� ����ʵ���������д�Ļ��ָ��Ѿ��Ǿ������־�����ָ� Ҳ�������ѳ̶ȣ�����û�����ڴ�ѧ����д cpu �õĻ��ָ����ô���� ����Ϊ ai �õ� gpu ָ�����ô����������������ʵ�γɲ���ʲô���Ǻ� ����Ӣΰ��Ҳ�����������ڻ��Ǻӣ������ڴ˻����ϣ���cudaҲ����nvcc�Ǹ������� �Ǹ���һ����������c�Լ�һЩc++���Ե���չ���Ǹ��ܸ��� ������������˶�ȥ���Ǹ�������������ż��ܸߣ������м����һ�㣬���е��������ĸо� ��deepseekֱ����� gpu ָ������ڸ����㣬�������Ķ�������Ҫ��ָ���ʵ����Щ ����Щָ���ʵ��������̶��Ѿ��о�Ʒ�ˣ�����gpu�Լ�asic�Ŀɲ�ֹӢΰ��һ�� ƻ����AMD����ͨ��Google��Щ������ deepseek��˵�Ѿ��ڸ���Ϊ�Ӵ�������Դ�뷭��ɻ�Ϊ���оƬ��ָ���˵һ�Σ����ָ����Լ��Ա�cpu��ָ���Ǿ������ּ�ľ���ָ������Ѷ��ϻ��½����� ��ʵ���Ŷ��ܲµ����õ�����Щ����ָ����ǼӺͳˣ���Ҫ�Ǿ����õ������� ����֮���Ի����� gpu��Ҳ����Ϊ cpu��gpu���棬gpu�ܹ��ṩ�Ƚϳ��췽��ľ������㹦�� ����������ص�����������Ǻܼ������ϣ����ڴ�ѧѧ�����Դ�����֪���ˣ�ѧ������ɣ�֪������ij˷�����ɣ�Ҫ��һ���к�һ��������ˣ���Ҫ����������һ�������ˣ������Ǻܼ����㣬���ǼӺͳˣ�û���ر��ӵ����㣬����Сѧ�����⣬���������������ر��ʱ ��Ϊ�������ּ��㣬����ָ����ʵ����Ҫ���٣����Ǽ��������� ����ѫ��ʱ�����Ͳ�֪����������ai�ϣ������������������������ɶ�ã� ��˵����������Ϸ�������أ�������Ҳ��֪���� cuda�����Ͳ��ǻ���ѫ�������ģ���˹̹����ѧһ��ѧ���ڶ����ڼ�����cuda���������ֽ���Ian Buck���������ϵ�gpu��������cuda��Ȼ���ҵ֮��������ְ��Ӣΰ�����ʱҲûɶ��ѡ�ģ�cpu�ֲ��ó���������㣬ֻ��gpu��������ʱ��Ҳû��ai�õ�asic��asic���ڸ����оƬ ���ڲ�һ���ˣ����ڸ���aiר�õ�оƬԽ��Խ�࣬����ֻ��gpu������������� ���ڴ�ҵ�˼Ҷ��������ܺĵͣ����˵�aiоƬ��������gpu �������ֻ��cuda����cuda��֧������оƬ������������оƬ������Ҳ�ò��� ������dsֱ����ptx�ϱ�̣��ǰ�ptx��ָ��ת�����������ҵ�ָ�������������� Ҳ���ǹ�ptx����ѹ���γɲ��˻��Ǻ� �ٶ�˵һ�� ֮ǰ������ ��������ͻȻ���������˵�� ��˼�ǣ�������ȫ�����붼��ptx���ֽ���ʵ�ֵģ�����һ����������������ԣ�����c/c++����һ������ptx �ԣ���ʵ����������һ��ͼ����һ����Ƶ����������������濴һ�� ���ܿ�������cudaΪ����cuda������c���Լ�����c++���Ĵ��룬Ҳ��ptx���� ��ôc����c++����Ĵ���������cpu��ɵģ���ptx���������� gpu ��ɵ� ����ʵ�����ı���Ӧ���ǽ� �� ptx ��д�� gpu �Ĵ��밡��Ƕ�뵽 c����c++������ȥ �������ʵ����֮ǰ��������ȫû�н��ı�Ҫ���������˾�Ȼ���������� ���д��붼�� ptx ��д����������Ǵ���̧�ܣ��ǾͲ�������һ�� ��ʵ��ʵ�ʹ����У���������� ai ���룬����Ҫ�� ai оƬ�����Ĵ��룬��Ƕ�뵽 cpu �����Ĵ�����ȥ�� ���罫 ptx Ƕ�뵽 cuda �� c/c++������ȥ Ȼ�����ٿ�һ���ҽ�ͼ�е���Ƶ��translate java to spir-v������������Ƶ�еĽ���֮�� �����˵�������������� �ͱ��� �� ffm ����һ����Ŀ ����ffm����ʵ���ǽ����� ������ Ƕ�뵽 java ������ȥ��һ���ֶ� ����Ͱ��� c ���� ��� ����ڱ�������У����� ffi��foreign function interface�����ǰ�һ�ִ��루����c����ࣩǶ�뵽����һ�ִ�����ȥ�ļ��� ����ʵ�ʹ����У���ʵ����Ҫ��д �ֽ��� ����Ĵ��� ��Ϊ�����ij�������ʱ������Ҫ cpu �� �����IJ�������������ȵ���Щ��������ʵ������ cpu ��ɵ� �� ai оƬ�������� ai�� gpu������ tpu��xpu��npu��Щ����ֻ���� ai ��صļ��� ��Ҳ������Ҫ�Ĺ����������ģ����ֹ������ʵĹ�������ʵ������ cpu ��� ��������˵�ģ������� ptx ��д����ʵ��˼�ǣ����� ai ��������� ptx ��д ��������Ҫ�ģ����ֹ������ʵĹ��������ǽ��� cpu ȥ�����������һ��ffi�ͺ��� ���������������ԣ�����ʵ���������� ����Ӧ��˵���������������Щ�궼�ṩ�ˣ����� ��� �����νӵ�֧�� ���� java �� ffm��swift�ȵ�Ҳ������ ����������ʵûʲô��˵�ģ���������һ�����⣬����Ȥ�Ŀ���˵һ�� ������֪�� ai ��оƬ�Ļ�����ԣ�����ptx���֣����ڿ��Ժ�����Ƕ�뵽�������������ȥ ����java��swift��python�ȵȣ������� ������Щ��������أ������Ĵ������ cpu ִ�У�����һ��aiоƬ���õ�ʱ������Ҫ��� cpu ʹ�� ������˵���еĴ��붼���� ptx ����һ����Ϊ�Ļ������ȥ��д��û�б�Ҫ ��������Ҫ���㷨��ʵ�֣����� ptx ʵ�ֵģ����ܹ��� ptx ʵ�֣������ܹ�������ai��оƬ��ָ��ʵ�� ����cuda���������ܣ�Ҳ����cuda���� c��c++д����Щ����Щ���ץ������������ffi������ ���ûʲô�ż��ˣ��������������������� c����c++ �Ļ����� ������ǰ��˵������ûɶ��ϵ��ʵ ����Ȥ�ģ��������� �������+ffi������swift + ffi�����ܲ鵽�����java����ֱ�Ӳ�ffm��panama ��ǰֻ��python��c++��Ƚϼθ�c��������������Щ�꣬�����������Զ��ṩ�����ƵĻ��������ܣ����ܷ��㣬֮ǰд�����ٻش�����Ȥ�����йۿ� |
|
��������Ѿ���X�����۹��ˣ� �ܻ��ȵ����� ���ȷ���һ�¹�����ڵ���ϸ�ش��ٽ����CUDA��PTX�Ĺ�ϵ�� |

|
|
���ķ��룺 ����˵��Deepseek ʹ���� PTX���������� CUDA �Ļ��Ǻӣ����Ӹ��������������������飬�Լ� CUDA ʵ������ʲô�� CUDA ��һ�ָ����ԡ���ʹ�������� NVIDIA GPU Ӳ���Ľӿڸ������ס����������ٵ��������ǹ�˾����ƹ�����ʹ�õ����ԣ�����Ϊ����ƶ�������ơ���������������������ǻ��� CUDA �����ġ�����ͨ�����ͼ����루��Ϊ PTX�����Ż� CUDA���������Ѿ����ڡ� PTX �������� NVIDIA Ӳ����������� GPU ������ԡ����ǵͼ����ԣ���������ϸ�Ż�������һ�����������Ҫ��Ӳ�����������е������зḻ��רҵ֪ʶ��֪ʶ�������ʹ�� PTX ��д������ƹ����ࡰ��ȫ���� CUDA �⡣�������ף���������ʱ����������У��������֪���Լ�����ʲô���������ڴ����õ����ܺ��Ż��� ���˵ CUDA �� C����ô PTX ���� ��ࡣ �������� Chris Sawyer��������ʹ�ø����ԡ� (����һ�¡���ɽ����ࡷ��һ��ͨ�����д����Ϸ�������� Chris Sawyer) Deepseek �����ǡ���ɽ����ࡷ��һ��ʱ�̣�������ɽ����ࡷ��û��������װ��Ϸ���˳��� NVIDIA �ϵĴ���ҵ��ʹ�� CUDA����Щ��Ҫ�ӹ��������л�ö��� 10-20% ���ܻ��ʵ��ˣ�����κ����ƶ����۴��Ҳ��ɹ��㷺����ģ�͵��ˣ����ѽ���� CUDA �����Ż��� PTX �������ǻ�ʱ������Ϊ����Ȩ����ֵ�õġ�ͨ�� PTX Ҳ�������һ��Ӳ��ģ�ͣ��������д�����룬�������ת���� ʹ�� PTX �� Deepseek �����߽� CUDA ���Ǻӡ�����ÿ���ˣ����������ĸ�����Ὺʼ�ֶ������ں���ʹ���Զ���� 7B ����ģ�������������������Ķ���ÿ 5000 �����ھͻ���ֶַδ���ʱ����Ҫĥ�����������츳���ܱ������ǡ�����Զ��ϣ���κ�������ʹ�� PTX����������Щ��Ҫ�����������Լ���ЩΪ�����������㹻��Ŀ�����Ա��˵���Ǿ�ף����ˡ������˽�����ʹ�� CUDA ���������� CUDA���� MLIR���ĸ����塣��ʶcuda��PTX�Լ�SASS GPU��CPU�Ĺ���ԭ�����������ͨ��ָ��������Ӳ���ﵽ�����Ч���� ����GPU��רע�ھ�����㣬��������������һ��GPU�Ľṹ�Լ�Ӣΰ����������CUDA��̬�� |
|
|
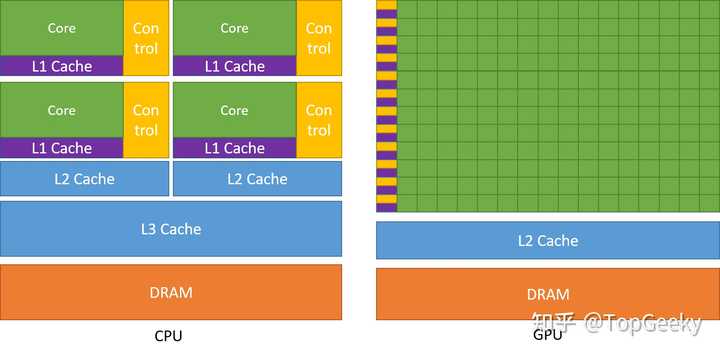
GPU��ʵһ�㶼�����ӣ� ͨ�������ṹ����ǧ���˽ṹ�������ò���SIMT����ָ����̣߳�ģ�ͣ�ͨ���̼߳����������ӳ٣�����ɸ��������������ܼ���������ͼ����Ⱦ����ѧ���㣩�� ��ʽ��ΪGPU�Ľṹ�Ƚϼ����в���CPU������GPU�ĵ�Ԫ������һ����������CPU�������еij�֮Ϊhost���룬��GPU�����еij�֮Ϊdevice���롣 ������̽��������Ӣΰ���ṩ��һ���м�������PTX��Parallel Thread Execution���������ھ���Ӳ�����ṩ������ָ���Ҳ����˵PTX��Ϊ��GPU��Ƴ����Ļ�����ԡ� �ڻ���������棬��������ִ��GPUӲ���Ļ�����SASS��Shader Assembly������PTX�������ɣ���NVIDIA��nvcc���������ת������ PTX�������࣬���ڿ��GPU���ݣ�SASS��Ӳ��ԭ��ָ�ֱ�ӿ���CUDA���ġ� ���磬PTXָ��add.s32 %r1, %r2, %r3�ᱻ����Ϊ�ض�GPU�ܹ���SASSָ� ˵���˵ײ����ԣ���˵˵CUDA��������ô�� CUDA��Compute Unified Device Architecture������NVIDIA�Ƴ��IJ��м���ƽ̨�ͱ��ģ�ͣ����̽ӿڻ�����չ��C/C++����ϸ���˵��CUDA������һ�Ŷ����ı�����ԣ�����һ������GPU�ı����չ�����ڸ����Եķ��룬���ṩ��ֱ�ӿ���Ӳ���������� ���������CUDA����һ��C/C++���Ե���ǿ���� ͨ�����ַ�ʽ������C++�ķ�ʽ��ֱ�Ӳ���Ӳ���� ����������ͼ��ϸ���������CPU�ı������ |
|
|
DeepSeek��������ʲô�� ˵������Щ����ôDeepSeek��������ʲô�أ� ����˵��DeepSeek����ͨ���ڴ���������CUDA�ṩ�ķ�ʽ����������Ż�z ֱ�Ӹ�һ���������ƣ�CUDA����������PTX��ɸ��ͼ��ĵ��� CUDA���ṩ�����ڴ����η���Warp�������ĸ��ӽ�Ӳ������Ż��ӿڡ� �����֪��C���ԣ����������C���Ե��е���CPU�Ļ����䡣 ����CUDA¢�ϣ� ���������㻹�����DeepSeek������CUDA��¢��ô�� ���������Ƕ�CUDA���������������ã�ͬʱ��GPU�ײ�ѵ�����������ϸ���⡣ Ӣΰ����ǿ��ľ���ʵ����CUDA��̬���൱�ڸ�GPU������һ�����ƻ������ԣ�ֱ�Ӳ���GPU�����һЩ����Ĺ����� ����˵��һ�¾��ǣ������һ���¼ܹ���CPU����ô�൱��Ӣΰ�������ָ��Ĺ�����SASS����������ԣ�PTX���Ľ������Լ��ṩ�˸����Ե���ǿ���� Ӣΰ��Ļ��ǺӾ���CUDA��̬�� Ӣΰ��Ļ��ǺӾ���CUDA��̬�� Ӣΰ��Ļ��ǺӾ���CUDA��̬�� DeepSeekҲ�������̬�������ߣ� ��ע�� @TopGeeky ���������ô�������������Ȥ��֪ʶ�� |
|
��עAI��ѧLLM�����ѣ����������������ȫ����PTX����CUDA¢�ϡ���PTX����Ӣΰ�ﻤ�Ǻӡ��Ĵ����� ����ʡһ��Ѽ����ɸѡ�ɿ���Ϣ�ijɱ� |
|
Ӣΰ����˺ü���û�㶨��Ȼ��DsspSeek�ݺݵĴ����� �������˵����Ҷ���֪�����൱���ƹ���cuda�����װ���˵ı�������ֱ���ø��ײ�����ԡ� �����֣�ţ�ƣ� �ݱ����������ڶ̶�������ʱ�䣬��2,048��H800 GPU��Ⱥ�ϣ�ѵ��6710�ڲ�����MoE����ģ�ͣ��ȶ���AIЧ�ʸ߳�10���� ���Ѷ�����Էױ�ʾ�� ������������ϣ��������Ⱥ�˻���˵����CUDA̫���ˣ��ɴ�ֱ��дPTX�ɣ������ֻ������Ծ�����Щǰ��������Ա�ˡ��� |
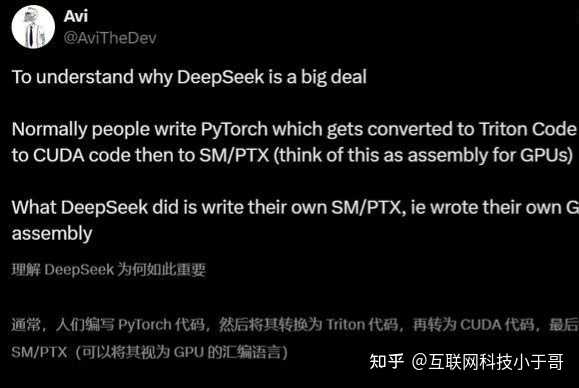
|
|
��Ҫ����д����������Ч�ʲ��ͣ���Ҷ�֪���������ƹ�ȥ������ѧ�˱���ԭ���Ķ�֪��˼·����������ai����ɹ��ƹ�ȥ����ǵ�һ�ҡ� deepseek ��ƽ̨��ͨ���ϲ�ת�� ��Ӳ��ƽ̨����Ӳ��ƽ̨���϶Խӣ�֧����AMD ��Ϊ�N�� DS���Ż����Ǹ������Ǹ����壬������Ӣΰ���оƬ����������Ӳ����ƣ�Ҳ�����Է���������оƬƽ̨�� |

|
|
����cuda��һ�ּ����������֣�����Ӣΰ����ײ�����ԣ���������˵����ds��������ڳ����ṩ�Ĺ��߲�������ô��ð�����ں�Ӳ�����ܱ���������ΪѰ��Ӣΰ��ƽ�潵�����ż���Ҫ֪��Ӣΰ��ǿ��IJ�ֻ�����ܣ�����cuda��������ԴҲ�����ơ� ӲҪ˵�Ļ���ֻ��˵����DS��������Ӳ��������Ż��������������ǿ��Է����ġ� |

|
|
�Ͼ����ģ��ѧϰЧ������˵������������Ҫ�����ܽ��Ҳ�����ڱ��ϻ���ai��չ�ļ����ڵ��������ˡ����������ƹ�һ�ΰ�ͨ�÷���д��������ô���������ƹ㵽�����ģ�͡� ������Ӣΰ����˵��Ҳֻ���ÿ�Դ��Сģ���������ʹ�ֱӦ�õģ���Ҫʹ��langchain��transformer��Щ���ߵ�Ӧ�ÿ�����Ա���о�û������ȥ�����ֵײ�Ŀ����ɣ� |

|
|
�����ֳ������棬cuda���DZ�����𣿻���˵Ҫ��ϣ��pytorch��TensorFlowȥ����Щ�ײ�ļ��ݽ���� ��������ΪGPU��ƻ����е㻤�Ǻӵģ���ȻAMDҲ�������ڱ���ȷ����߶�GPU��Ӣΰ��ľ���ת��ȥ���еͶ�GPU���γ�GPU������ǺӴ��� ֮ǰӢΰ����й����۸߶��Կ����¼���һҹ֮����Ӣΰ��ȫ��ڶ����г����ݶ���й����ٵļ�����ȫһ����������������IJ������й����õ��Ļ�����ôӢΰ���൱�ڶ��˰����Ѫ�� |

|
|
����Ӽܹ��ĽǶ��Ϸ�����CUDA���������Ƚ���������PTX,�ٱ���Ϊ����GPU�ܹ��Ļ����룬���Ǻ���Ȼ���ڡ�ԭ�������㣺 Ӣΰ���Կ����ŵײ�Ӳ���ܹ� PTX���ջ���Ҫ������Ӣΰ���GPU�� ������˵���������൱�ھ���Ӣΰ��ĸ���Ӣΰ��Ӵ˱�³ǡ� |
|
����Ϊ��ѧ����ѧ�ġ� Խ�ײ�Ĵ���϶�Խ��Ӳ������ �� CPU �������������˵���ƹ���C ����ֱ�ӵ��� ARM �� Neon ��࣬ʵ���ϲ����ǡ��ƹ��������Ǻ� ARM �ܹ��߶Ȱ��ˡ���Ϊ x86 û�� Neon��ֻ�� AVX���� CUDA �������� GPU ��̵� C ���ԡ� ��˵�ˣ��ѵ��ײ��Ż����������� HPC �Ļ��٣�DeepSeek ��ǰ�����������ģ���Ƶ�������ײ��Ż����Ǽҳ��㷹����Ҳ�ܴ�С�֣�ֻ��˵ѧ����ѧ�Ļ���ţ�ơ� |
|
��ѩ���������ַ����ˣ���PTX����cuda c������Ȼ�Ǹ�NV��cuda��̬�����ˣ��ⶼ�ܱ�ijЩ��˵�����ƹ���CUDA����ҥ�Կ��ȹ�̳��� PTX��¶�˸���Ӳ��ϸ�ڣ���NV���� ���CUDA C, PTXΪ������Ա�ṩ�˽�һ��ѹեӲ��DZ�����ֶΣ��������ḻ���������͡�����ȷ��rouding mode��������memory order������ϸ��ͬ�����Ƶȵ��ڶ�ĸ����ԣ���Щ�����Զ���NV��Ӳ�������������������PTX��д�Ĵ����CUDA C�Ĵ�����������ڷ�NV��Ӳ���ϸ��������С� ��cpu��Ĵ�����������c���Դ����������ֲ���ǻ������������ֲ�� PTX����һ�ֳ���Ա�Ѻõ�ISA��������bytecode �и��Ĵ�����PTX����ֽ��룬���Dz�ȷ�еġ��ֽ���Ҫ��������Ӳ��ϸ�ڣ�isaҪ������¶Ӳ��ϸ�ڡ����ֽ��루bytecode�����м��ı�����ԣ��������϶���������3-5�������������������½�������PTX��������Դ���10%�����������������м������ֶ����ܼ�Ϊ���еij��������̲��������bytecode���м�㡣 PTX��ȫ����һ�ֵͲ㲢���߳����������ָ��ܹ����ṩһ����Խ���GPU�������ȶ�ָ�����ͬ��bytecode����Ϊ���β�ͬ��ϵ�ṹ��CPU��Ӳ��ϸ�ڶ�����PTX���֮���ͳ�ֱ�¶��NV��GPU��Ӳ��ϸ�ڣ���PTXָ�����ʵ��Ӳ��ָ�SASS����֮һһ��Ӧ���ٲ���PTXָ��û��ֱ��Ӳ��ָ���Ӧ������ֻ��SASSָ��ļ���ϾͿ��Ա�ʾ�� PTX����ֻ��֧��NV�ҵ�GPU��Ҫ�������ҵ�GPU��֧��PTXһ�㶼����cuda c���ס� PTX�������Ŀ����Ѷȿ��ܻ�Ҫ����cuda c������ һ���棬PTXͨ��������ʹ���ڴ棬�����PTX��SASS��ת��������ͨ��һ���û����ʵ�֣�����������е�SSA�������Ĵ������䡢����ָ��ɾ��������������Ȳ���һ�������٣���������ȫ�����CUDA C�������� ��һ���棬clang��CUDA Cǰ���Ѿ��dz����죬AMDҲ��Դ��hip c��ǰ�ˣ����Ҫ����һ��CUDA C�ı�������ǰ�˲��ֻ������ò��ġ�����PTX����û�п��Ĺ�ҵ��ǰ�˿��á� �����У�PTX��ϸ�ڼ��䷱�ӣ���cuda c��ϸ��Ҫ��ö࣬��һ���ֵĹ�����Ҳ���١� ���ػ�����һ��Ӫ���ĺ������� |
|
PTX��ΪCUDA����ջ��һ���֣�ͬ����Ӣΰ���ר���� �����������Ǿ���������Ӣΰ��ļ���ר��������Ӣΰ��Ļ��Ǻӣ��� ����ʲô������������û�����ס� |
|
û�ƿ������Ǹ���AI�Ĺ�˾�ṩ��һ���µ�˼·�� ��Ȼdeepseek���Դ���CUDA��PTX����ե��оƬ�����ܣ�������AI��˾������Ҳ������ô�ɡ� ����������������������CUDA������������Ʒ�Ƶ�����оƬ��ʱ��Ҳ���Բ�ȡͬ���Ĵ����취�� ��Եģ�����оƬ��ƹ�˾���з�����оƬ��ʱ��Ҳ���Բο�Deepseek��PTX�������˼·�����Լ�оƬ����������Ե��з��� |
|
|
| [�ղر���] �����ر��ġ� |
| ���� �������� |
| ������ۻ�Ϊ���ɵ��ԣ� |
| ��ο���С��Sky Nomad С����̣� |
| С��Ϊ�β����ţ� |
| codex��windows��������ֻ����wsl�в��ǡ� |
| Ϊʲô����û�е��գ� |
| ��ο���ij��touch����ƽ������������ |
| �������������� |
| ��23��������������Dz���߯���ˣ� |
| �Ż�Ӧռ����ռ�8������㣬���ϰ�װ��ʮ |
| С�������ĸ����ɹ��� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
|
��������:
��ӰƱ��
����Ȧ
����
����
����
�����
ӡ��
�ɼ�
��س
����
��ˮ
��Ǯ�ҽ���ר��
����
˫ɫ��
����ĸ��
����
ƹ����
�й�Ů��
����
nba
�г�
�ܲ�
����
���
��ɫ
�Ϻ��п�
80��
����: ���� �����ֶ� ������ķ�ȴ� �ʼ������� ����ͼ˹ ���� ����� ���� �ﰺ ����ʥ�ն��� ���� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ֪ʶ�� |