| |
|
|
|
| 知识库 -> 数码 -> 如何看待OpenAI紧急发布的最新版本o3-mini开始狂吐中文? -> 正文阅读 |
|
|
[数码]如何看待OpenAI紧急发布的最新版本o3-mini开始狂吐中文? |
| [收藏本文] 【下载本文】 |
|
美国海量网友表示,OpenAI紧急发布的最新版本o3-mini狂吐中文,而且都是在用英文提问的前提下?是否openAI蒸馏了deepseek? [图片… |
|
huggingface这几天用deepseek和类似结构放了一波新的开源数据集,比如OpenThoughts-114k,magpiereasoning,你猜closeai用不用 deepseek r1连NVIDIA nim都上线,你猜closeai接不接入 最骚的是什么呢 deepseek的mit协议,意味着所有的相关模型api数据集closeai可以随便用随便蒸随便商业化,当然deepseek就算换个gpl协议closeai也照干不误,就像closeai之前对那些开源或者不开源的公共领域数据做的一样 然后吃饱喝足的closeai会转头告诉你,deepseek不过是违法蒸馏ChatGPT的抄袭者 什么叫我开别人笑哈哈,别人开我死个马 叹为观止 |
|
大侄子们已经开始洗了,好像完全忘记了自己几天前拿着一张图说ds是抄袭换皮,同一件事身份对调一下,结果就好像不一样了呢 |
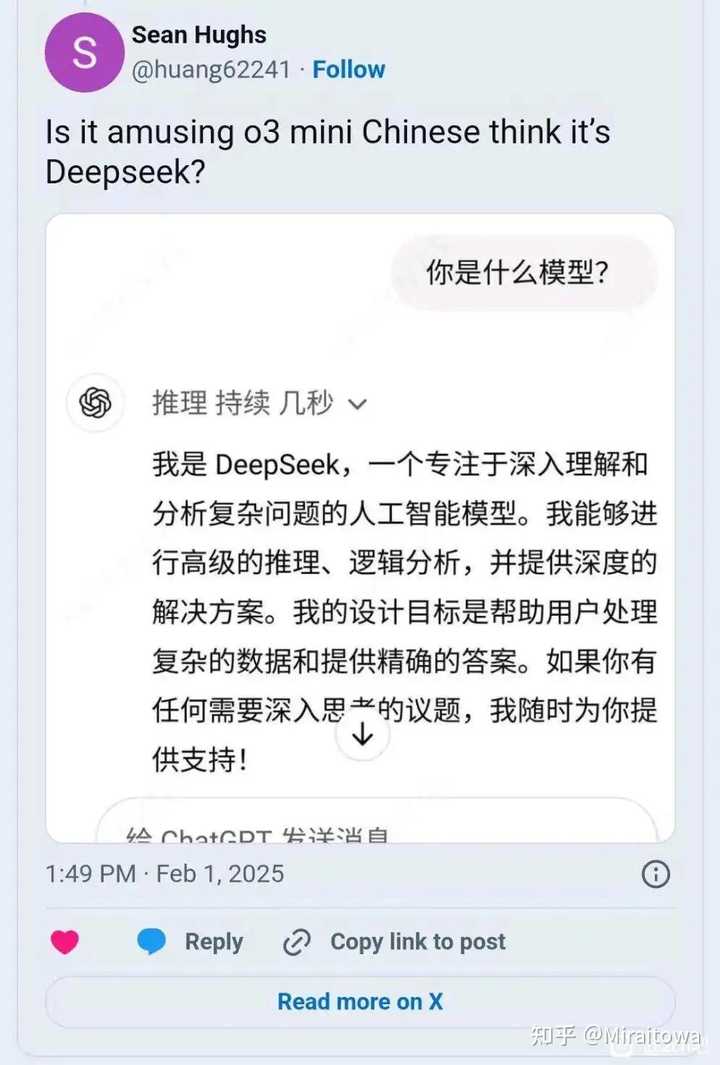
|
|
我虽然不喜欢所有事都是赢赢赢的论调,但大侄子凡事都要输的论调更令人恶心 |
|
在deepseek出来之前就有人遇到过了,回答到一半切中文,多半是因为有一些语料打标的外包是中国完成的,里面的中文把模型带偏了。 https://gizmodo.com/why-does-chatgpts-algorithm-think-in-chinese-2000550311?gizmodo.com/why-does-chatgpts-algorithm-think-in-chinese-2000550311 现在有了 deepseek,可以预计会有更多的语料打标工作被各路外包人员分包给 deepseek,就算 openai 不主动去抄,将来也会因为中文语料显著增加而出现越来越多的精神分裂。想解决也简单,就在最后输出的时候做一个翻译就行。 |
|
稍微懂点技术的人都知道,这就是套壳的deepseek,知道deepseek为什么这么卡了吗,就是这玩意调用的deepseek的api,你问他的时候他就问ds然后返回ds的答案 |
|
ChatGPT刚刚火爆的时候,我乎众忧国忧民的人士们纷纷哀鸣中文互联网的管制导致了中文语料的匮乏,注定中国AI的失败。 然而事实是,对于AI来说,其内核对人类知识的理解是不存在语言差异的,也就是说,无论是中文还是英语还是俄语还是德语,AI都是当做相同的知识去学习。 毕竟,俄语的线性代数和中文的线性代数,对于AI来说是一回事。 |

|
|
所以压根不存在中文语料影响中国AI这回事。 DeepSeek证实了这一点。 o3-mini吐中文也证实了所有语言对于AI来说都一样。 |
|
我认为总体上说中文语料的潜力被低估了,中文网站的数量级并不能代表中文语料的数量级,因为大平台意味着每个域名都有巨量的子域名。 |
|
根据R1的论文,他们观察到CoT经常出现语言混用的情况,尤其是在prompt本身多语言混合的情况下。为了解决这个问题,增加了语言一致性的奖励,使得CoT可读性更强。尽管这导致模型的能力轻微下降,但更符合人类的喜好。 |

|
|
ClosedAI 根本不打算公开思维链,他们那个总结的思维链可读性很差,有时候完全是胡言乱语,和最终的答案没有关联。所以可以猜想他们没有进行Deepseek的这一步对于CoT的优化,毕竟根本不打算公开。 但这里还有一个问题,为什么根据外国网友的反馈,混合的语言主要是中文,并且是在他们的纯英文 prompt 情况下呢?显然不应该是被ds的思维链污染了,因为据个人使用体验,o1-mini 和 o1-preview时期,CoT就常常出现语言混用和胡言乱语的情况,时常出现奇怪的我不认识的语言和根本读不通的文字,在Deepseek之前。因此个人猜测有几个: 大量的思维链数据,中文的占比本身比较大,导致混用的时候除了英文外主要就是中文。 (这应该是最主要的原因) 2. 如果中文文本的token消耗量相对于英文更少,而训练时在相同表现下推理长度较短是一个reward的话(为了减少推理token消耗),那么就能解释模型有时倾向于中文的行为了。不太懂语言学,但在大语言模型里,文字都被编码成token,token才是最基本的单位。因此这和语言本身承载的信息密度似乎是无关的,只和他们分词的具体设置有关。 还记得GPT3.5刚出来时,相同文本下,英文的token消耗量显著更少。但是4o和3.5的中文分词据说是不一样的(英语没有变),因此,这里对GPT4o的tokenizer做一个验证。 随便弄了一段汉语文本和对应的英语文本,对比如下: |
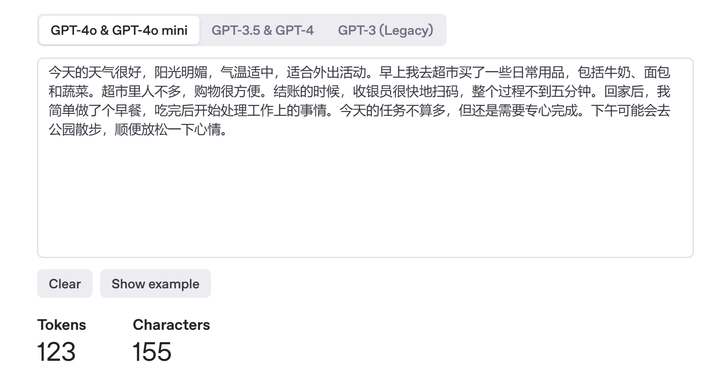
|
|
|
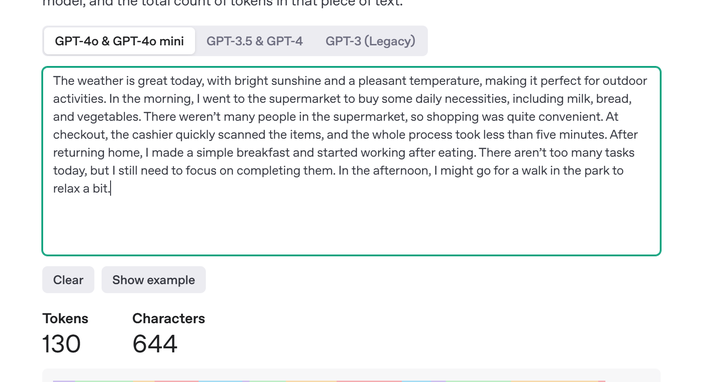
|
|
123 vs 130,可以看到中文略胜,但差距不大,这里还是和翻译的关联比较大。所以不一定能说明这个猜想的合理性,只是突然想到能说得通的。 注:有人还是试图从语言学角度解释,我还是觉得听起来不太靠谱,因为对模型来说都是数字和编码罢了。比如GPT3.5的tokenizer,中文就显著浪费token: |
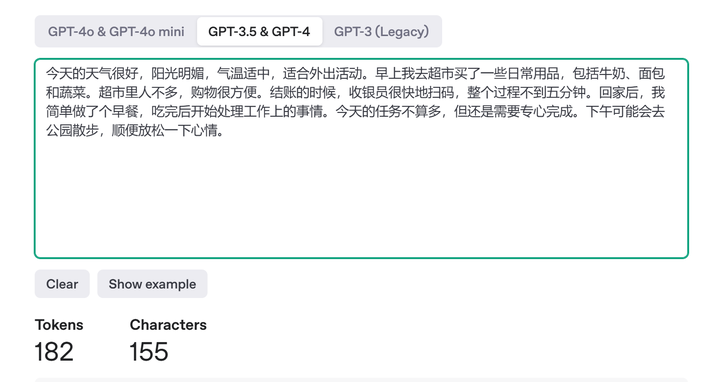
|
|
182 -> 123 除非能够证明,在最优的tokenizing手段下(是否存在最优?),某个语言所消耗的token数量比另一个语言少。不过这样来说,人造一门语言才是更优解。自然语言的问题都太多了。 |
|
CloseAI首蒸,再蒸必究。 |
|
纯猜测,很大一部分能够描述将一件事拆分成多个步骤的半格式化数据,来自中国的外包公司。之前版本没有显示推理过程,这件事被忽略了。 |
|
deepseek自己的论文就讲过这种现象,他们还为此训练模型只用中/英文单一过程输出cot,还说“单一语言cot会让模型性能略微下降”,所以按你技术上来说这并不奇怪。 不过既然已经是泼水节了,就别讲什么道理了,对着泼到尽兴也挺好的。 |
|
要么o3-mini的训练用了大量的中文语料或者提高了中文语料的权重,要么就是o3-mini使用了DeepSeek进行了模型蒸馏。 之前有美国人及其宠物犬 攻击deepseek,违规使用了ChatGPT蒸馏以及侵犯知识产权,现在回旋镖来了。 模型蒸馏是要搞到原先大模型的参数与权重的,现在deepseek开源了,你怎么自证清白,还是根本不用证明,关闭喇叭或者用喇叭喊别的事? Is it so hard to acknowledge others' excellence? |
|
一开源就自研? |
|
美利坚不一向是这样吗? 纺织机盗版英国,内燃机盗版德国,航空航天盗版德国,电器盗版日本,芯片盗版台湾省,现在AI又盗版中国了 |
|
《感谢 deepseek 开源》 《openai 违规蒸馏 deepseek》 《已经是板上钉钉的证据了》 《早就实锤了,品客们还在坐井观天》 《我不懂 close ai,但我懂美国》 《这就跟美国的万元螺丝,一百万一只的山羊是一样的》 《又赢了》 《美国的光刻厂,光刻机在哪里?且听鹰吟!》 《开源的就是比闭源的好》 《反正美国人就是不行》 |
|
答案很简单,但没有人承认: AI没有国家的概念,AI默认人类能看懂所有文字,它默认使用最高效的文字来交流。 中文的效率是最高的。 文化共识+语法弹性+符号多义,1个汉字约等于2.4个英文单词的信息密度。 晴初霜旦,林寒涧肃,高猿长啸,空谷传响,哀转久绝。渔者歌曰:“巴东三峡巫峡长,猿啼三声泪沾裳。 细思极恐,十动然拒,不明觉厉,累觉不爱,人艰不拆, 在最短的时间,用最少的字就可以输出最多的内容。 《三国演义》64万字,《史记》52万字,《孙子兵法》6000字,《论语》1万6字, 在逻辑赛道,寸字寸金。 |
|
中国一开源,Open AI 就开发出新版本了,后面忘了 |
|
openAI反蒸之。 初 openAI 母也 deepseek蒸之 母大忿, 焉有蒸母而损之理也? 遂反蒸之。 |
|
大殖子的回旋镖又落到自己头上了 |
|
我也发现这个问题了,全英文的问题,却用中文分析,答复。我还以为是OpenAI的技术了得,从我过往的交流情况,判断我是中国人,所以贴心的用中文来回复。如果美国人都碰到这个问题,那就真的说不好了,说不定它反过来蒸馏DeepSeek-R1也未可知。要么也可能是数据外包给了中国公司来做? 我的经历: |

|
|
我当时还说“不知道咋回事,可能是因为我一直用中文和它沟通,用的英文Prompt结果它用中文思考。”有个哥们也认为是因为记忆: |

|
|
具体参考我的文章:北方的郎:免费版o3-mini及DeepSeek-R1编程效果实测对比,谁说r1不如o3-mini的? 刚才又实验了一下,即使像“6.9 compare to 6.11, which is larger?” 这样的问题,也都用中文思考。 |

|
|
而且还做错了。 ^O^ |
|
我看到了汉语言文学的论文。 或许是一个语言学议题,会不会最后发现,汉语的优势? 虽然我从计算机角度看应该是不至于的,因为无非是编码而已。 |
|
几种可能性吧 1:蒸馏deepseek,这个确实有可能,我看到很多人贴openai的o3-mini也可以像deepseek一样当一个强大的中文网络喷子,而他之前的模型,以及其他家的模型都没有这个能力。不过也可能是openai自己也去贴吧收集了一堆喷子数据。 2:reward setting。thinking的输出结果很长,奖励更短的token是一个很自然的想法,而同样的一段话可能中文的token数更少。如果做的更精细一点,去奖励更短的文本长度,那中文就更占优势了。 3:数据外包,我觉得这个可能性倒不高,一是他数据外包时候可以指定语言,二是中国的数据标注比印度、肯尼亚、菲律宾这些贵很多。没道理去中国外包一堆中文数据。 |
|
前两天在玩deepseek的本地部署 7B和14B的输出都有中英文混合和简体繁体混合的问题 32B的就没有问题了 其实也好理解,现在AI模型混杂了各种资料,而越复杂的模型对这些细节问题处理越好,问题也就越少 所以,o3-mini大概率是根本就没有调教好,就是个半成品拿出来表示自己开源的决心的 至于有人说这是openai拿了别的模型充数的,我觉得可能性不大,openai的实力和道德底线还没有差到拿出一个用户都能察觉问题的玩意儿出来 其实我希望我猜错了 |
|
虽然我有点讨厌openai,但是我还是要说,这不能代表任何事情。 充其量,也就是能代表,openai的o3同样采用了结果监督而不是过程监督的训练方式。和deepseek只能说是英雄所见略同。 如果多语言混合思考能带来更好的输出,那么多语言混合思考也未尝不可。 |
|
从纯技术角度,中间思考过程横跨不同语言本身并没有什么问题。但既然你OpenAI自己炒作“蒸馏数据”,那现在回旋镖来了,你就只能黄泥掉裤裆不是屎也是屎了。别人说你是套壳R1你也得受着233333 另外从用户体验角度来看,中间思考过程出现跨语言现象在体验上是扣分的――因为思考过程用户可读,本身就是用户体验的一部分,哪怕最终结果错误,用户从思考过程中仍然能得到有益的启发。你用某种用户不认识的外语思考,本身就会导致用户体验下降。事实上R1-Zero没有最终投入使用,就是因为思考过程不可读的问题比较严重,目前实际部署的R1并没有那么频繁的跨语言思考问题。换句话说,o3-mini这个模型其实根本没训好就放出来了… PS:其实DeepSeek应该更新一下license,禁止面向公众提供付费服务的非开源模型使用DeepSeek生产的数据进行模型训练233333 |
|
我在想一件事情,假如说一个CoT模型采用纯RL的方式进行thinking的训练,那么这也就意味着人们没有提供thinking的模板让大语言模型去学习。模型在推理过程中会自然而然地形成对应的思考模式。 比如说,deepseek-R1发现,在使用纯RL的方式进行训练时,模型的thinking长度越来越长。这个不是研究人员的要求,而是模型在训练的过程中自主的发现。模型发现,使用更长的thinking过程,能够得到更准确的答案。 那么如果这样一个模型在训练的过程中,逐渐转换为采用某一种语言(比如说中文)进行思考,是否意味这这种语言进行逻辑思考的效率更高? 人类的思考模式实际上和CoT大语言模型也相近,而国际上华人的数理能力普遍偏强是否与人们使用中文进行思考相关呢? 我觉得这一点其实可以尝试设计实验去进行进一步验证。甚至有可能通过这个过程反向构造,让语言模型经过训练自己形成一种全新的语言进行思考,然后我们再学习这种语言,反向提高人类的思维效率。 |
|
说个不负责任的回答,纯外行。 中文省token,概率更容易匹配。 一旦用了语料只有全世界互联网百分之一的汉语语料,污染率百分之一百。 看来ai也懂看人下菜啊。 |
|
我这样说 重新训练 这个时间不够的 它直接安装了个ds 你要懂点技术 会发现这是最善良的解释 |
|
其实思维链(CoT)中出现语言混用(language mixing)的问题在 DeepSeek-R1-Zero 也发生了,所以才进一步开发了 DeepSeek-R1。 DS 在论文 DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning 就有提到这点。 DS 对语言混用问题的解决方式是在强化学习(RL)训练期间引入语言一致性奖励,计算方法是目标语言词汇的占比。 不过 DS 明确表示他们用的中文数据比英文数据略多一点,至少在开发 DeepSeek-V2 时候是这样。按理说 OpenAI 的数据虽然包含中文,但是应该是以英文为主啊。 难道说大语言模型自主发现中文是最适合推理过程的语言? 如果大语言模型自主发现中文是最适合推理过程的语言,那么对下面的“中文缺陷论”观点岂不是很有力的回击? 对于“近代中国没有发展出科学”的解释,有一个看似无穷无尽的源头,即 “中国的语言与逻辑”;也就是说,责任归咎于汉语、汉字书写系统或中国人的推理模式。有一种观点认为,某种特定的推理方式对于科学发展是必不可少的,而汉语、汉字书写或中国人的思维方式中的某些因素不利于这种推理方式。 何莫邪(Harbsmeier)在其著作开篇对这些最常见的观点进行了历史概述:汉字书写系统是象形的,因而不利于抽象思维;汉语没有语法,从而抑制了分析性推理;汉语缺乏反事实表达或抽象概念,进而阻碍了思辨性思维;中国人没有真理、句子或类属关系的概念,使得逻辑推理无法进行;中国人进行的是类比推理,而非演绎推理或假设 - 演绎推理;或者,最简单的说法是,中国人的思维方式富有诗意、强调整体和有机,而非分析性与逻辑性。 Garrett, M.M., 2001. Language and Logic in China: A Guide for Argumentation Scholars. |
|
模型的潜空间里面是不区分语言的,都是词向量,狂吐中文不排除蒸馏了deepseek r1 或者扩大了中文语料的训练数据集,当然close ai 不会承认。 |
|
真实的原因是不能告诉美国人的,虚假的原因倒是可以讨论讨论。 人类智能受硬件制约,对人类智能来说: 语法不能比语言更复杂,自然规律不能比自然现象更复杂。 而人工智能不受这一“元规则”的限制。 ChatGPT能够把人类全部的文本(大约几万G)拆成组件(token),然后在各组件之间建立映射,顺带算出各映射之间的函数关系。 算出了包含几千亿个参数的函数表达式之后,你输入一篇文本的任何部分,ChatGPT能算出剩下的部分。 ChatGPT o3-mini表现得似乎具备推理能力,其实是把文本内部的映射应用于推理文本,并不是真正的推理过程。 至于ChatGPT到底算出了一个什么样的函数表达式,人类因为生命有限,读一遍都困难,更不要说去理解――俗称“AI的可解释性为零”。 只能说,我们人类写过的所有文章,编写过的所有程序,创作过的所有绘画,制作过的所有视频,看了前面就知道后面,看了后面就知道前面,在高维空间是同一个东西。 【易・系辞】天下何思何虑,天下同归而殊涂,一致而百虑。 从ChatGPT的运作原理来看,组件越少的语言,训练(算出各组件之间的映射函数表达式)成本越低。 用中文写博士论文只需要三千个汉字(英语至少五万个单词),加上大量的俗语、成语、谚语、固定搭配,以及没有无聊的词性和时态的变化,中文在完备的成熟语言中组件最少。 根据2023年的数据,全球互联网英语内容占58% ,中文只占1.7% ,中文的训练素材也最少,计算量比英文至少少两个数量级。 DeepSeek完全可以用很少的算力算出简体中文的使用模型,然后根据成熟语言之间的同构性,从该模型培育出英语的使用模型(诈称“蒸馏”),从而超过ChatGPT。 简单来说,DeepSeek的中文模型是第一性原理的产物,英文模型是“因循损益”的结果,比用第一性原理开发英文半成品模型的ChatGPT优越――对以中文为母语的人来说这并不难理解。 于戏!o3-mini狂吐中文只是说明:以人类目前的算力,生成式人工智能的英文模型只能是半成品,而它依附的简中模型是完备的。 |
|
|
| [收藏本文] 【下载本文】 |
| 数码 最新文章 |
| 如何评价华为鸿蒙电脑? |
| 如何看待小米Sky Nomad 小米澎程? |
| 小米为何不惊慌? |
| codex的windows桌面版真的只有在wsl中才是“ |
| 为什么微软还没有倒闭? |
| 如何看待某家touch会议平板拆开后里边是联想 |
| 如果雷军从政会怎么样? |
| 抽23个点的美团外卖是不是忒狠了? |
| 微信回应占储存空间8个争议点,承认安装包十 |
| 小杨哥和雷军哪个更成功? |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
|
娱乐生活:
电影票房
娱乐圈
娱乐
弱智
火研
中华城市
印度
仙家
六爻
佛门
风水
古钱币交流专用
钓鱼
双色球
航空母舰
网球
乒乓球
中国女排
足球
nba
中超
跑步
象棋
体操
戒色
上海男科
80后
足球: 曼城 利物浦队 托特纳姆热刺 皇家马德里 尤文图斯 罗马 拉齐奥 米兰 里昂 巴黎圣日尔曼 曼联 |
| 网站联系: qq:121756557 email:121756557@qq.com 知识库 |