| |
|
|
|
| 知识库 -> 数码 -> 如何看待AMD称RX 7900 XTX 运行 DeepSeek性能领先 RTX 4080S? -> 正文阅读 |
|
|
[数码]如何看待AMD称RX 7900 XTX 运行 DeepSeek性能领先 RTX 4080S? |
| [收藏本文] 【下载本文】 |
|
[图片] |
|
7900XTX的基础素质又不差,单精度、半精度、缓存、显存、显存带宽都很够,软件到位后必定比4080S强啊。 具体的,7900XTX的FP16性能有123T Flops,FP32性能则有61T Flops,另配备96MB Infinity Cache缓存。当然,又大又快的显存也是利器。 |

|
|
早在7900XTX发布的时候,媒体就铺天盖地的宣传过该产品在AI性能上的优势,当时受限于较高的门槛和复杂的操作,真正使用的人并不多,更没有多少明显的成果。现在过去了一年有余,其实也是AMD和用户不断优化的成果。 对比4080S,7900XTX的显存多了8GB,显存位宽多了50%,缓存多了27.5%,FP16性能更是直接高出135.2%。虽说FP8和IN8性能受限较大,但其余方面足够领先就有优势。 测试数据显示,在加载Qwen 1.5B量化模型时,AMD凭借缓存命中率优势,首token响应时间缩短至0.8秒,比对手快22%。这种“用缓存换带宽”的设计,恰好契合大语言模型对数据吞吐的变态需求。 咱们必须有这么个思路,AI性能和游戏性能/理论性能,也是能直接划等号的。 |
|
按我说,现在AMD最好的策略是用上一代的显存搞张64G版本的7900出来 当然现在可能赶不上了,但你下一代得赶上,只要性能强过4060全部用老显存颗粒,显存都24G以上 而且你AMD当年不是为了追性能不是在交火技术上积累深厚吗?全系交火,无限交火,别惦记臭打游戏的了,老黄那DLSS就是叹息之壁,那是一两代能解决的问题吗?拼好帧那玩意哪怕只有你光栅化性能的一半跑出来的帧数都比你高,而且还根本看不出,务实一点,直接全系大炼丹,大干快上,直接ai大跃进,每个人都可以本地端侧大模型,现在台积电5nm已经很便宜了,5nm+gddr6,土法上马保证比现在强 |
|
英伟达在游戏卡施展显存刀法是为了避免和自己家的数据中心竞争可以理解。 AAMD你怕个毛,自己数据中心本来也没多少份额,能从老黄抢一点是一点。 现在好了,英伟达5090有32G了,AMD你的大显存呢?给7900XTX放出来一个48G的驱动很难吗? 就不做。 |
|
农企真的是吃屎都赶不上热乎的。 别惦记这7900xtx了,这玩意卖不掉,送,所有靠谱的ai小组,不靠谱的但是有靠谱想法的组,一个字,送,别一张张的送,8张16张的送,找华强北做双槽化改造,牛逼组一次性送他妈的128张,或者买新epyc就搭着送。 这玩意的核心能上48G上48G,能上64G上64G,也是一个字送,最起码送他妈的一万张,这玩意一张算一万的成本,一万张才一个亿,一个亿够农企股票一天跌的吗,靠谱组一次最起码送16张,16×48=768,让他们可以跑全量模型玩,不管速度和可靠性咋样,先能玩起来。 不止要送GPU,CPU也要搭着送,别惦记着破烂设备钱了,先能把适配和生态推起来再说,CPU能跑全量模型,也一定有优化空间,双路能跑30-40token/s真就有点实用性。 炼丹平台因为融资,金融,还是因为别的原因,把平台上4090价格打的太低了,加上能双槽能改48G而且配套成熟,农企真不能再梦游了。 |
|
苏妈应该看到一条路了,虽然模型训练上,CUDA很强,但是模型结果出来了,推理这个过程,对算力要求不高,对内存/显存要求高,而实际上,显存又不贵,下一代只要每个级别的卡针对NVIDIA显存x2,价格持平甚至更便宜一点,AI企业用来提供服务的显卡就都会采购AMD了,再过几年别人反正买了那么多AMD卡,支持支持ROCm也合理,回头ROCm跟CUDA平分秋色了,也就能把NVIDIA的护城河打掉了。 多提一点,现在分布式训练很成熟了,单卡极限性能其实都不是啥护城河了。 |
|
deepseek真正掘英伟达根的不止是让所有大模型训练需求全部减少,英伟达供不应求的前景被破坏。最具破坏力的是不依赖CUDA生态,rx 7900 xtx本来流处理器就比4080s多,单纯光栅性能也比4080s强。甚至以后运行在摩尔线程上也不奇怪。皮衣黄现在知道割韭菜会遭报应,晚了。 |
|
农企的显卡真的是, 既没有英特尔B580顶着272 mm2芯片用台积电N5还卖2000,和英伟达在游戏显卡拼刺刀的决心(4060的die size 159 mm2 ) 又没有用GDDR6直接民用卡堆48Gb,多卡高带宽,硬上Ai的魄力。 就贴着老黄的定价能赚多少赚多少。 游戏玩家应该意识到,1080ti卖699美金的平价算力卡时代已经过去了。 想要原价买高端游戏显卡,指望红蓝绿大战,不如指望幻方用deepseek降成本。 (攒了钱结果没抢到5080的我抱怨两句 |
|
AMD应该第一时间出来说自己的9070xt能跑AI,而且比对手更便宜性能更好,然后立刻发布 结果在那扯7900xtx amd市场部的人开除三轮都估计有漏的 |
|
AMD挑战英伟达 除了表面的技术之争 还有很大的政治背景 那就是 拜登政府四年的虚假繁荣已经结束了 英伟达做为拜登的御用金融道具的好日子也结束了 |
|
较真的老外哥去验证了,结果发现新驱动7900xt加载的ai说话速度快了8.5%,但思考问题时间慢了3倍,而amd只公布了说话速度(每秒生成tokens的速度) |

|
|
|

|
|
|
|
本来农企RX8000系列旗舰卡都不会出,彻底躺平一代。 现在不赶紧坐起来出32,48乃至更多显存的版本猛吃这波流量。 |
|
大家有没有发现一个问题。 如果AI真那么重要,那么有前景,现在要扩建的是不是芯片厂。 不管是AMD还是英伟达,芯片是哪里来的? 芯片厂不大量扩建,就在那硬抄股价,争有限的产能。 怎么看都只是个金融游戏。 挖矿你说限量,还情有可言,因为挖矿产出是一定的,算力倍增,最终产出不变,单位算力产出减半。 可是AI不是啊。 |
|
我的4080S哭晕在厕所。 这不废话? 这玩意吃的是显存又不是核心。 同样跑32B,我的80S直接爆显存,但7900XTX刚好装满。 你说这怎么比? |
|
AMD要想在这次算力争夺战中,找回主场优势,需要做以下几件事情: 1.在美股完成私有化退市。 2.全部研发团队、领导团队,搬入杭州萧山第二水泥厂办公区。 3.在A股完成IPO工作。 4.在杭州萧山第一水泥厂建立芯片制造厂。 5.AMD领导团队,全部到北京办公,取得工作证、社保卡,参加北京机动车摇号~ |
|
AMD太需要在AI领域分一杯羹了。 虽然支持A卡的软件和模型越来越多,但大多数模型还不怎么支持A卡,就算能跑A卡,效果也比不过N卡。但没见有啥不能用N卡,A卡专供的模型,N卡限定的到是不少。 白花花的银子全让黄老板给赚了,只能赚点儿臭打游戏的钱,AMD能不急吗? 所以能有机会蹭热度就一定要上啊。 但实际上没太大意义,模型多了去了,本地deepseek模型本来就是严重阉割的,不如直接用线上版或者api,跑大一点儿模型需要的配置极高,有这配置的还想跑娱乐模型的基本上都会优先考虑N卡。 这种话基本只能说给那些已经有了7900XTX的人听听。 如果是想玩模型的,还是建议别考虑A卡了,N卡还是绝对的优先选择。 除非AMD宣布,A卡在大多数图像语音文字相互转换和生成的领域上已经达到或者接近N卡的水准了。 起码多送点儿显存吧,别像老黄那么扣。 |
|
AI现在不仅玩软件,还玩硬件,7900xtx的硬件参数可以吊打4080,结果呢? amd那个ROCm现在跑起来还一堆问题,你怎么跟英伟达玩?就像摩尔线程一样,理论性能有3060的性能,但是软件驱动跟不上。 自己也跑了一下,4080能跑过7900xtx就怪了,32b要20g,4080一共16g的显存,还得跟内存借点才能跑起来,7900xtx自带24g,直接跑就行,怎么比?大家都是24g显存,为什么不敢跟4090比? |
|
贴一下之前回答吧,这下是“我真的有一头牛”了。P.S. 我作为GPU程序开发者,完整的做了一套针对A卡的兼容,除了DLSS这种功能跑不起来,通用的功能都尝逝过,如果这都不能说服您,那确实祝您好运。 7900XTX和4080super和4080怎么选择??www.zhihu.com/question/623641410/answer/3389017063?utm_psn=1868717841013944322 |
|
|
|
|
很好。 各种显卡厂家CPU厂家,以DeepSeek的性能为目标去优化去加强。 其它硬件软件厂家也可以围绕这个目标提供新产品。 |
|
这不是正常的么?96组cu,6144个流处理器,24g显存。正常碾压80组SM,5120流处理器,16显存的小老弟。 倒是跟4090比还能领先这个比较迷。 毕竟4090是128组SM的大哥。 |
|
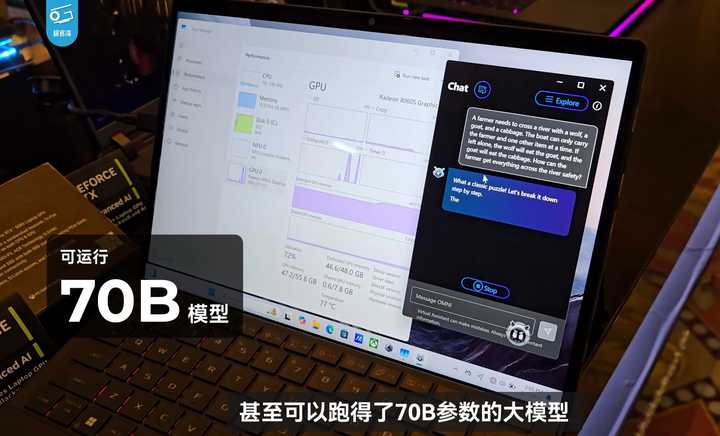
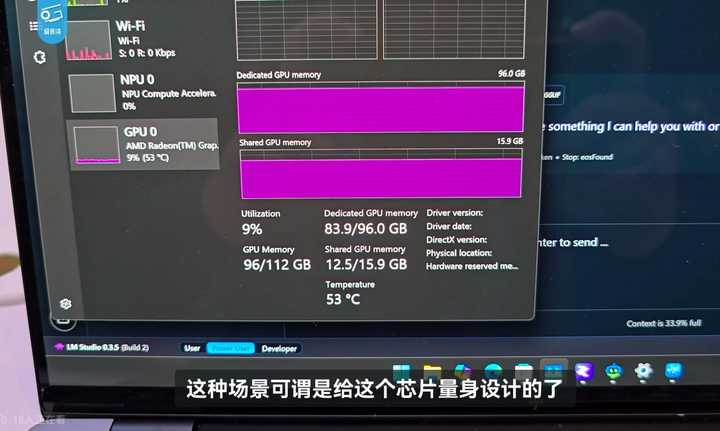
属于给7900xtx清仓而已。 目前AMD已公布最能打的消费级AI芯片,应该是AI MAX+395,采用Zen5 CPU与RDNA3.5 GPU 架构融合,16 核 32 线程,最高 5.1GHz,核显部分为40 计算单元,50TOPS NPU,TDP55~130W,支持4通道LPDDR5X/128GB统一内存(可分配96GB至显存)。 搭载该款芯片的移动平台将于今年第一季度上市,预计可较流畅运行INT8量化的deepseek 70B。 |

|
|
根据AMD自己的宣传,AI MAX+395在在 LM Studio(70B)中的 AI 性能测试中,相较于 NVIDIA GeForce RTX 4090 高出 2.2 倍之多,且功耗更低。 |

|
|
|
|
|
|
|
|
不过AI MAX+395毕竟属于移动平台,如果AMD能在未来推出桌面版AI MAX+芯片、类似于苹果M2Ultra将两颗M2Max封装在一起,再配合256GB统一内存,那么理论上可达1.7至1.8倍移动版性能,或可运行满血版70B大模型。当然大容量、高频率的LPDDR5X内存价格也非常感人。 |
|
这不是应该的么? 现阶段DeepSeek并没有针对AMD或者NVIDIA做专项优化,自然就是哪个硬件好,哪个算力强,哪个最终表现就更好。 我是麻薯,关注麻薯,不当韭菜不挨割。 AMD的优势在于: 更大的显存带宽与容量:RX 7900 XTX 有 24GB GDDR6 显存,显存带宽高达 960GB/s,远超 RTX 4080 Super 的 16GB GDDR6X(736GB/s)。 RDNA3 计算单元:AMD 的流处理器(Compute Units)在部分并行计算任务中可能更高效,尤其是针对 ROCm(AMD的AI计算框架)优化的模型。 NVIDIA的优势在于: Tensor Core 与 CUDA生态:NVIDIA 的 Tensor Core 专为 AI 计算设计,在主流框架(如 PyTorch、TensorFlow)中优化成熟,且 CUDA 生态占据绝对主导地位。 DLSS 与 AI 加速技术:RTX 40 系列支持 DLSS 3 帧生成和光线追踪加速,在游戏与AI混合负载中效率更高。 一个新的模型,没有针对Tensor核心和CUDA生态搞针对性优化,那自然就是把两个平台拖回硬件比拼上了。 有人要说了,现在不优化不代表以后不优化。 这句话没毛病,但是要明白优化不是显卡厂商在优化,显卡厂商给的是开发环境和工具包,优化是使用者自己优化。英伟达的CUDA生态立足之本不是4080S或者4090,而是A100,H100,V100们。 对于国内而言,买不到的东西,为啥要针对性优化? 国内的机场会针对F22战斗机针对性优化么?辽宁舰会为了针对F35进行优化么?法治建设会为了黑命贵或者犹太人针对性优化么? 至少对于投资机构来说,AMD还是太稳定了。 |

|
|
|

|
|
对了,DeepSeek自己是这么说的 |

|
|
|
|
严重怀疑 AMD 对其他美国模型支持不好,是这些美国 AI 企业不待见 AMD ,而不是 AMD 不争气 |
|
期待一下9900XTX 1tb疯牛病版,单卡跑满血DS |
|
很好但是我不想买RDNA卡了,赶快搞UDNA吧。 当然,按AMD的调性估计最快得明年了。苏妈路线图公布的似乎早了点,rdna4还没上市就是淘汰产品。 |
|
在可以想见的未来两家可以卷一下显存容量或者其他性能。当CUDA造的护城河有崩塌的风险时,老黄就必须用显存容量或者其他硬指标加固它。谁不是苦老黄挤牙膏久已了? |
|
牢黄的显存刀法纯纯跟苹果学的,黄金显存。 |
|
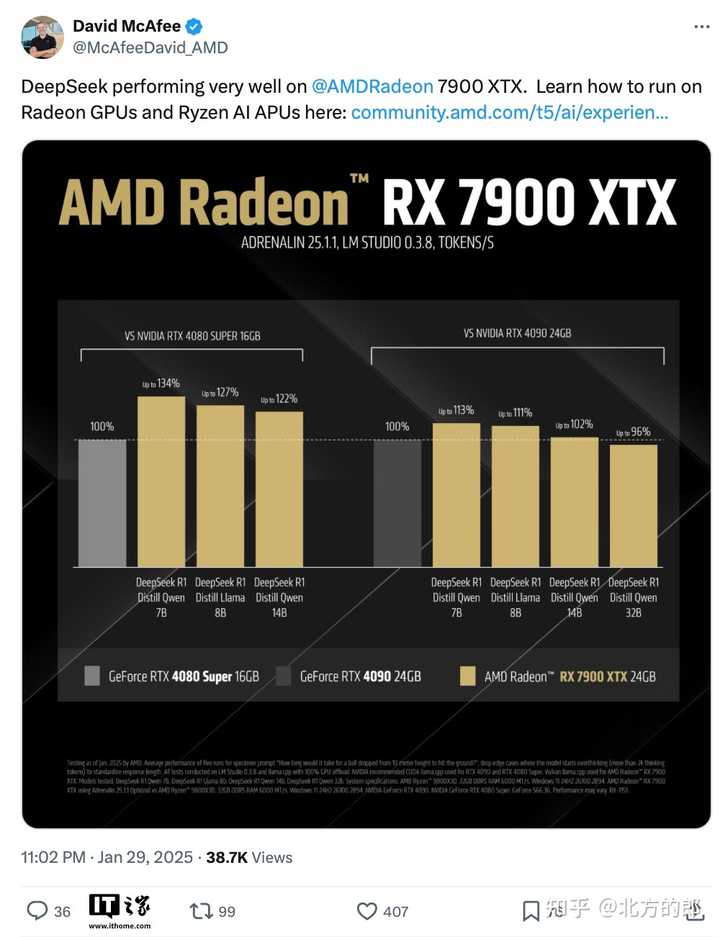
看AMD发的文章,跑的都是各种 DeepSeek-R1-Distill 版的模型。也就是跑一些小尺寸的模型。 |
|
|
|

|
|
全尺寸的DeepSeek-R1或者DeepSeek-V3,因为没有nvlink,估计AMD卡效果不会太好。 |
|
没啥好看的,运气好赌对了,对比NVIDIA和Intel,AMD一直是自视甚高且不愿意在合作方面投入的厂商: NV是多年砸钱搞AI,CUDA生态运营了多年,游戏ISV合作也是目前市场上做的最好。 Intel是前年开始砸钱做AI,有自家的Intel OpenVINO生态,游戏ISV也在做,没NV做得好且覆盖广。 AMD是真舍不得花钱,没自家生态不说,为数不多亲AMD的SteamOS也爱理不理,AI方面用SD的朋友应该知道有多膈应。 作为用户,DeepSeek既然能用AMD硬件,希望AMD主动点适配,太远的不说,移动端锐龙的NPU能支持就算胜利,毕竟移动端AMD的用户数量多,价格够便宜,比虚头巴脑的吹嘘更利好用户。 |

|
|
|
|
AMD是驱动不行 软件不行 不是硬件不行 另外我歪个题 这就忘了苏妈给蔡省长政治献金的时候了? |
|
参量小的情况下推理速度几乎只和带宽相关 amd在个人工作站上推理的最大的缺点是不支持system memory fallback,跑大模型全靠框架自身的offload,显存爆了就真爆了 nv这边不仅win应用支持system memory fallback,wsl2也同样支持,llm可以自动的使用系统内存,从而推理更大尺寸的模型 |
|
|
| [收藏本文] 【下载本文】 |
| 数码 最新文章 |
| 如何评价华为鸿蒙电脑? |
| 如何看待小米Sky Nomad 小米澎程? |
| 小米为何不惊慌? |
| codex的windows桌面版真的只有在wsl中才是“ |
| 为什么微软还没有倒闭? |
| 如何看待某家touch会议平板拆开后里边是联想 |
| 如果雷军从政会怎么样? |
| 抽23个点的美团外卖是不是忒狠了? |
| 微信回应占储存空间8个争议点,承认安装包十 |
| 小杨哥和雷军哪个更成功? |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
|
娱乐生活:
电影票房
娱乐圈
娱乐
弱智
火研
中华城市
印度
仙家
六爻
佛门
风水
古钱币交流专用
钓鱼
双色球
航空母舰
网球
乒乓球
中国女排
足球
nba
中超
跑步
象棋
体操
戒色
上海男科
80后
足球: 曼城 利物浦队 托特纳姆热刺 皇家马德里 尤文图斯 罗马 拉齐奥 米兰 里昂 巴黎圣日尔曼 曼联 |
| 网站联系: qq:121756557 email:121756557@qq.com 知识库 |