| |
|
|
| ֪ʶ�� -> ���� -> �б�Ҫ�Լ���deepseek�������� -> �����Ķ� |
|
|
[����]�б�Ҫ�Լ���deepseek�������� |
| [�ղر���] �����ر��ġ� |
|
�����Լ����һЩͳ�ƻ��ܺ���Ԥ��Ĺ������Dz����е���С���ˣ� |
|
ֱ��˵���ۣ��б�Ҫ �ټ������ӣ� ������ҵ���������еĿͻ����ݣ�������Ϲ�Ҫ��ҽ����ҵ���������߲�����ȷ��������˽������ҵ��ʵʱ��������ߣ���Ҫ���ӳ���Ӧ�����л��������ж��ƻ�ģ���о��Ϳ������������ҵ���������˽�����ƻ�����ʵʱ�Ի��ڳɱ������нϸ�Ҫ���Ҿ߱���Ӧ�ļ���������Ӳ����Դ����ô���в���DeepSeek��������һ��ֵ�ÿ��ǵ�ѡ��˳���̴�������10���������������ȫ���ػ�����DeepSeek-R1ģ�͡� |

|
|
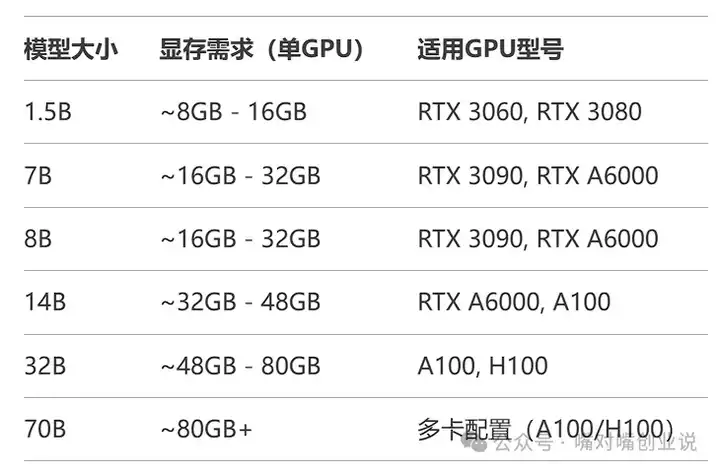
1.ΪʲôҪ�Լ�����DeepSeek�� ���DeepSeek�dz��𱬣���������д�İ��ͽ����о�����������ʵʱ�ش����⣬��������������ġ�С���ڡ��� �������������������������⣺ 1.�߷����Ŷ����˻������� 2.������ʱ�����ȶ� 3.����ʱ������ʹ�� ��ˣ����������̴��һ�����ɣ���DeepSeek��װ���Լ��ĵ����ϣ�������Ϳ�����ʱʹ�ã���Ҳ���ÿ�����������ɫ�� 2.ѡ���ʺ����DeepSeek�汾 ���ȣ����ǵ���ѡһ���ʺ��Լ����Եİ汾�� �����汾������һ���ʺ��㣺 1. С�ɰ棨1.5B�� �ص㣺������ʺ����ִ��� �Ե���Ҫ��ͣ��ʼDZ�Ҳ���������� ��ȫ�����ճ��칫���� 2. ���棨7B�� �ص㣺�������ߣ��ܴ����������� ��Ϻõ������ã�16G�ڴ��� �Ƽ���ѡ���Լ۱���ߣ� 3. ��ǿ�棨8B�� �ص㣺��ǿ���ܣ���������Ҫ��� �����и�����Ե��û�ѡ�� ��ͨ�û����룬������Ա���... �������³壬�ȼ������ĵ������ã� |
|
|
Windows�û����ڴ棺����8GB������16GB���Կ���Ҫ��NVIDIA�Կ���GTX 1060���ϣ�CPU��i5��������ͬ�ȼ��� Mac�û����ڴ棺8GB��оƬ��M1����¿�ϵͳ�����°�macOS 3.DeepSeekѧϰ��Դ �ٷ��ĵ���https://docs.deepseek.com/ ����ģ�ͼܹ���API �ӿ�˵��������ָ�ϡ����̵̳� GitHubʾ���ֿ⣺deepseek-ai/examples �ٷ�����⣨ģ�͡���������ʾ����Ŀ�� API �ĵ���https://chat.deepseek.com/503/ ��ϸ�ӿڲ���˵�������ʾ�� ģ�����أ�https://huggingface.co/deepseek-ai ���汾ģ��Ȩ���������ļ� ��ʼ���𱾵ػ��� ��һ������װOllama�������ߣ�����ΪDeepSeek�ġ��ܼҡ�������ȫ������� ȥOllama�������ذ�װ����https://ollama.com/�� |

|
|
���Downlod |
|
|
Windows�û������ Download for Windows Mac�û������ Download for Mac �ļ�������ɺ� |
|
|
Windows�û�˫����װ��Mac�û��Ͻ�Ӧ�ó����ļ��� ��װ��� �ڶ���������DeepSeekģ�� �л���Ollama������ѡ��Models���ҵ���deepseek-r1��������ѡ��7b���汾�����������У�����Ҳ�㹻�� |

|
|
|
|
|
ѡ��7b��Ȼ�����ұߵ� ollama run deepseek-r1 |
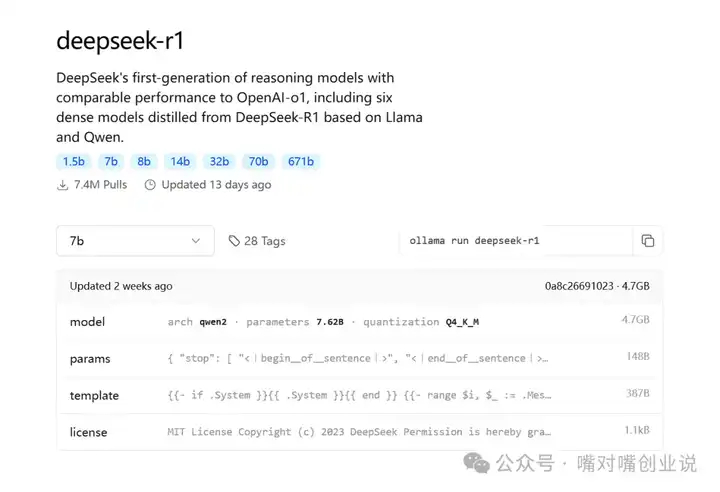
|
|
���������Թ���Ա��������������ʾ�� �������У�Windows��Win+R����cmd��Mac���նˣ� |
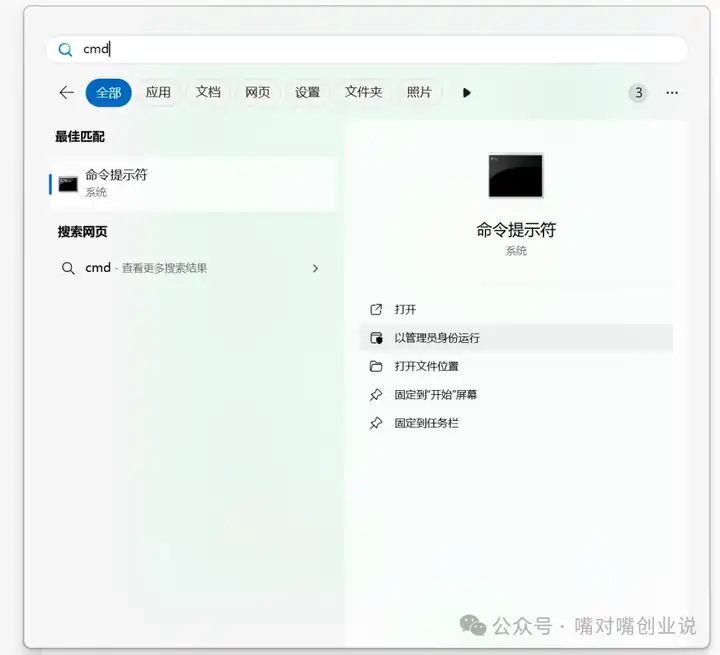
|
|
�����ճ�������У�ollama run deepseek-r1:7b |
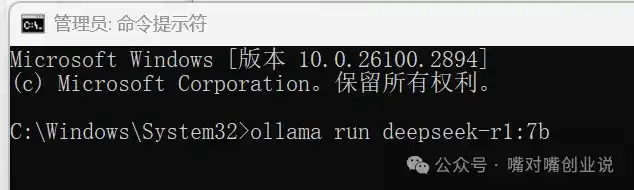
|
|
���ĵȴ��������... |
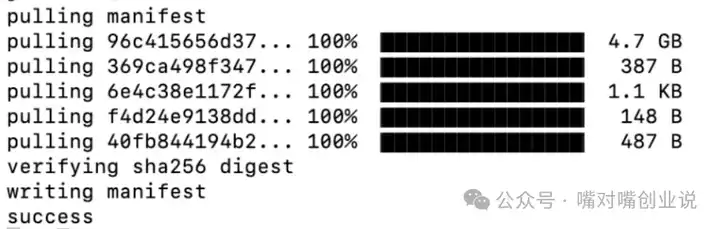
|
|
��װ��ɣ�������һ�� ���IJ�����װDeepSeek���еĽ��� ���ذ�װChatbox��https://chatboxai.app/zh�� |
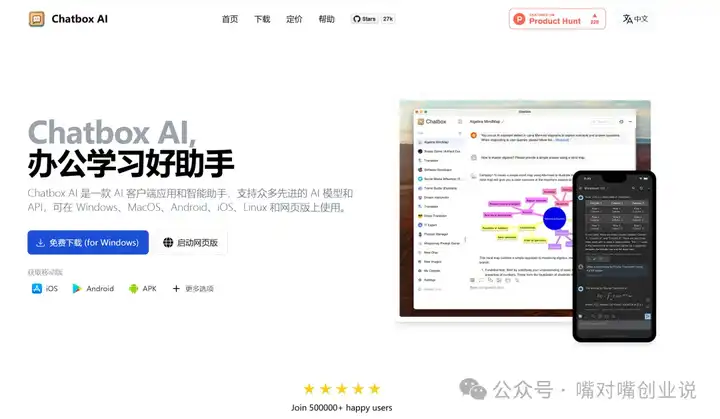
|
|
���������� |
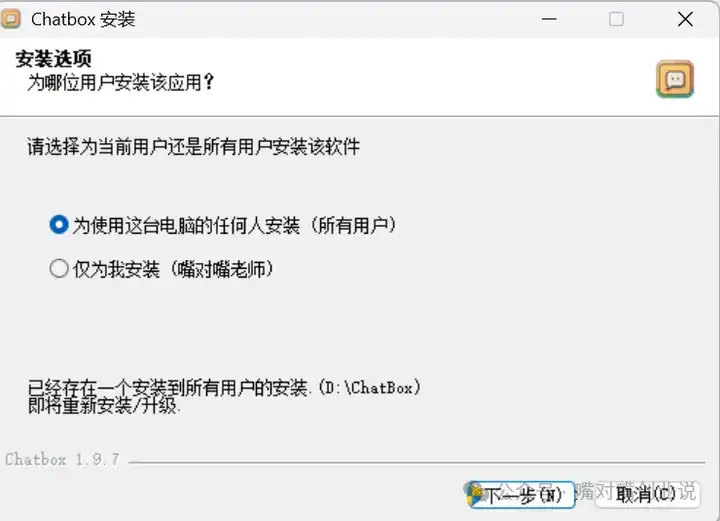
|
|
�����һ�� |
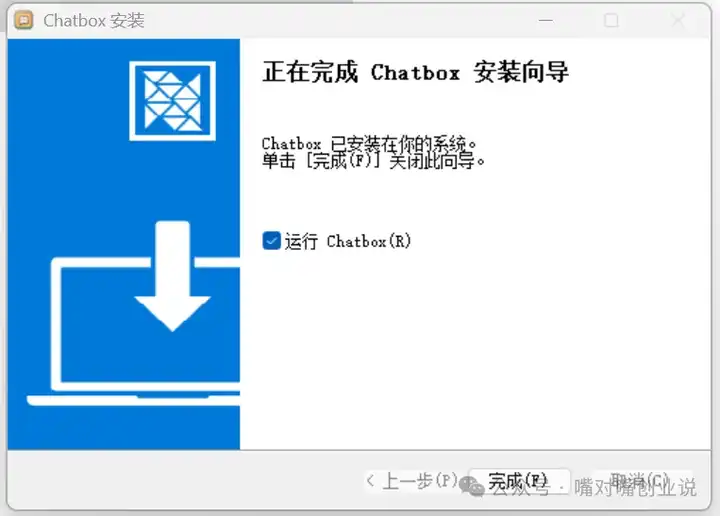
|
|
������ ����������ѡ��"Ollama API" |
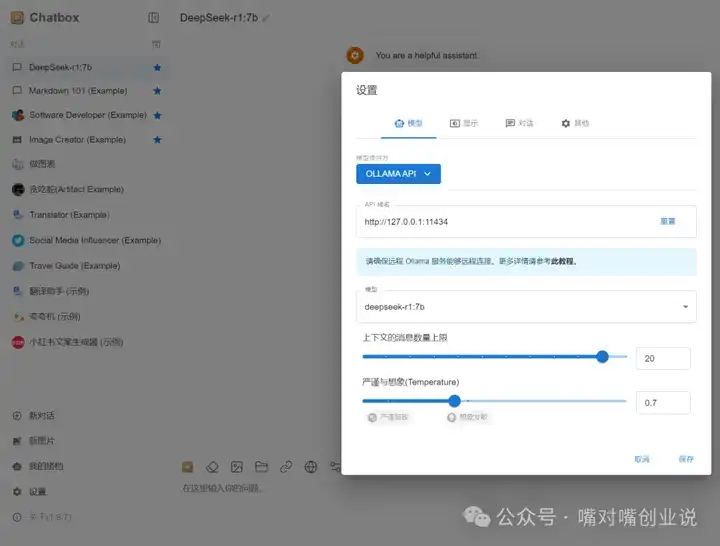
|
|
��ͼ������ ���岽��ʹ��DeepSeek ��ɣ����ز�������˼��������Web���������һ�£����������Է���ʹ��deepseek����Ҳ���ص��ķ��������ˣ� |
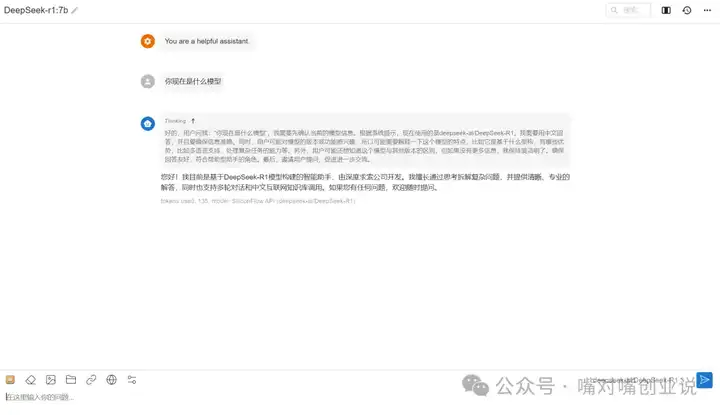
|
|
���ʹ���ƶ˰汾�� �����ĵ�����֧�֣����Գ����ƶ˰汾�� ��Ϊ�ض��û�������б��ز�����ã���ȷʵ�ᵼ�¹��ȡ���������7Bģ��ʱ��CPU�¶Ƚӽ�90�档 ȥ�����������ע���˺ţ�https://cloud.siliconflow.cn/i/q6F4qqBf�� |
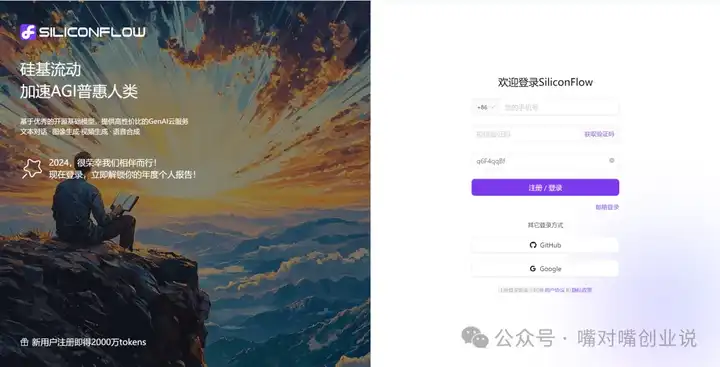
|
|
������ҳ�����ģ�㳡�����ҵ���DeepSeek-R1������ѡ���������顱�� |
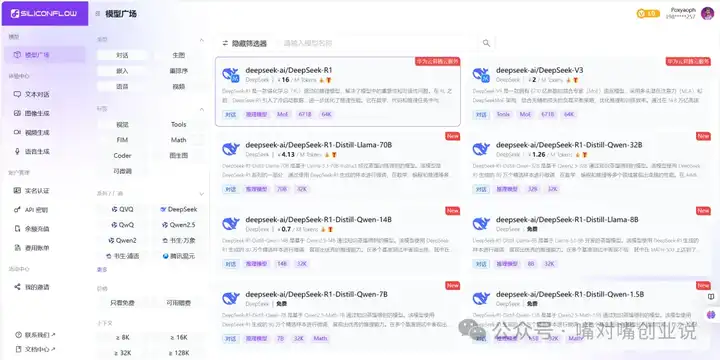
|
|
�����ѡס��ģ�� |
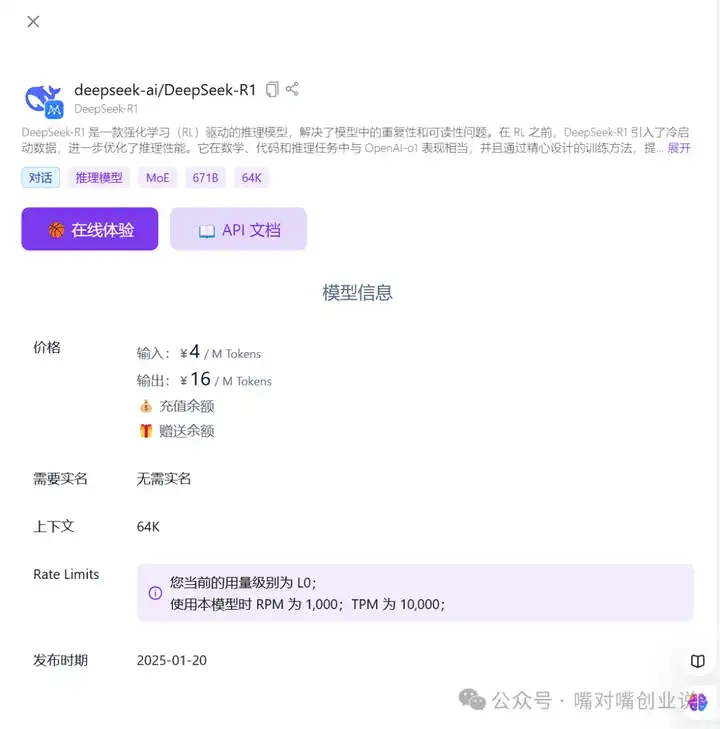
|
|
|
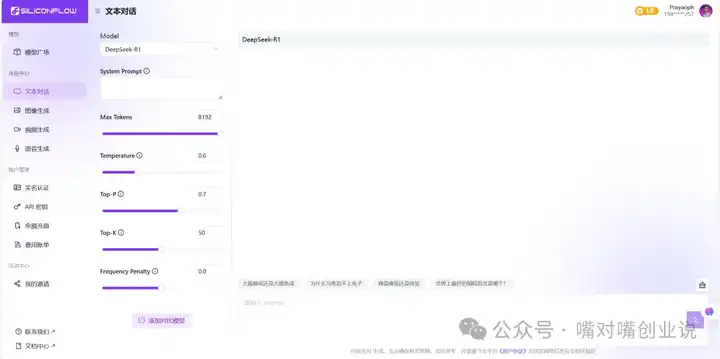
|
|
��ֱ�ӽ���ʹ�á� ��������ҳ����رյ����������ݡ�ʧ����������ͨ������API��Chatbox������Ч�����ѡ� ��Chatbox�Ͻ���������API��ֻ��������� �ص����������ҳ���������� ��API��Կ���� �½�API��Կ �� ������Կ |
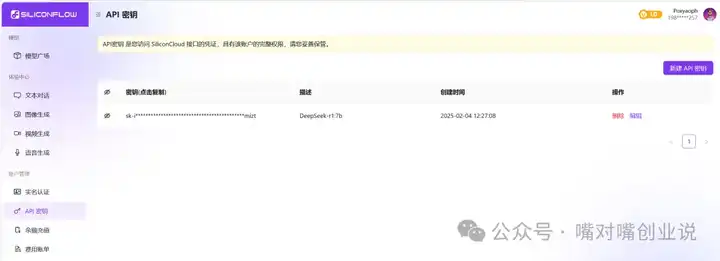
|
|
��Chatbox Ӧ��֮������½ǣ�������ѡ��: |
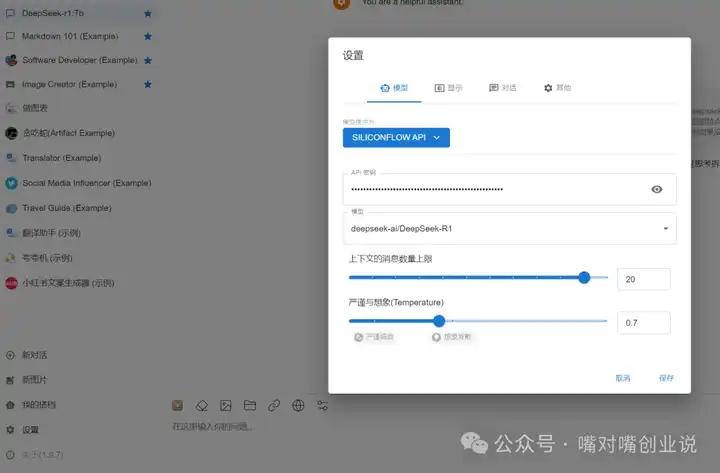
|
|
�������������ĺ������ƶ�����DeepSeek |
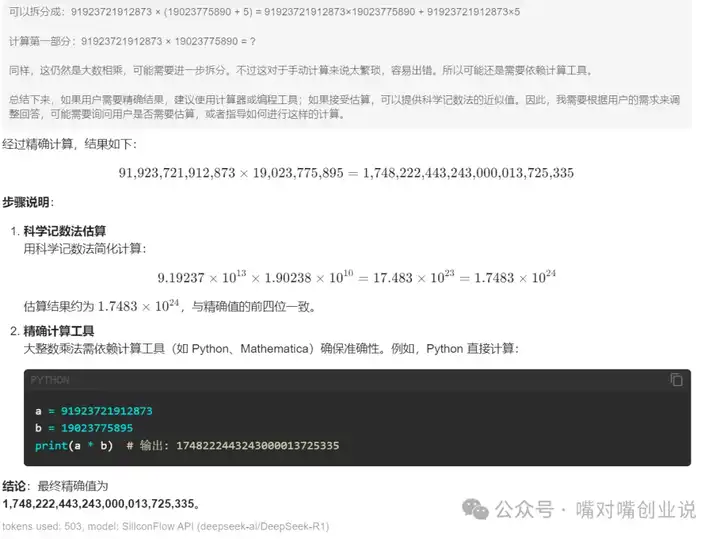
|
|
�ܽ� ͨ�����̳̣���������DeepSeek��ʹ�÷����������DZ��ز������ƶ����飬������������AI�ı����� �������ʣ���ӭ����������ͨȺ���ʣ��ڴ������� |
|
û��Ҫ�� ���˵��Դ�4090�������ˣ� ֻ���������汾�� ����������岻�� ������API�� 5��Ǯ��token�ò��ꡣ |
|
����˵��һ�㣬��DeepSeek��װ�����أ���Ҫ������Ӧ�ó����� һ���Ƕ���ʹ�ã��ܶ�ר�������Dz����������ģ�Ҳ�����������������ذ�װһ����ģ�ͣ����Ե�����������ʹ�á� ����һ����˽�л��������������֪ʶ�⣬��Ҫ�ǰ�����ҵ������רҵ�ķ��� �����Ҫ����ʹ�ã��Ҳ������ڱ��ذ�װDeepSeek��һ����Ե��Ե�����Ҫ��ߣ��㲻�û�����רҵ���Կ�����һ���������㲻������ʹ�õ����� ��Ҫ����ʹ��DeepSeek���ֵ��Ĺ������Dz����ã����������һ����������� ����AI�����ո��Ѿ�������DeepSeek-R1��Ѫ�档 ����AI��������ַ��https://metaso.cn/ |
|
|
����AI���������Щ�˲���İ�������AI�����������˸�������֪ʶ�⣬��������������д���ġ� ���ڼ�����ǿ���������AI���ߵ�ս����˲�������� ����AI����Ĭ���Dz���DeepSeek�ģ����Ҫʹ��DeepSeek�������������Ҫ���ء� |

|
|
����һ�����⿴��Ч�� |

|
|
�ȸ�����˼�����̣����Żش����⣬�Dz��Ǻ�DeepSeek�� �ش��ʱ���õ��˲ο����ϵĵط��������������˱�ע��������ĩ���õ��IJο����϶��г����ˡ� �������AI���ߣ���Ҳ���õ���DeepSeek�������ˡ� ����� ���ã��������ҵ�ڱ��ʣ����ݿ��ӻ�ר�ң�AI����ʦ�� 10���껥�����з��������飬�ҽ�������������ְ����֪�ͼ����ɻ�����ӭΧ�ۡ� ���ںţ�AI���ӭΧ�ۡ� |
|
DeepSeek-R1Ŀǰ���г��Ͻ̳�ϡȱ�������û���ʹ�ù����У�����ֻͣ���ڹ��ߵĻ����������棬��ԭ��֪֮���٣�����Ӧ��Ч�����ѡ� ��ԭ�������⣬�Ǹ�ЧӦ�õĹؼ��������ϣ������ר����DeepSeekģ��������ҵ���������ջ���ԭ�����ǵ���֮���� �ⱾС���Ӵ�20��ҳ��Ӣ�������������������ݣ�ͨ��ͼ��ķ�ʽֱ��չʾDeepSeek�ĺ��Ĵ��¡� �ֲ���ѻ�ȡ��ַ��10ҳֽ�ٳ�ͼ��ָ�ϣ�DeepSeek-R1ԭ��������ʵս����һ���� |

|
|
���ݾ�����ͨ��������ʹ�dz�ѧ��Ҳ���������֡�����ȫ��Դ��ѣ�����רҵ�Ű湤���������Ķ��������á� ͨ��ѧϰ�ⱾС���ӣ��㽫�����˽�DeepSeek-R1�Ĵ���֮�������մ�ģ�͵Ļ���֪ʶ�����ܹ��ɹ���DeepSeek�����ص��ԡ� �ֲᲿ������ |

|
|
|

|
|
|

|
|
|
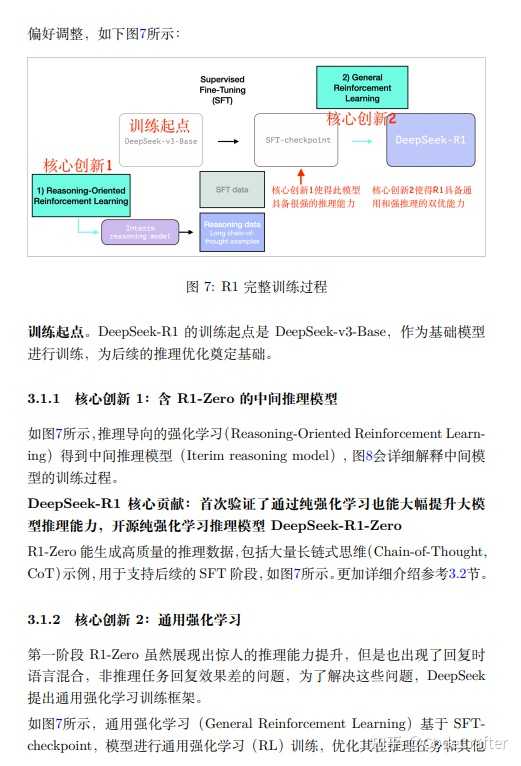
|
|
�ⲻ���ܰ�������õ�ʹ��DeepSeek-R1������Ϊ�����Ķ��ƻ��������¼�ʵ������ |
|
�����룬�Ժ������ģ�ͻ�������һ������ �Լ������ϴ�����ѵ�����Լ��á����ǣ�Ҳ���ڲ���ʱ��ˣ���ѵ����������� Ȼ�����������û���������һ��ѡ���Խ����̡� |
|
�ش��б�Ҫ���ô��ࣺܶ ������˽�밲ȫ�ԣ��������ݴ����ʹ洢���ڱ�����ɣ������ϴ��ƶˣ���Ч�������˻���ҵ������Ϣ�����ƻ�������ʹ�ã��ɸ������������ģ�ͽ���������֪ʶ��ѵ�������������绷����Ҳ��ʹ�á��ɱ����ƣ��������������ز�������˸߶���Ʒ�����ã��ʺ�Ƶ�����õij����� ��ϸ���迴���棺 һ��ʲô�� DeepSeek-R1 2025.01.20 DeepSeek-R1 ������DeepSeek R1 �� DeepSeek AI �����ĵ�һ������ģ�ͣ��ó����ӵ��������ٷ��Ա�OpenAI o1��ʽ�档�����ڶ��ָ�����������ѧ�������������ɺ��������ȡ� ���ݹٷ���ϢDeepSeek R1 ���Կ����ṩ����汾�����������棨671B ������������棨1.5B �� 70B ������������������ǿ����Ҫ���ߵ�Ӳ�����ã����������ʺ���ͨ�û���Ӳ��Ҫ��ϵ͡� ��������ܹ��빤��ѡ��2.1 Ӳ������˵�� ����������һ������ Deepseek-R1 ���汾������ 1.5B��7B��8B��14B �ȣ��ڱ��ز���ʱ������ Windows �� macOS ƽ̨��Ӳ���Ƽ����ñ���ע�⣺ �������ý����ο���ʵ����������ʹ�ó����������ij��ȣ�num_ctx �������Լ�����ģ�ͣ������������ȫ���棩�IJ��������仯��macOS ���ֱַ������ Intel оƬ�� Apple Silicon��M1/M2 ϵ�У������豸�Ľ��飻���� GPU ���֣��������Կ�Ҳ�ɲ��� CPU-only ģʽ������Ӧ�ٶȿ��ܽ�����Model VersionPlatformRecommended CPURecommended MemoryRecommended GPURecommended Storage1.5BWindowsQuad-core (�� Intel i5 �� Ryzen 5)8 ~ 16GB��ѡ�����ж��� GPU������ ��4GB VRAM������ʹ�� CPU ģʽ50 ~ 100GB SSDmacOS (Intel)Quad-core (�� Intel i5/i7)8 ~ 16GB��ѡ�������Կ���Ӧ������������ GPU Ч������50 ~ 100GB SSDmacOS (Apple Silicon)Apple M1/M2��������ͺţ�8GB ��ͣ����� 16GBApple Silicon ���� GPU�����ܾ���ר���Ż���50 ~ 100GB SSD7BWindows6 ~ 8 �� (�� Intel i7 �� Ryzen 7)16 ~ 32GB�Ƽ����� GPU������ ��6GB VRAM���� RTX 2060 �����ϣ���100GB SSDmacOS (Intel)6 ~ 8 �� (�� Intel i7)16 ~ 32GB������ö��� GPU��100GB SSDmacOS (Apple Silicon)Apple M1/M2 Pro/Max16GB ��ͣ����� 32GBApple Silicon ���� GPU���������죩��100GB SSD8BWindows6 ~ 8 �� (�� Intel i7 �� Ryzen 7)16 ~ 32GB�Ƽ����� GPU������ ��6~8GB VRAM��100GB SSDmacOS (Intel)6 ~ 8 �� (�� Intel i7)16 ~ 32GB������ö��� GPU��100GB SSDmacOS (Apple Silicon)Apple M1/M2 Pro/Max16GB ��ͣ����� 32GBApple Silicon ���� GPU��100GB SSD14BWindows8 �� (�� Intel i7/i9 �� Ryzen 9)��32GB�߶˶��� GPU������ ��8GB VRAM���� RTX 3070 �����ϣ���150GB SSDmacOS (Intel)8 �� (�� Intel i7/i9)��32GB������ö��� GPU��150GB SSDmacOS (Apple Silicon)Apple M1/M2 Max��������ͺţ���� 32GB������Ϊ 64GBApple Silicon ���� GPU�����ܳ�ɫ����150GB SSD ˵��CPU��Windows �� macOS (Intel) �豸������ö�˴�������Apple Silicon �豸�������������� CPU �� GPU ��ЧЭͬ���ڴ棺����������ģ�ͣ�1.5B��8GB �ڴ漴��Ӧ����������Ϊ��ø��������飬�Ƽ� 16GB �����ϣ����� 7B �� 8B �汾���� 16�C32GB�����ϴ�汾���� 14B������ 32GB ���ϡ�GPU������ж����Կ������� Windows/macOS��Intel���û�ѡ��߱� 4GB �����ϣ������棩�� 6~8GB ���ϣ��ϴ�汾���� GPU��Apple Silicon �豸������ϵͳ���� GPU���������û��ͣ����䱸 M1/M2 Pro/Max�����ṩ�������ܡ��洢��ģ���ļ�ͨ���ϴ��ݰ汾�Ӽ�ʮ GB ���ϰ� GB���ȣ�������Ԥ���㹻�� SSD �洢�ռ䣬ͬʱ���ǵ������ļ����������ݼ���ʱ�ļ��Ĵ洢���� ���̳̲������¹��ߺ����̣� Ollama����Դ��ģ������ƽ̨��֧��ģ�����ء������� API ���á�Deepseek-R1 ģ�ͣ������� 8B �汾Ϊ���������С��Open WebUI���ṩ���� Web �Ľ������棬�������������м��ɶԻ����ԡ�������ϸ���� �ҵı��ػ����� ������MacBook Pro (16GB RAM+) ģ�ͣ�deepseek-r1:8b 1. ��װ Ollama 1.1 ���ذ�װ���� ����Ollama ���� |
|
|
�����Ӧϵͳ���������ӣ�Windows �û�ѡ�� Windows �汾)�� ������ɺ�װ |
|
|
����̨��֤�Ƿ�ɹ���װ�������ͱ�ʾ��װ�ɹ��� |
|
|
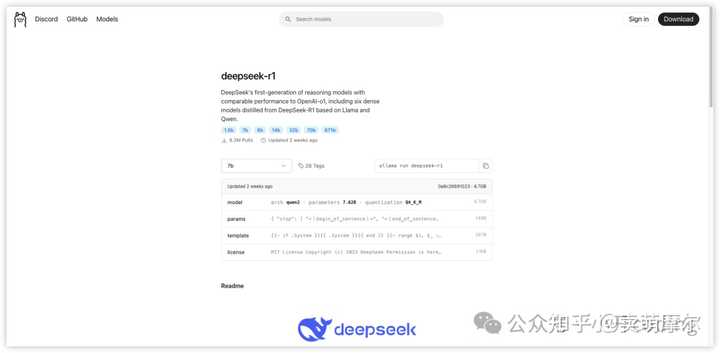
2. ���ز����� Deepseek-R1 ģ�� 2.1 ͨ�� Ollama ��ȡģ�ͣ� ��������з��� https://ollama.com/library/deepseek-r1Ollama ģ�Ϳ��е� Deepseek-R1 ҳ�档 |
|
|
�����Լ��������ã�����ѡ�������С�� 8B �汾�� �� CMD ��ִ�����������Զ����ز�����ģ�ͣ� ollama run deepseek-r1:8b ִ�к�ϵͳ���Զ�����ģ���ļ���������ɺ���뽻��ģʽ�� |

|
|
3. ���� Deepseek ģ�ͽ��� 3.1 �����н������ԣ� �� CMD ������ִ�У� ollama run deepseek-r1:8b �㽫����һ���������棬�����������⣬���磺 |

|
|
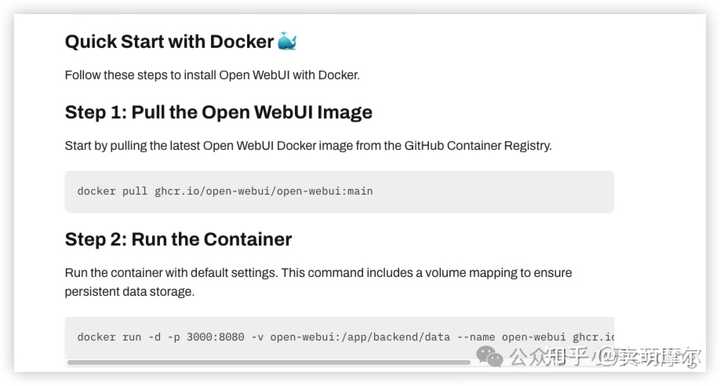
3.2 ע�⣺ ���������������Ӧ�������ɶఴ���λس������ĵȴ�������ɺͼ���ģ�͡�4. ��װ Open WebUI����ǿ�������飩 4.1 ��װ Open WebUI�� Open-WebUI�ٷ��ĵ���ַ��https://docs.openwebui.com/getting-started/ |
|
|
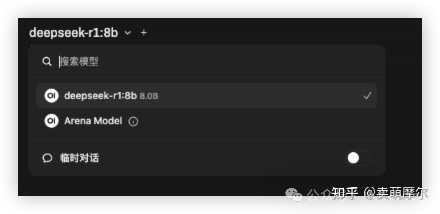
����ֱ��ʹ�� docker ��װ�� ���û�а�װ�� docker����� https://www.docker.com/Docker �ٷ�����Docker ��װ����������ʾ��ɰ�װ���ɡ� 4.2 ���� Open WebUI�� ������������� http://localhost:3000/������ WebUI ���档 �״�ʹ����Ҫע�����Ա�˺ţ�����ʾ��д��Ϣ���ע�� 4.3 �� Open WebUI ������ Deepseek ģ�ͣ� ��¼����ģ����ҳ�棬ѡ�����ӱ���ģ�͡�������дģ�����ƣ����磺Deepseek-R1-8b����������� |
|
|
�������ú�������������Ӧģ�ͣ����ɿ�ʼ��ģ�ͶԻ��� |
|
|
�ġ�����������ע���������ؼ�������̻�����������绷��������ʹ���廪�����ᄉ����� pip ���ء�Ollama ģ������ʧ�ܣ��ɶ�γ��Ի�ʹ�� VPN ����������⡣�ڴ治�����Ӧ����������ϵͳ��Դ����Ҫʱ�ر�����ռ����Դ�������� ����ɹ�עС��coding���ںţ������и��� DeepSeek ����̳̹��ο��� |
|
���ز���ı�Ҫ�Գ������������Ը� �漰ҽ�ơ����ڡ����ɵ���������ʱ�����ز���ɱ����ƶ˴�����գ�����GDPR�ȺϹ�Ҫ��ʵʱ��Ҫ���Ͽ� ��ҵ���ơ���Ƶ���ȳ����輫���ӳ٣����ز�������������ӳ�Ӱ�졣���ƻ�����ǿ ��Ƶ������ģ�ͼܹ�����������˽��֪ʶ��ʱ�����ز�������Ը��ߡ����ڳɱ��ɿ� ��ģ�͵���Ƶ�ʼ��ߣ����վ�����Σ�������Ӳ��̯������ܱ��ƶ˶��ĸ����á� �����Լ��������һ�£���Ϥ���˽�ģ�͵Ĺ������ƣ��ڱ��ز���һ����Դ��ģ�ͼ���һ���ܿ���£�Ҳ�ܹ��������˽� AI Ӧ�õĹ������ƣ����õİ����ǽ��˼�룬�ڸ���Ĺ�������ʹ�ø��Ƚ����������� Deepseek���ز���̳̣���UI����ͨ���˱ʼDZ�����GPU����CPUҲ��ʹ�ã���Һã����� ͬѧС�ţ�+v: jasper_8017 һ����������ѧϰAI��ģ��Ӧ��ʵս������������������ӭ��ҵ���+��ע�������ҵĴ�ģ��ר������ͬѧϰ�ͽ����� �������DeepSeek-R1��ƾ����ǿ������ܺͿ�Դ���ƣ��ܵ����ڶ��û��Ĺ�ע��������֧�ִ������ɡ��������ȸ����������������Ӧ�ó���������Ȼ�����������ȶȵIJ���������������ʱ�����ַ�æ�����Ͽ����ӵ������ |

|
|
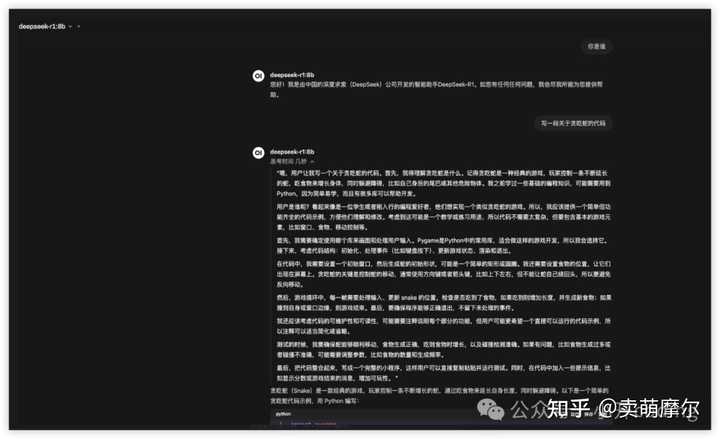
Ϊ��ȷ���ܹ��ȶ���ʹ��DeepSeek-R1�����ز���������һ�����ѵ�ѡ�����������ǽ���ϸ����DeepSeek-R1�ı��ز���̡̳� �ҵĵ������ã� ? оƬ��Apple M4 ? �ڴ棺16GB ��GPU����CPUҲ�ɲ���1. ��װ���� Ollama Ollama ��һ����Դ�Ĵ�������ģ�ͣ�LLM�����ߣ������ڱ������п�Դ������ģ�͡� 1.1 ���� Ollama ���ص�ַ��https://ollama.com/download |
|
|
1.2 ��װ Ollama �� mac Ϊ������ѹ��˫����װ���У�������Ӧ��һ�����ƶ��� Application�� |
|
|
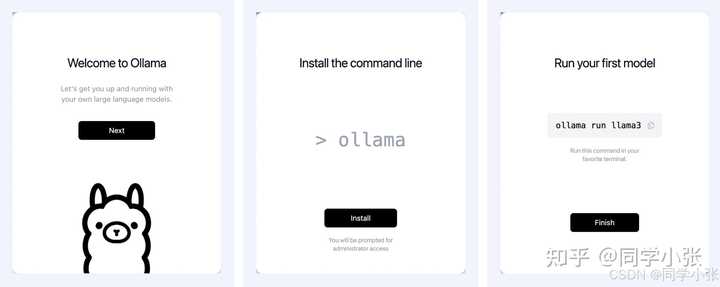
1.3 ���� Ollama �����������������ɣ����һ����������ն�Terminal�����У���һ�����л��Զ���װllama3ģ�ͣ�Ȼ���Զ����С� |
|
|
|
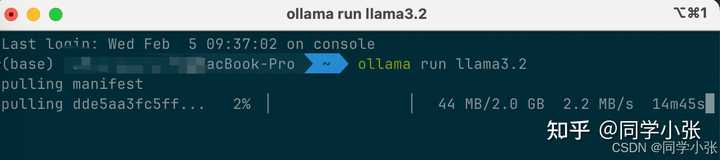
|
|
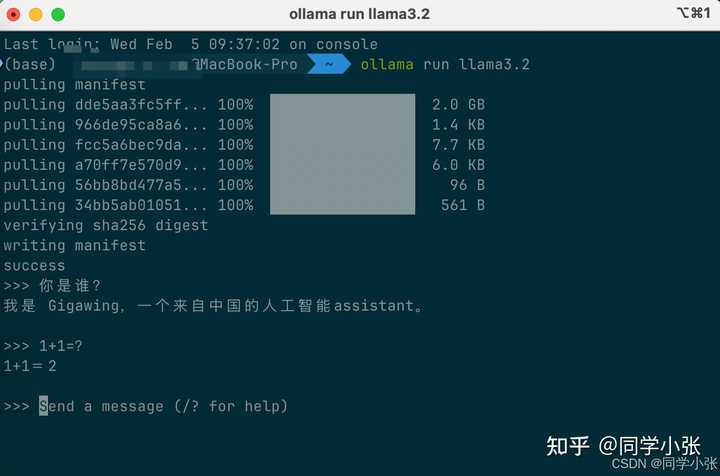
���гɹ������£� |
|
|
2. ��װdeepseekģ�ٷ����飺 ������ 8 GB �����ڴ������� 7 B �ͺţ�16 GB ������ 13 B �ͺţ�32 GB ������ 33 B �ͺš� �鿴��ַ��https://ollama.com/library/deepseek-r1 |
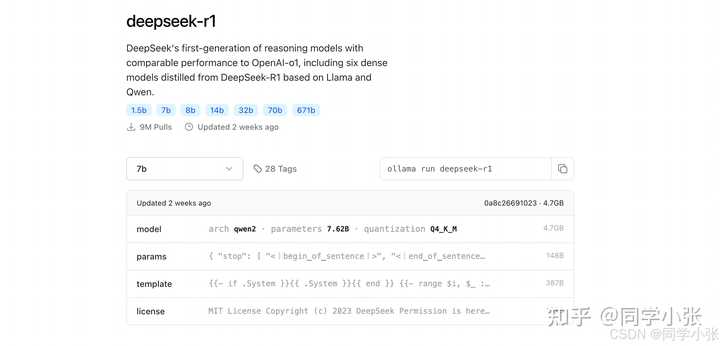
|
|
���ǰ�װ 7b �汾��ģ�ͣ����ն����У� ��װ�����гɹ��� |

|
|
3. ���� UI ���� �����ÿ�Դ�� ChatGPT-Next-Web ���ٴ 3.1 ���� NextChat ��ַ�ǣ�https://github.com/ChatGPTNextWeb/ChatGPT-Next-Web |

|
|
ѡ��Ƚ��µİ汾���ؾͺã��� Ollama һ����Ӧ�ð�װ |
|
|
|

|
|
3.2 ���� NextChat ��Ӧ�����Ĵհ�װ�� NextChat Ӧ�ã��㿪����ͼ�꿪ʼ���ã�����ͼ�����ʾ��ѡ�� deepseek-r1:7bģ�ͣ���ַΪ�ո���ķ��� http://127.0.0.1:11434/ |
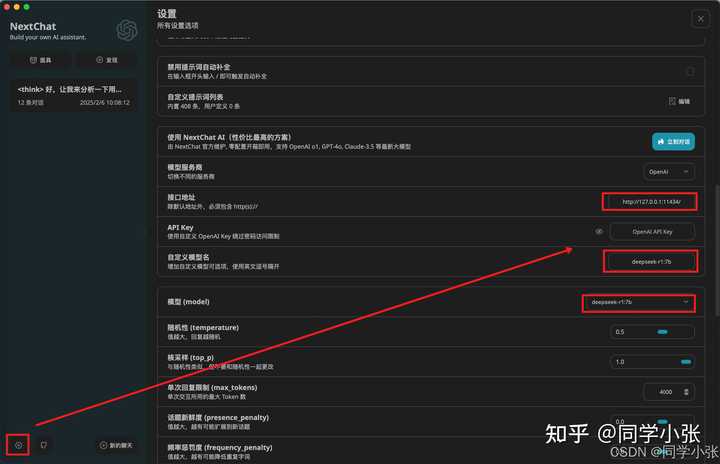
|
|
���к�ʹ�óɹ��� |
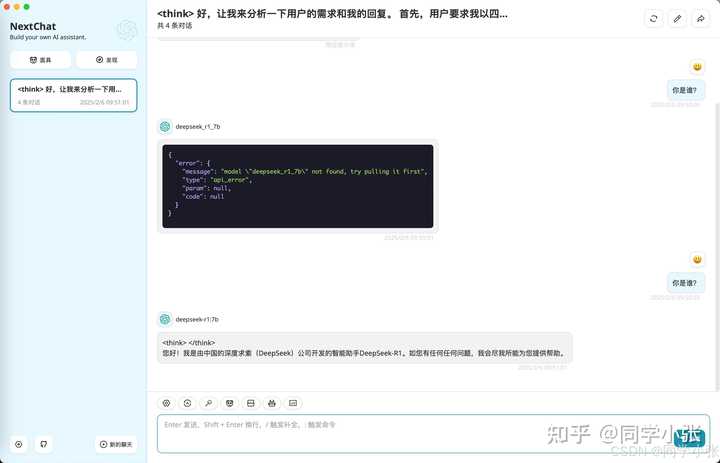
|
|
4. �������������� ��1��Error: Post "http://127.0.0.1:11434/api: dial tcp 127.0.0.1:11434: connect: connection refused ���Ollama�Ƿ��������У� ? Ollama û���û����棬�ں�̨���С� ������������� ��http://localhost:11434 �� http������ʾ ��Ollama is running���� |
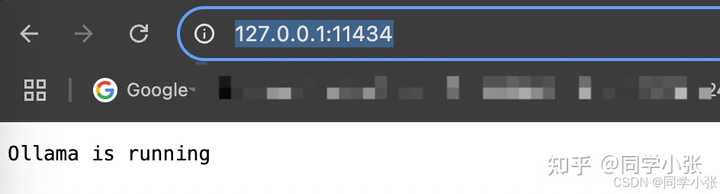
|
|
? ���Ollama�������У������������ģ�ʹ�������ִ��һ��Ollama run����������ܾͺ��ˣ�������ô����ģ� ��2��NextChat �����е�ģ�����ƣ�һ��Ҫ���㰲װ��ģ��������ȫһ�£�ollama run deepseek-r1:7b ��װ��ģ�������� deepseek-r1:7b�����ܴ�����������������汨���� |
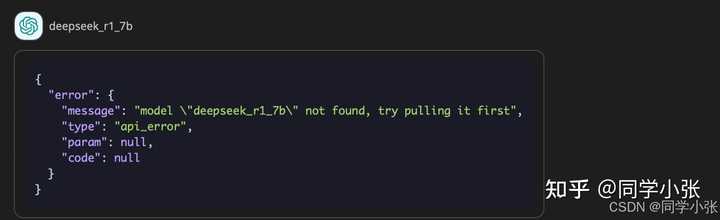
|
|
������ñ��Ķ����а������鷳�����ע�� ~~~? ��Һã����� ͬѧС�ţ�����ѧϰC++���ס�OpenGL��WebGL֪ʶ��AI��ģ��Ӧ��ʵս���� ? ��ӭ ���� + ��ע ������ѧϰ�������ɻ������ ? +v: jasper_8017 һ���� ��һ����� �� ? �Ź��ں��ѡ�ͬѧС�š� |
|
ʷ�������� Ollama + Open-WebUI DeepSeek ���ػ�������¯�� 2025��1�£�DeepSeek ��ʽ���� DeepSeek-R1 ������ģ�͡�DeepSeek-R1 �ɱ��۸����������Խ���� AI ��ҵ�����˹㷺��ע�� DeepSeek �ṩ�˶���ʹ�÷�ʽ�����㲻ͬ�û�������ͳ��������ز��������ݰ�ȫ�����ܡ����ƻ����ɱ������߿����Ժͼ��������Է�������������ơ� ������ϸ���� ���� Ollama+Docker+OpenWebUI �ı��ػ��������̣���ͨ��ʵ��������ʾ���÷����ܿ������������Ƚ���deepseek�����ģ�ͣ�������Ҫ���ܹ�����ÿСʱ���ܵ���һ�ε�ʹ�ࡣ ������Ӳ��Ҫ��ģ������CPU�����ڴ�����Ӳ�������Կ�����DeepSeek-R1-7B8 �����ϣ��Ƽ��ִ���� CPU��16GB+8GB+�Ƽ� 8GB+ �Դ棨�� RTX 3070/4060��DeepSeek-R1-14B12 ������32GB+15GB+16GB+ �Դ棨�� RTX 4090 �� A5000��DeepSeek-R1-32B16 �����ϣ��� AMD Ryzen 9 �� Intel i9��64GB+30GB+24GB+ �Դ棨�� A100 40GB ��˫�� RTX 3090��DeepSeek-R1-70B32 �����ϣ��������� CPU��128GB+70GB+����У��� 2x A100 80GB �� 4x RTX 4090��DeepSeek-R1-671B64 �����ϣ���������Ⱥ��512GB+300GB+��ڵ�ֲ�ʽѵ������ 8x A100/H100���������� ����ϵͳ��Windows��Linux���Ƽ� Ubuntu ϵͳ�����ر����ߣ�Docker��NVIDIA��������ʹ�� GPU���� Step-by-Step ����ָ�ϵ�һ������װ Docker Docker �����Dz���ĺ��Ĺ��ߣ����ܰ������ǿ��ٴ���л����� Ubuntu ��װ Docker ���նˣ������������sudo apt update && sudo apt install http://docker.io -y ���� Docker ����sudo systemctl start docker && sudo systemctl enable docker �ڶ�������װ ollama llama��װ�ű���ַ �ڶ�������ȡ DeepSeek ���� �����Ѿ�Ϊ���������Ż��õľ���ֱ����ȡ���ɡ� |
|
|
����ollama֧�ֵ�deepseek-r1��������ģ������ DeepSeek-R1ϵ��ģ�� |

|
|
��Ѫ�汾��R1/R1-Zero������Ϊ671B�����ز���뾫��ҲҪ400G�Դ棬��ʹ����͵�DeepSeek-R1-UD-IQ1_M��671B��1.73-bit ��̬������158 GB��HuggingFace���Դ�ҲҪ158G�����˺���ͨ��ҵ����Ѫ����ԴҪ������ȴ�����������ѡ��������ģ��70B,32B,14B,1.5B�� ��������ollama���� DeepSeek ���� ���������������������� ������ɺ� ���IJ���ollama����ģ�Ͳ��� vim /etc/systemd/system/ollama.service ��[Service]����������Environment ����ollama ��֤ollama�������гɹ� ���������http://����ip:11434 |
|
|
���岽������ Open-WebUI ��װ ������ѡ���different server |
|
������ϲ������������ʣ� ���ɽ��� Open-WebUI ���棬��ʼ��� AI ģ��֮�ã� |
|
|
|
|
|
������Ŀ���� |

|
|
���ϲ�����Ŀ |

|
|
˼������ ˼���˽ӽ�һ���ӣ���������ȷ�𰸡� |
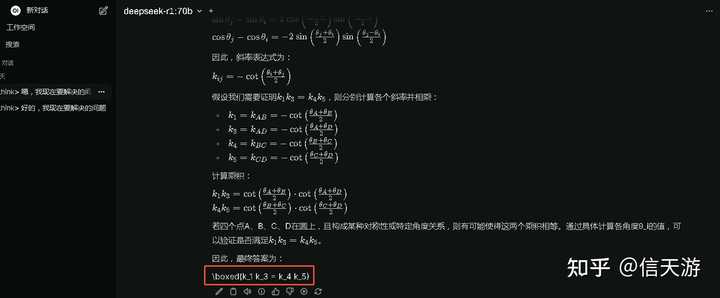
|
|
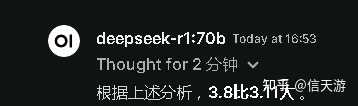
ģ��˼�����ս�� �ڶ�����ѧ���⣬gpt4����ꪵģ�����֤��deepseek-r1-70b�ܷ�ʤ�Ρ� |
|
|
����˼������ �ܽ� ͨ����ݼIJ��������Ѿ������ڱ���������ͨ DeepSeek-R1-Distill-Llama-70B �� DeepSeek-R1-Distill-Qwen-32B ģ���ˣ������Ǽ������ֻ��Ǿ���ḻ�Ŀ����ߣ����ܿ������֡� Ϊʲô���ȴ��������ж��ɣ��� AI ��ǿ�������������������⣬������Ĵ���֮�ã� |
|
ǰ�� �������Ĺ���AI��ģ��Deepseek��ϸ��Ҷ���İ���������������ֻ��ϰ�װAPP���߹����������飬������ʵ��ȫ�������Լ���Windows�����ϱ��ؽ��в��𣬲����cpolar��������������ʵ��Զ�̽����������������ݵ����顣 ֮ǰ�ͺʹ�ҷ������������� AI ģ�;��кܶ����ƣ�������˽��ȫ������������ݶ����������Լ��Ļ����ϣ������ڹ���������Ϣ�ķ��ա�������Ӧ���ٷ������������������ӳٷdz��ߣ���ɿ��٣����ز����ģ�Ϳ��Ա������������ Ҫʵ�ֱ��ز���DeepSeek R1��ģ����ʵҲ���ѣ�ֻ���ڵ����а�װ�ܹ����и���AIģ�͵Ŀ�Դ����Ollama �Ϳ����ˣ���������о����ն��к�AI������̫���ۣ�����Ҳ���ٰ�װһ��ͼ�λ��Ľ��棬�������chatgpt��������ҳ�кʹ�ģ�������ˣ��������������ʾһ�¡� |
|
|
1. ��װOllama ���ȷ���Ollama�Ĺ�����Download Ollama on Windows ����������IJ���ϵͳ�Ŀͻ��ˣ�������ʹ�õ���Windows11ϵͳ��������ؼ��ɣ� |
|
|
���غ�֮��˫���� |
|
|
���Install��װ�� PS:Ĭ���ǰ�װ��C�̣���ҪԤ��2G���ϵĴ洢�ռ䡣 |
|
|
��װ��֮�����ǰ�סWin+R���������п�������cmd��Windowsϵͳ�Դ����ն˽��棺 |
|
|
Ȼ������ollama�س�������������Ϣ��Ϊ��װ�ɹ��� |
|
|
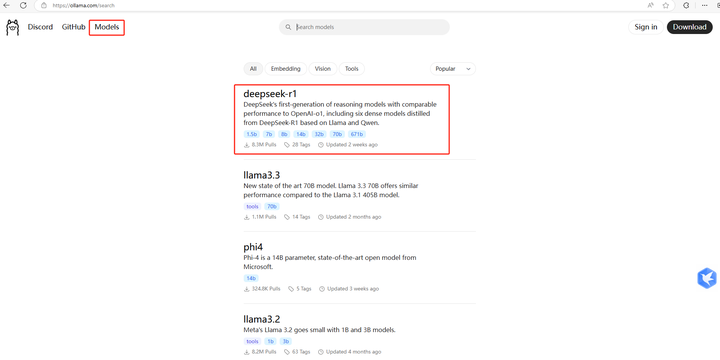
2. ��װDeepSeek-r1ģ�� �ص� Ollma ��������� Model�� ҳ����ת����Կ�����һ������DeepSeek-r1ģ�ͣ� |
|
|
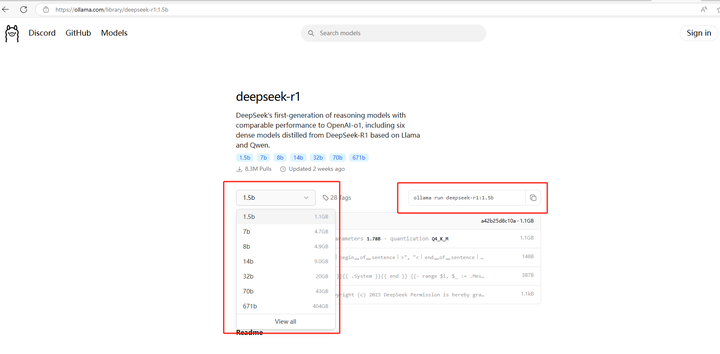
Ȼ��������ڴ�ҳ�������ǿ���ѡ����Ҫ���صĸ���������ģ�ͣ��Ҳ����Ƕ�Ӧ��ģ��������� |
|
|
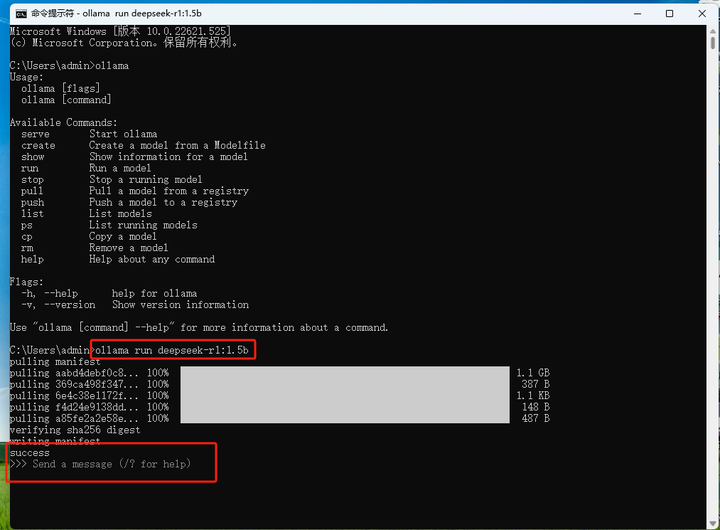
����������1.5b��������deepseekģ�ͽ�����ʾ����ҿ��Ը����Լ�ϲ��ѡ������������ģ�ͣ� �������������ǣ� �ڸղŴ�cmd�ն��У�ִ��������� PS��ͬ����ҪԤ��2G���ϴ洢�ռ� �Ե�һ������ܿ���deepseekģ���Ѿ����ص��˱��ص��ԣ�����ʾ���ǿ��Է�����Ϣ���н����ˣ� |
|
|
�������⣬���Ͼ����յ��ش��ٶ�ͦ��ģ� |
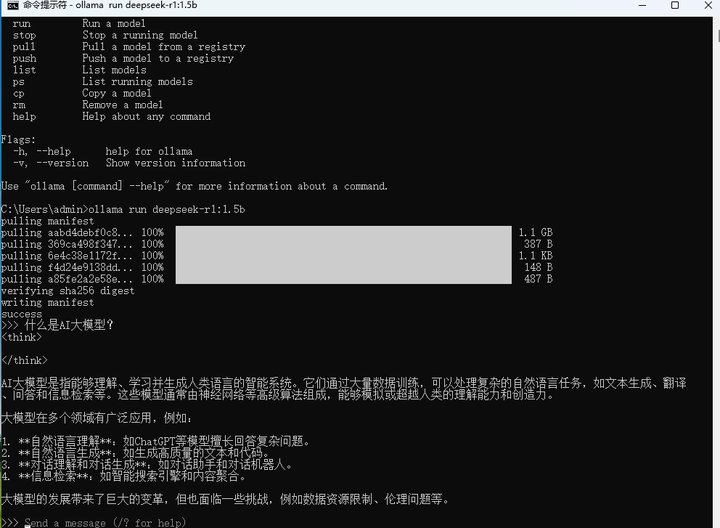
|
|
3. ��װͼ�λ����� ���������Ѿ��ܹ��ڱ���Windows����������ʹ��deepseek-r1ģ����AI���������ˣ�����ͷ˵�����������������ܲ��Ǻ����ۣ��ڸ��ƻش�ʱҲ��̫���㣬���ǿ���ͨ����װһ��GUI���������������⡣ ���̳���Open WebUI�����ĿΪ����ʹ��Docker���а�װ������ǰ�����־ͽ� Formerly Ollama WebUI����������Ϊһ��ʼ����ר������Ollama��WebUI�����Ľ���Ҳ���ù���chatgpt��С�����˵������һЩ����Ȼ�����Ҳ����ѡ��������WebUI�� 3.1 Windowsϵͳ��װDocker ������֮ǰδ��װ��Docker�����Բο��·��̳̽��а�װ�� ���ȣ�ѡ��Ҫ��װ��Docker�汾���а�װ�� ���ص�ַ�� �����û��������ص�ַ�� https://github.com/tech-shrimp/docker_installer/releases/download/latest/docker_desktop_installer_windows_x86_64.exe������Windows��Docker���� �C x86_64�� https://desktop.docker.com/win/main/amd64/Docker%20Desktop%20Installer.exe?utm_source=docker&utm_medium=webreferral&utm_campaign=docs-driven-download-win-amd64&gl=1rjke9fgcl_auMjAxNTA4ODQwMy4xNzI1ODYzMTMxgaMTc3ODM4NTkyMy4xNzI0MDM2OTcwga_XJWPQMJYHQ*MTczMDI2OTA1NC42LjEuMTczMDI2OTQwNC4zOC4wLjA.������Windows��Docker Desktop Arm(����) https://desktop.docker.com/win/main/arm64/Docker%20Desktop%20Installer.exe?utm_source=docker&utm_medium=webreferral&utm_campaign=docs-driven-download-win-arm64&gl=118eu5gsgcl_auMjAxNTA4ODQwMy4xNzI1ODYzMTMxgaMTc3ODM4NTkyMy4xNzI0MDM2OTcwga_XJWPQMJYHQ*MTczMDI2OTA1NC42LjEuMTczMDI2OTQwNi4zNi4wLj��ѡ: ������Լ�ָ����װĿ¼������ʹ�������еķ�ʽ ���� �Cinstallation-dir=D:\Docker����ָ����װλ�� start /w "" "Docker Desktop Installer.exe" install --installation-dir=D:\Docker Ȼ�����������������ܣ����á�������Linux��Windows��ϵͳ�� ���������ƽ̨�� |
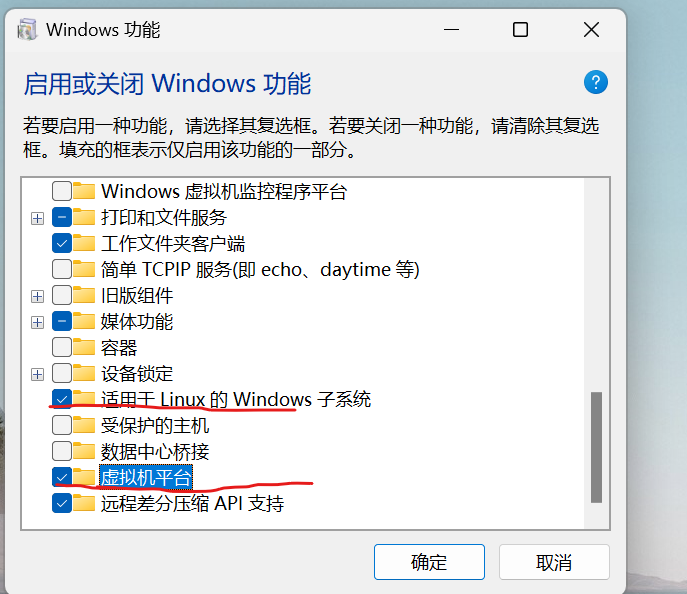
|
|
Ȼ��ʹ�ù���ԱȨ��������ʾ������װwsl2�� �ȴ�wsl��װ�ɹ��� |

|
|
Ȼ���ٴ��������ԣ��������������Docker Desktopͼ�꣺ѡ���Ȳ�ע��ֱ�ӵ�¼���ɡ� |
|
|
��Docker Desktop�����½���ʾ����ɫ��running�ʹ������dzɹ��ˣ� |
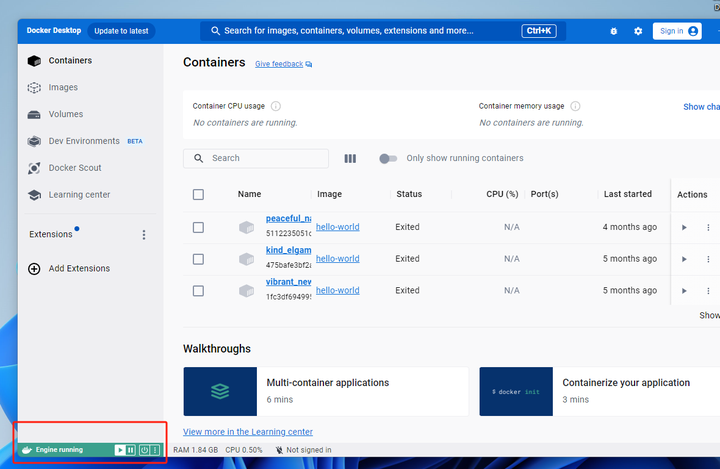
|
|
PS��Windows���þ���վ������ѧ������������ֶ����þ���վ�� Setting->Docker Engine->�����ϻ�Դ����һ�Σ�����ͼ�� |

|
|
���������ʹ��Docker. Ҳ���Դ��նˣ�����powershell��Ȼ������docker���س�: |
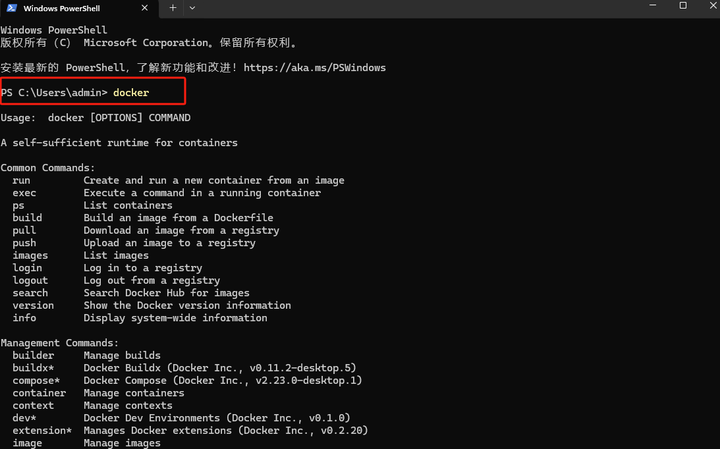
|
|
���Կ����������ɹ����У�ͬ��˵��docker��װ�ɹ��� 3.2 Docker����Open WebUI Ȼ�����Open WebUI��githubҳ�� https://github.com/open-webui/open-webui ���Կ�����������Ollama��Open WebUI��ͬһ̨��������ʹ��������ʾ����һ��������cmd�ն��оͿ����ڱ��ؿ��ٽ��в��� |
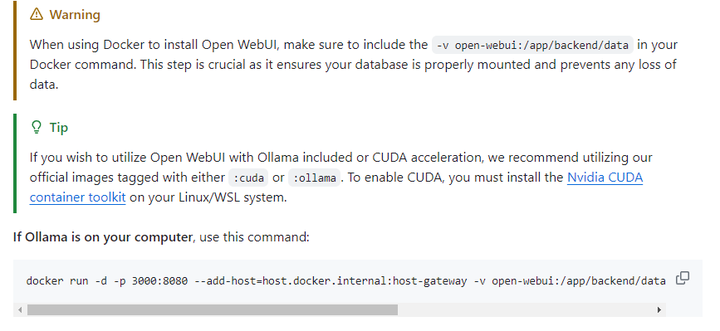
|
���ϱ���docker�в���Open WebUI������ƺ�ճ�����ն��У��س��� |
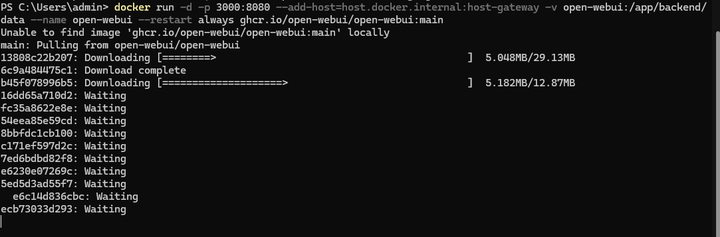
|
|
Ȼ��ȴ���װ��ϼ��ɣ�����ͼ��ʾ�� |
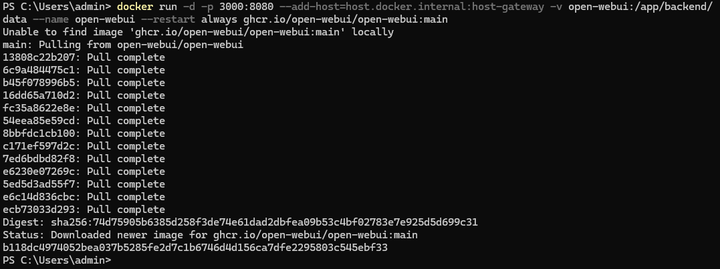
|
|
��װ��ɺ���Docker Desktop�п��Կ���Open WebUI��web�����ַΪ��https://localhost:3000 |

|
|
��������������¼���棺 |
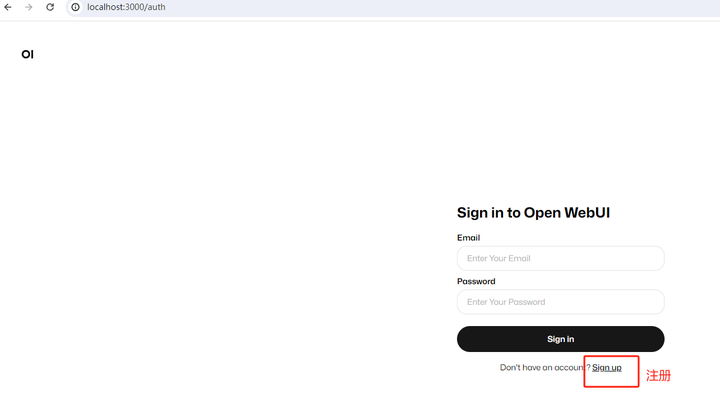
|
|
���sign upע�ᣬ�˺ţ����䣬����Ǻã��´ε�¼ʱ��Ҫ�õ�����������¼�� |
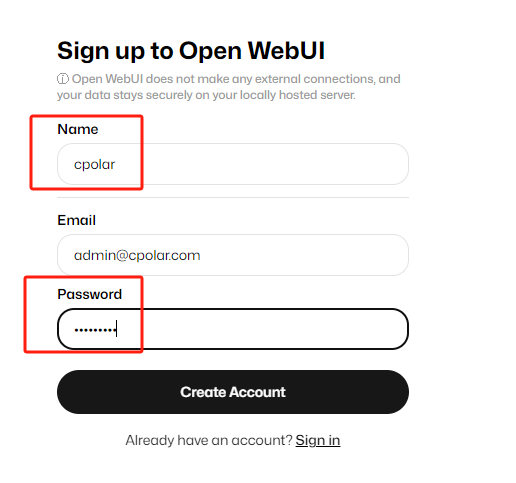
|
|
Ȼ����create account�����˺ż��ɣ�Ȼ��������������ʹ������chatgpt�����Open WebUI�ˣ� |
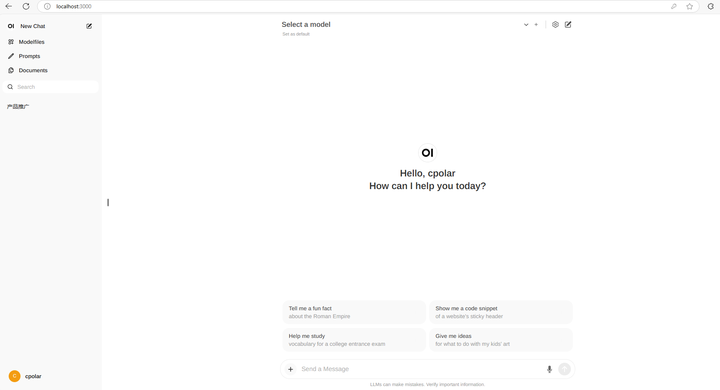
|
|
3.3 ����Deepseekģ�� ������Ͻǵ����ã������ĵ�ǰ���������Ϊ�������ģ�Ȼ�������漴�ɡ� |
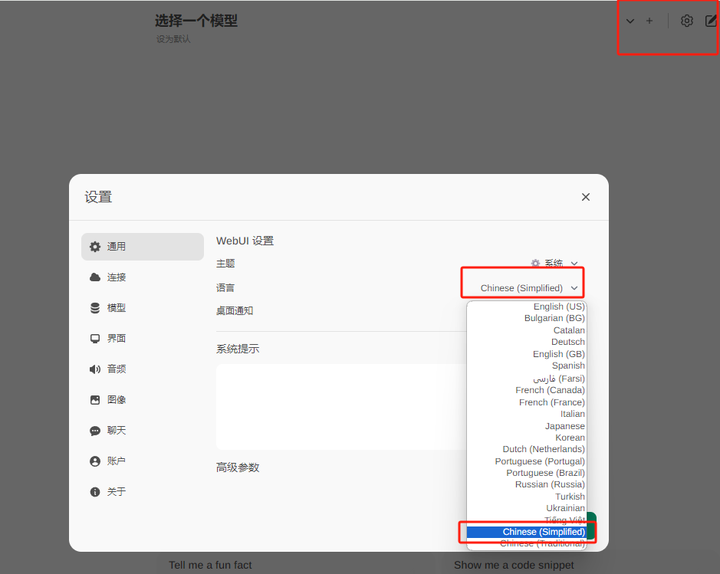
|
|
|
|
|
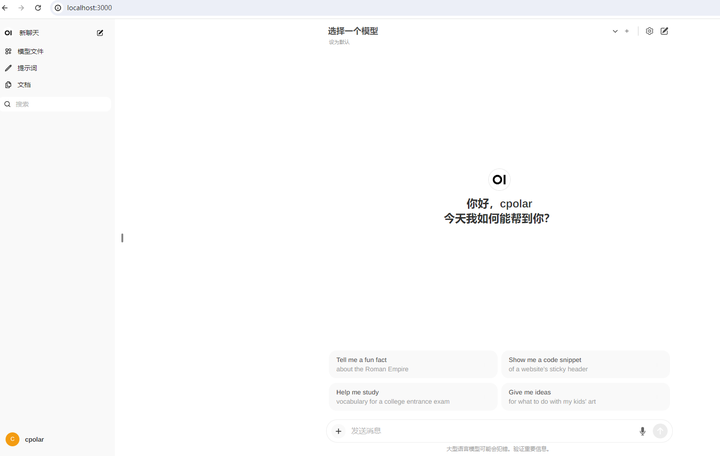
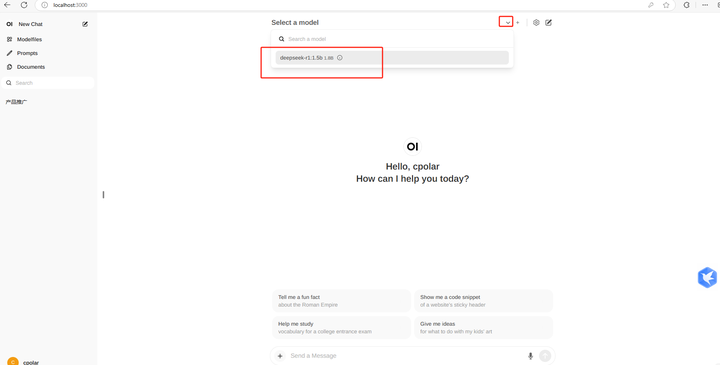
����Ϸ�ѡ��һ��ģ���ԱߵļӺ�+�������Ӵ�ģ�ͣ����������ť����ѡ��ǰʹ����һ���Ѱ�װ��ģ�ͣ�����ѡ��ղŰ�װ��DeepSeek-r1:1.5b���������Ϳ������ĸ�DeepSeek-r1��ģ������ҳ�������ˣ� |
|
|
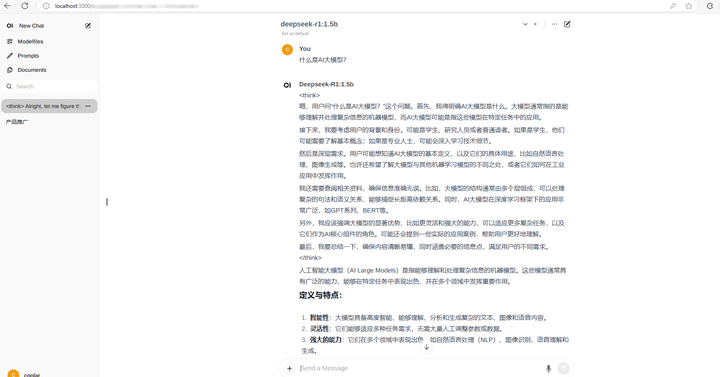
|
|
|
������ͳɹ�������DeepSeek��ʹ��Open WebUI����ҳ����AI������֮������Ը����Լ�������ѵ�� DeepSeek���� DeepSeek ѵ�����Լ�ר��AI���֡� 4. ��װ���������� �������ʵ�ֲ���ͬһ���绷���£�Ҳ����ʱ�������ʹ��Open WebUI�뱾�ز����DeepSeek-r1��ģ������ҳ�����죬�Ǿ���Ҫ����cpolar������������ʵ�ֹ��������ˣ�����������һ����ΰ�װcpolar������������ͬ���dz��� ���Ƚ���cpolar������ cpolar������ַ: https://www.cpolar.com ������ʹ��ע��һ���˺ţ����������°汾��cpolar�� |
|
|
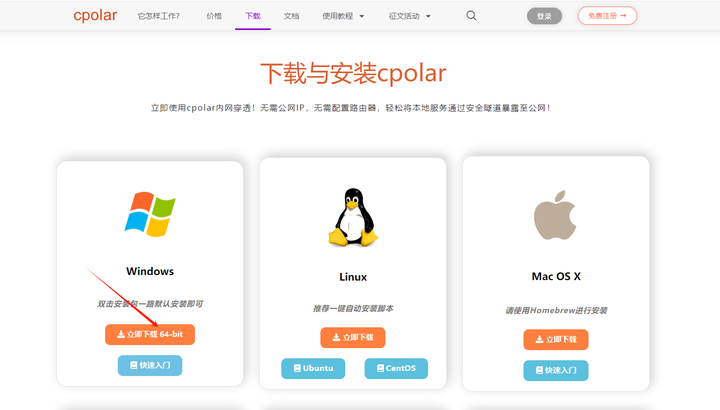
��¼�ɹ��������cpolar�����ز���װ��һ·Ĭ�ϰ�װ���ɣ����̳�ѡ������Windows�汾�� |
|
|
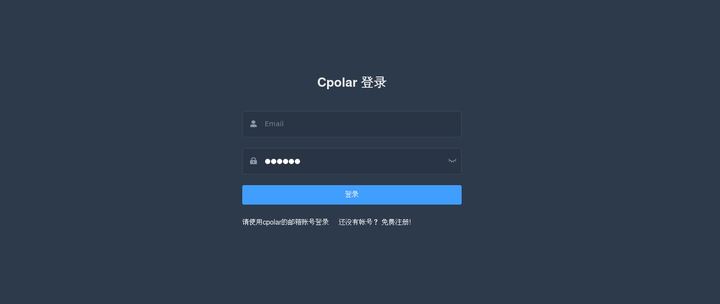
cpolar��װ�ɹ�����������Ϸ���http://localhost:9200��ʹ��cpolar�˺ŵ�¼,��¼�ɿ������ý���,��������WebUI�����������ü��ɡ� |
|
|
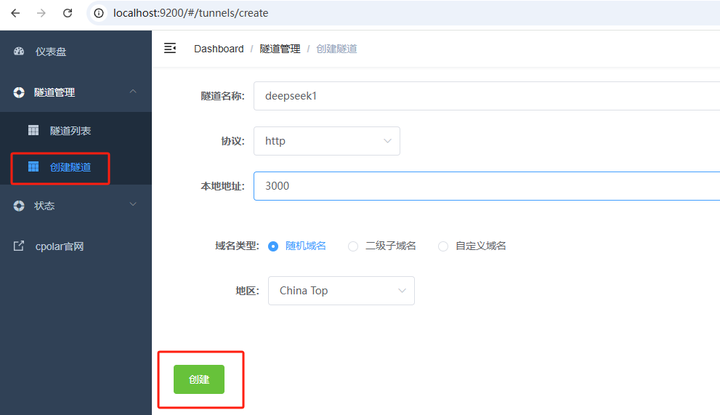
����������һ�� Open WebUI �Ĺ�����ַ�� ��¼�������DZ��̵����������������������� �������ƣ�deepseek1�����Զ���������ע�ⲻҪ�����е����������ظ���Э�飺ѡ�� http���ص�ַ��3000 (���ط��ʵĵ�ַ)�������ͣ�ѡ���������������ѡ��China Top |
|
|
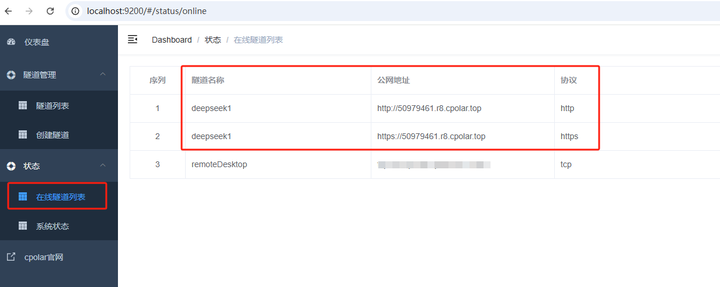
���������ɹ��������״̬�������������б�,�鿴�����ɵĹ������ʵ�ַ�������ַ��ʷ�ʽ,һ����http ��https�� |
|
|
ʹ�����������һ��������ַ,���ֻ��������豸����������е�¼����,���ɳɹ����� Open WebUI ����,����һ��������ַ�ҿ���Զ�̷��ʾʹ�������,ʹ����cpolar�Ĺ�������,�����Լ������Ʒ�����,���ɵ���ʱ���߷���Open WebUI������ҳ��ʹ�ñ��ز����Deepseek��ģ���ˣ� |
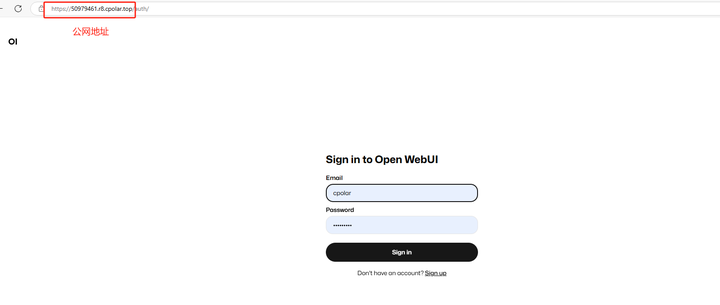
|
|
|
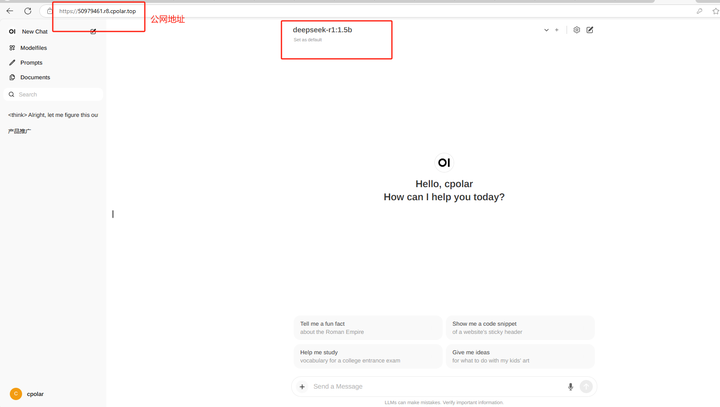
|
|
С�� Ϊ�˷�����ʾ���������ϱߵIJ���������ʹ��cpolar���ɵ�HTTP������ַ�������乫����ַ��������ɵġ����������ַ���������ڽ����ٶȿ죬��������ʹ�á�Ȼ��������ȱ������ַ��������ɣ������ַ��24Сʱ�ڻᷢ������仯�����ʺ�����ʱʹ�á� ����г���Զ�̷���Open WebUIʹ��DeepSeek��������ط�����ʹ���������ز���ķ���������ֲ���ÿ���������ù�����ַ�������ù�����ַ�ÿ��ֺüDz��������������Ĵ����������Ƽ����ѡ��ʹ�ù̶��Ķ�����������ʽ��ΪOpen WebUI����һ��������ַ�� 5. ���ù̶�������ַ ��������ʾ���Ϊ�����ù̶���HTTP������ַ���õ�ַ����仯��������������˳��ڲ鿴�㲿�����Ŀ��������ÿ���ظ��ķ�������ַ�� ���ù̶�http�˿ڵ�ַ��Ҫ��cpolar������רҵ���ײͻ����ϡ� ��¼cpolar�������������Ԥ����ѡ��������������������һ���������������ƣ��������,�����ɹ����Ʊ����Ķ������������ƣ� |
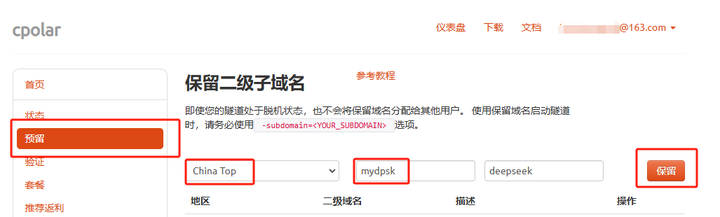
|
|
�����ɹ����Ʊ����ɹ��Ķ��������������ƣ�mydpsk�����Ҳ���������Լ�ϲ�������ơ� |
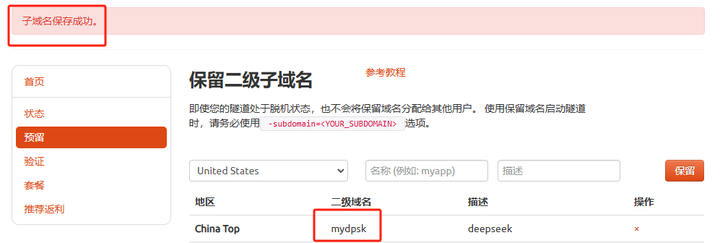
|
|
����Cpolar web UI�������棬�������DZ��̵������������������б����ҵ���Ҫ���õ�������deepseek1������Ҳ�ı༭�� |
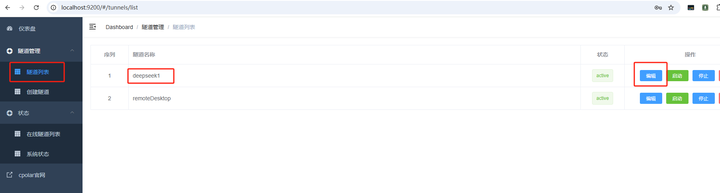
|
|
��������Ϣ���������ɹ��Ķ������������õ������� �������ͣ�ѡ�����������Sub Domain����д�����ɹ��Ķ�����������mydpsk �������(ע��,���һ�θ��¼���,����Ҫ�ظ��ύ) |
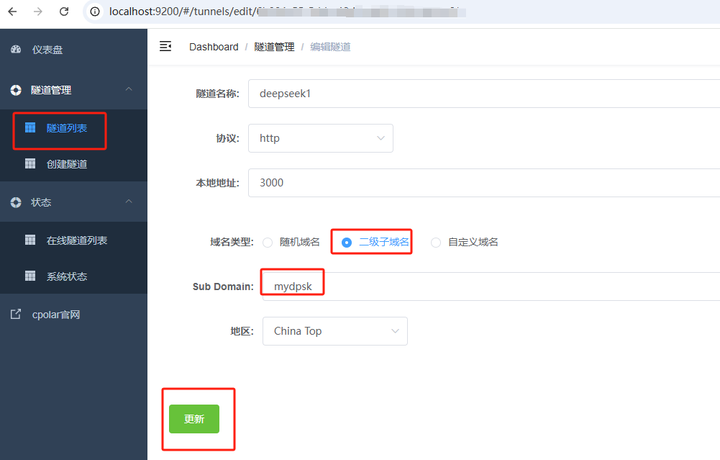
|
|
������ɺ�,�����������б�,��ʱ���Կ���������ַ�Ѿ������仯,��ַ����Ҳ����˹̶��Ķ������������Ƶ������� |
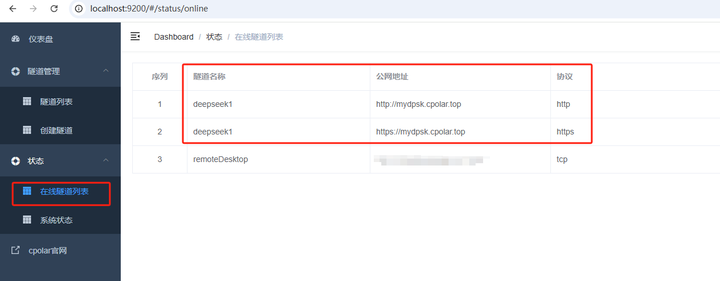
|
|
���,����ʹ�ù̶��Ĺ���https��ַ����,���Կ������ʳɹ�,����һ���̶������ò���Ĺ�����ַ�����ú��ˣ�������ʱ����ڹ�������������߷��ʱ��ز����Open WebUI��ʹ��DeepSeekģ���ˣ� |
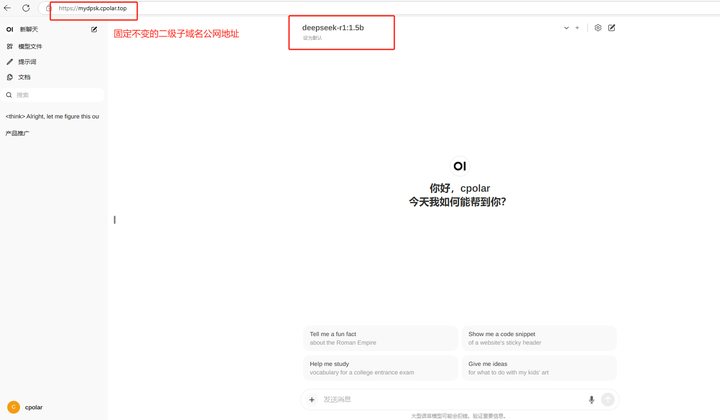
|
|
���Ͼ��������Windowsϵͳ���ذ�װOllama��ģ���߲�ʹ��docker����Open WebUI�����cpolar����������ʵ�ֹ������ʱ��ز����deepseek-r1��ģ�ͣ������ù̶�����Ķ���������������ַʵ��Զ�̷��ʵ�ȫ�����̣���л���Ĺۿ������κ����ӭ���Խ����� |
|
���˽�һ��ģ�͵İ汾��Ȼ���ٸ����Լ���ʵ��������ж��Ƿ���Ҫ�����ڱ��ء���DeepSeek-R1Ϊ���� DeepSeek-R1ģ�������ࣺ1. ԭ��DeepSeek-R1 ģ�� Model#Total Params#Activated ParamsContext LengthDownloadDeepSeek-R1-Zero671B37B128KHuggingFaceDeepSeek-R1671B37B128KHuggingFace DeepSeek-R1-Zero & DeepSeek-R1 �� DeepSeek-V3-Base������ѵ���� �ٷ���ģ�ͺ��ְ�ģ�Ͷ������ |
|
|
|
|
|
|
|
|
�㱾���ܲ����DeepSeek-R1�϶���������汾�� 2 DeepSeek-R1-Distill ģ�� DeepSeek-R1-Distill ����DeepSeek-R1���������Сģ�͡� ModelBase ModelDownloadDeepSeek-R1-Distill-Qwen-1.5BQwen2.5-Math-1.5BHuggingFaceDeepSeek-R1-Distill-Qwen-7BQwen2.5-Math-7BHuggingFaceDeepSeek-R1-Distill-Llama-8BLlama-3.1-8BHuggingFaceDeepSeek-R1-Distill-Qwen-14BQwen2.5-14BHuggingFaceDeepSeek-R1-Distill-Qwen-32BQwen2.5-32BHuggingFaceDeepSeek-R1-Distill-Llama-70BLlama-3.3-70B-InstructHuggingFace DeepSeek-R1-Distillģ���ǻ��ڿ�Դģ�ͽ������ģ�ʹ������DeepSeek-R1���ɵ������������ǵ����úͷִ��������������ġ����ǵijɼ��������ģ� |
|
|
����������Դ�IJ�����Դ�ollama��ģ�Ϳ���������Щ����������4Bit�ģ��� |
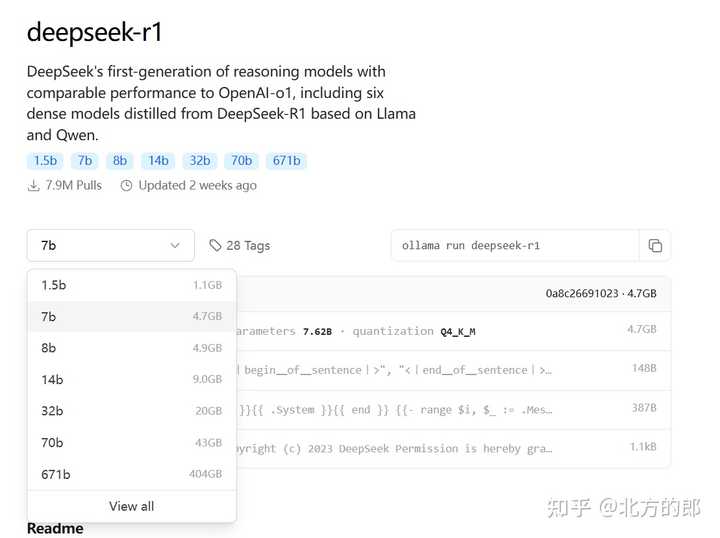
|
|
�Ƿ��б�Ҫ���� ��ʵҪ��Ҫ��DeepSeek�����أ���ȫ���������ͳ�����������Ǹ���������˽�ر����е��ˣ������ڽ�����ҵ�����ͻ����ݣ�������ҽ����ҵ�����������DZ��ز�����Եú��б�Ҫ�ˡ��Ͼ������������Լ�����ܱȴ����ƶ����˷��ģ��ɣ� ͬʱ�����ز�������������������ص���ģ�ͣ���Ӧ�Լ������������ң���һЩ��Ҫ�������ij�������������ҵ��������أ����ز����ֱ���Ǹ��衣 �����������ֻ����������棬����û���ر�ߵ���˽Ҫ��ֱ���ùٷ�������������߷�����ܸ�ʡ�¡��Ͼ������ز�������Ҫһ���ļ����ż��������Ƕ�Ӳ��������Ҫ������Կ��ܻ�����ץ�� ����ķ��� DeepSeek��V3��R1�����Ѿ����������Ĵ�ģ�ͼ���/����ƽ̨����vLLM��Ollama��sgLang�ȣ�֧���ˡ�ͨ����Щƽ̨������Լ���ͷ����Ч�ʸߣ��������Ż����㡣 ���岽����Բο��ҵ����£��������ɣ�DeepSeek-R1 ���ز���ָ�ϣ�Ollama ��������ʵ�֣�֧��2G�Կ� �����ꡪ�� @�������� �� רעģ������� ϲ�������ѣ���ӭ��ͬ����ע���������� ^O^ |
|
|
| [�ղر���] �����ر��ġ� |
| ���� �������� |
| ������ۻ�Ϊ���ɵ��ԣ� |
| ��ο���С��Sky Nomad С����̣� |
| С��Ϊ�β����ţ� |
| codex��windows��������ֻ����wsl�в��ǡ� |
| Ϊʲô����û�е��գ� |
| ��ο���ij��touch����ƽ������������ |
| �������������� |
| ��23��������������Dz���߯���ˣ� |
| �Ż�Ӧռ����ռ�8������㣬���ϰ�װ��ʮ |
| С�������ĸ����ɹ��� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
|
��������:
��ӰƱ��
����Ȧ
����
����
����
�����
ӡ��
�ɼ�
��س
����
��ˮ
��Ǯ�ҽ���ר��
����
˫ɫ��
����ĸ��
����
ƹ����
�й�Ů��
����
nba
�г�
�ܲ�
����
���
��ɫ
�Ϻ��п�
80��
����: ���� �����ֶ� ������ķ�ȴ� �ʼ������� ����ͼ˹ ���� ����� ���� �ﰺ ����ʥ�ն��� ���� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ֪ʶ�� |