| |
|
|
| ֪ʶ�� -> ���� -> ��ΰ�deepseek-R1��/����Ϊij�����һ��ר�ң� -> �����Ķ� |
|
|
[����]��ΰ�deepseek-R1��/����Ϊij�����һ��ר�ң� |
| [�ղر���] �����ر��ġ� |
|
һ����Ҫ��ģ�ͱ���/������㹻С�����Բ����ڸ��˹���վ�У����߲�̫��ķ��������� ��һ����Ҫ��ģ������/ѧϰ/����ij��������֪ʶ�����ס����ݣ���Ϊ�� |
|
�������DeepSeek��Դģ�ʹ���ҽ������ר��AI���֣�����������ȫ���̽��� ҽ���˹�������ӭ������ʽ����������ʵ��Ӧ���У�ͨ�ô�ģ����������ҽѧ֪ʶ��������������Ͻ������⡣���Ľ��ְ��ִ���ʵ��ҽ�ƴ�ֱ�����ģ�͵Ķ��ƻ�ѵ������DeepSeek-R1Ϊ����������רҵ�ɿ���ҽ��AI���֡� һ������ģ��ѡ�ͣ�ҽ�������Ļƽ�1.1 Ϊʲôѡ��DeepSeek-R1-Distill-Llama-8B�� ��������������˾�з�������汾ģ�ͣ���ҽ�Ƴ�����չ�ֳ�����������ƣ� ֪ʶ�ܶ��Ż���ͨ��֪ʶ���������ڱ���ԭ��16Bģ��97%���ܵ�ͬʱ��������ѹ����8B��������������ǿ����MedQA-USMLE��ҽѧ�������У����ȷ������12.7%ѵ���ɱ����ƣ������ԭ��ģ�ͣ��������Դ潵��40%������A100�������ѵ��1.2 ������ָ�� ����ҽ�����ݹ��̣�����רҵ֪ʶ��2.1 ҽѧCoT���ݼ����� ���Ǵ�Hugging Face���ص�Medical Chain-of-Thought���ݼ������� 15������ר�ұ�ע�����˼ά�������ڿơ���ơ������12��ר������ÿ�����ݰ������������ߡ�������ϡ������ԡ�ȷ�����ݵĽṹ����Ϣ2.2 ����Ԥ�����ؼ����� ������Ч��ʵ����Unsloth��ܺڿƼ�3.1 ���ܶԱ�ʵ�� ������4*A100�����¶ԱȲ�ͬ�������� ����Դ�ռ��ѵ���ٶ�LoRAЧ��ԭ��PyTorch72GB1x78.2%DeepSpeed65GB1.3x79.1%Unsloth42GB2.5x82.3%3.2 �������ò��� �ġ�ҽ�Ƴ��������Ż�4.1 �Ʒ���ܹ���� ����Google Cloud Run+Cloud Load Balancing�ĵ��Լܹ��� 4.2 �������ټ��� �塢Ч����������� ���ǹ���������������ϵ�� ҽѧ֪ʶ���Լ�����USMLE-style�����дﵽ83.5%ȷ���ٴ�ʵ������������������ҽԺר�Ҷ�200��ģ����Ͻ���ä������Ͻ�������ʴ�91%�����ɽ����Է�����ʹ��LIME�������ӻ���Ͼ���·�� δ���������� �ں϶�ģ̬ҽ�����ݣ�CTӰ������Ƭ��������̬֪ʶ���»��ƿ�������HIPAA�Ϲ��˽�л����� ͨ�����ĵ���������·�ߣ������߿���2-3���ڹ������ﵽʵ�ü���ҽ�ƴ�ģ�͡�ҽ��AI�Ľ���֮·�Ÿոտ�ʼ���ڴ����ഴ�������ⳡ�ü����ػ�������ΰ�����̡� ������ע������AI��������ѧϰ�����AI֪ʶ�� |

|
|
���У��������������ڱ��ز���DeepSeek-R1�Ķ������汾ģ����Щ�¶���DeepSeek-R1����DeepSeek�ŶӸ��������������ģ�ͣ���������汾�����ģ��ڱ��ָ����ܵ�ͬʱ�����ر���������Ч������Щ��Դ���Ļ�����˵����ֱ�������顰ģ�����������ô������汾���۸�զѡ�أ����ż��������ҽ��ʵ���������裬�������ϸ˵��˵���� ΪɶѡDeepSeek-R1����ѡDeepSeek-V3 �����ܶԱ� DeepSeek-V3�Ǹ�����ģ�ͣ�ͨ����ȷʵǿ���������������ﵽ��671B ����ɾ͵��������Ѽ��豸���������ϷѾ��ˡ���DeepSeek-R1����DeepSeek-V3�����ϣ�����ǿ��ѧϰ�ͼල����һ��ѵ�������ģ�����������ǿ�����Ҳ��������û��ô���ţ�����Դ���Ļ�����Ҳ���в����ı��֡� ��Դռ�öԱ� DeepSeek-V3��Ϊ������������������Ҫ���������Դ���ڴ棬��ͨ���Ѽ��豸����hold��ס��DeepSeek-R1������汾�Ͳ�һ���ˣ����õ��������������������أ�����˵�����ǰѴ���ģ�����֪ʶ�����������������ת�Ƶ�Сģ�������һ����ģ���ڱ��ָ����ܵ�ͬʱ���Լ�����Դ������ͽ������� ���ó��� Ҫ��������������Ҫ�߾��Ⱥ�����������Ӳ��Ҫ����ô�ں�����DeepSeek-V3�ǿ��Կ��ǵġ���Ҫ�����۴�����ˣ��豸��Դ���ޣ�������Ƕ��ʽ�豸���ƶ��豸��Щ��DeepSeek-R1������汾��̫�����ˣ��������ճ��ֳ������������ ����֧�ֺ���Ƶ�� ������֧�ַ��棬DeepSeek-R1������汾���ڸ�����ʵ��Ӧ�ó������ܵ��Ĺ�ע��֧�ָ��࣬��ɶ����������������ҵ��������������Ƶ����Ҳ��Ը���Ծ������ģ�Ͳ��Ͻ�������DeepSeek-V3��ΪӲ���ż��ߣ�ʵ��Ӧ�ó������ޣ������Ļ�Ծ�Ⱥ���Ƶ�ʶ���Ե�һЩ�� �����ģ�͵�ѡ��������ģ���ص� ��Hugging Face�ϣ�DeepSeek�Ŷ��ṩ�˺ü���DeepSeek-R1������汾ģ�ͣ���Qwenϵ�к�Llamaϵ�еȡ���Щģ���и�������㣬�ۿ������Լ������������� Qwenϵ��ģ���������ٶ����ر�죬Ҫ����������Ŀ��Ҫ���ٸ�����Ӧ��ѡ��û���� Llamaϵ��ģ���أ������������ϱ��ֳ�ɫ��Ҫ�ǶԽ������Ҫ��ߣ�����������ĵ������֡� |
|
|
���ط���Hugging Faceģ�Ϳ⣺ �������������Hugging Faceģ�Ϳ⣬�Ϳ��Խ�������ѡ��ģ�ͣ� ��ģ�Ϳ���ҵ�DeepSeek-R1������汾ģ�ͣ���DeepSeek-R1-Distill-Qwen-32B��DeepSeek-R1-Distill-Llama-8B��Щ������ģ��Ȩ�أ� �����ѡ�е�ģ�����ƣ�����ģ������ҳ�棬Ȼ���ҵ���Files and versions��ѡ����������ܿ���ģ��Ȩ���ļ���һ����.pt��.tar.gz��ʽ������������������� |
|
|
���ػ������ʵ���������谲װ��Ҫ�Ŀ� ���ȵð�װһЩ��Ҫ�Ŀ⣬��transformers��torch����װ����Ҳ���������������룺 ������Ͱ�װ������ ����ģ�� ��������transformers��������غõ�ģ��Ȩ�ء����������ʾ�����룺 ����д�����ܰ�ģ�ͼ��غ����� �������� ģ�ͼ��غú��������������ˡ�������������ʾ���� �������ܵõ�ģ�����������Ľ������ �����ú��Ż����ɵ����������� ��ʹ��ģ�ͽ�������ʱ���м����������Ե������������ܡ�����generate�����е�max_length�������������������ı�����ȡ������������ɳ�����Ҫ���Ժ�����������������������ɹ�������̵��ı�������temperature�����������������ı�������ԣ�ֵԽС���ɵ��ı�Խȷ����ֵԽ����Խ���ж����ԣ����Ը���ʵ�������������� ģ������ ģ��������һ�ּ���ģ���ڴ�ռ�úͼ��������ļ���������˵�����ǰ�ģ�͵�Ȩ�غͼ���ֵ�õͱ��ر�ʾ����transformers���У�����ʹ��bitsandbytes��������ģ�����������磬��ģ������Ϊ8���ػ�4���أ����Դ������ڴ�ռ�ã�ͬʱ��һ���̶��ϱ���ģ�����ܡ�����������������Բο�����ĵ��ͽ̡̳� ѡ��ʵ���ܽ� Ҫ�����Ӧ�ó������и��ӵ����������Ǿ�ѡ��������һ���ģ�ͣ��������ܱ�֤Ч����Ҫ����Դ���ţ��Ǿ�ѡ������С��ģ�ͣ�Ҳ������������� ѡģ�͵�ʱ��һ��Ҫ�����ڴ桢�Դ���Щ��Դռ��������ñ�֤ѡ��ģ�����۱����豸�������ȵ����У������ö������������� ѡ��Щ��Դ����֧�ֺõ�ģ�ͣ����������ˣ��ܺ������ҵ��˰�æ��ģ����Ҳ���㡣 ��������ʵ�����ӡ�����Ȼ�������ɳ������DeepSeek-R1-Distill-Qwen-32Bģ�ͣ������ٶȿ죬����Ҳ�ȽϺ��������ı����������DeepSeek-R1-Distill-Llama-8Bģ��ƾ��߾��ȵ����ƣ�����ȷ��ͦ�ߡ� ͨ��������Щ�����ѡ��ʵ�������Ǿ����ڱ��سɹ�����DeepSeek-R1������汾ģ�ͣ�����������Ч���������������ϣ����ƪ�����ܰﵽ��λС��飡 |
|
������deepseek�Ļش� �ţ��û��ʵ�����ΰ�DeepSeek-R1�����������ij�������ר�ҡ����ȣ�����Ҫ����DeepSeek-R1��ʲô������֮ǰ�����ϣ���Ӧ����һ�����͵�����ģ�ͣ�����������GPT�Ľṹ��������ϸ�ڿ���������ͬ���û���Ŀ���ǽ�����Ӧ���ض�������ҽ�ơ����ɻ��߽���֮��ģ���Ϊ�������ר��ģ�͡� ������������Ҫ��������Fine-tuning����֪ʶ����Knowledge Distillation�����ַ�������ͨ������Ԥѵ��ģ�͵Ļ����ϣ����ض���������ݼ���ѵ��������ģ�Ͳ�����ʹ����Ӧ������֪ʶ�������ǽ���ģ�͵�֪ʶǨ�Ƶ�Сģ���ϣ������漰���ô�ģ�͵������ѵ��Сģ�ͣ�ʹ���ڱ������ܵ�ͬʱ��Сģ�ʹ�С�� �û����ܵ�������ʲô�����ǿ���ϣ��ģ�����ض�������ָ��ã�ͬʱ����ϣ��ģ��С�����죬���߸���Ӧ���ǵ����ݷֲ�����Ҫ��ȷ���ǣ��û��Ƿ����㹻�����ݣ�������Դ��Σ��Լ��Ƿ���Ҫ����ģ�ʹ�С���ǿ��Խ��ܽϴ��ģ�͡� ���ȣ���������֣�����Ҫ������������������ص�������Ҫ�㹻�࣬�����ߣ�������Ҫ��ϴ��Ԥ������Ȼ��ѡ����ʵ������ԣ�����ȫ���������Dz��ֲ���������LoRA����ȫ����������Ч�����ã�������ɱ��ߣ�����������Ч���ʺ���Դ������������⣬ѧϰ�ʵ����á����δ�С��ѵ���ִεȳ�����Ҳ��Ҫ������������Ҫ���ʵ�顣 Ȼ����֪ʶ����������Ҫȷ����ʹ����Ӧ����������������Ӧ����ֱ���ô�ģ�͵������Ϊ��ǩѵ��Сģ�ͣ���������������漰���м���ƥ�䡣�û�������Ҫһ����С��ģ�ͣ����������Ŀ������Ǵ���һ�������յ�ר��ģ�͡�ͬʱ���¶Ȳ����������к���Ҫ�����������ƽ���̶ȣ�������Ҫ������ ���⣬������Ҫ�������������������ģ�ͣ�����������֪ʶǨ�Ƶ�Сģ�͡����ߣ����������м���������ʧ��ͬʱ�����������ݺͽ�ʦģ�͵������ ��������Ҳ����Ҫ���û���Ҫѡ����ʵ�����ָ�꣬���������ڵ��ض�����ȷ�ʡ�BLEU��ROUGE�������˹�������ͬʱ���������һ�����գ������������������������£���Ҫ��ͣ���ƻ��߽�����֤�� ������������ս�������ݲ��㡢��������϶ർ��ģ���������ѣ���������Դ���ơ���ʱ����Կ���������ǿ������ʹ�ô�ģ�ͱ������ɺϳ����ݣ�������������ʵ�������ʵ��ʶ�������� �û�����û���ᵽ�����������ϣ��ģ�Ͳ����ڸ�������ֺã���Ҫ����һ����ͨ���ԣ������ڲ���ʱ��Ч�����⡣��ʱ��ģ��ѹ�����������������֦������Ҳ��Ҫ���ǽ�ȥ�� ���ע����������Ҫ�ᵽ������������Ҫ�ԣ��������ϣ��Լ���ε���ʵ��ı�Ҫ�ԡ����ܻ���Ҫ������������ij���ѧϰ����ģ����ʵ��Ӧ���в��ϸ��£���Ӧ�µ����ݺͱ仯�� �ܽ��������ش�ĽṹӦ�ð��������������������������������Ż���ע������Լ����ܵ���ս�ͽ����������Ҫ�ֲ�����ϸ˵����ͬʱ����ʵ�ʵ����Ӻͽ��飬����ʹ��LoRA���и�Ч���������������������¶Ȳ��������ܻ���Ҫ�Ƽ�һЩ����⣬����Hugging Face��Transformers���������ѧϰ�����PyTorch�ľ���ʵ�ַ����� �� DeepSeek-R1 ��������Ϊ�ض������ר�ң���Ҫ����������ݡ�����Ŀ��ͼ������ԡ������Ƿֲ��������ָ�ϣ��������������������������ɺ��Ż����� 1. ����������������ĺ��ģ�1�������ռ��������������ϣ��ռ�Ŀ��������ı����ݣ������ġ����桢�Ի���¼���ṹ��֪ʶ�⣩������ҽ���������ٴ�ָ�ϡ�������¼�������������о��顢�������ġ� ����������ݣ����������������ʴ��ı����ɣ�������ע���ݡ����˹���ע�����ô�ģ�ͣ��� DeepSeek-R1 ���������ɺϳ����ݡ� ��2������Ԥ������ϴ��ȥ���������ظ��ı������������ͳһҽѧ��д������ǿ��ͨ��ͬ����滻��ʵ���滻�����滻�������ƣ����������ԡ���ʽ���룺������ת��Ϊģ�������ʽ���� [CLS]�ı�[SEP]����2. �����ԣ���ģ��ѧϰ����֪ʶ��1��ȫ���������ó�����������Դ���㣬��������ܡ�������from transformers import AutoModelForCausalLM, TrainingArguments model = AutoModelForCausalLM.from_pretrained("deepseek-R1") args = TrainingArguments( learning_rate=5e-5, per_device_train_batch_size=4, gradient_accumulation_steps=8, num_train_epochs=3, ) model.train()��2����Ч����������Ч��LoRA����ѵ�����Ⱦ������������from peft import LoraConfig, get_peft_model config = LoraConfig(r=8, target_modules=["q_proj", "v_proj"]) model = get_peft_model(model, config) # ��ѵ����������90%����������������ģ�飬����ԭģ�Ͳ�������3������ѵ���γ�ѧϰ����ѵ��ͨ���������ݣ�������רҵ���ݱ��������ѵ����ͨ���������������ݰ���������1:4����ϣ�����������������3. ֪ʶ����������ר��ģ�ͣ�1����Ӧ����Response Distillation�����裺������� DeepSeek-R1 ������������Ĵ���Ϊ����ǩ��ѵ��Сģ�ͣ��� TinyLlama�������Щ����ǩ�� # α����ʾ�� teacher_logits = teacher_model(input_ids) student_logits = student_model(input_ids) loss = KL_divergence(student_logits / T, teacher_logits / T) # T=�¶Ȳ��� ��2��������������ʦģ�ͣ�DeepSeek-R1����ѧ��ģ�͵��м���ʾ��# ��ȡ�м����� teacher_hidden = teacher_model.get_hidden_states(input_ids, layer=12) student_hidden = student_model.get_hidden_states(input_ids, layer=6) loss = MSE_loss(student_hidden, teacher_hidden)��3����̬������������ʦģ�ͺ�ѧ��ģ��ͬ�����£��ʺ��������ݳ��������ij�����4. �����Ż��ؼ�������1��������ʾ��������������������ָ������Ч����"����һ����Ѫ��ר�ң�����רҵ������ͣ��ļ�ȱѪ�IJ��������ǣ�"��2������ʱ���չ����δ��¼�ʣ���ҩƷ���������������ִ�����tokenizer.add_tokens(["EGFR", "CRISPR-Cas9"]) model.resize_token_embeddings(len(tokenizer)) # ��չģ�ʹʱ���3��ǿ��ѧϰ��RLHF��ͨ�����෴���Ż����ɽ�����ռ�ר�Ҷ�ģ����������֣���1-5�֣���ʹ�� PPO �㷨����ģ�Ͳ��ԡ� 5. �����������1������ָ������������BLEU��ROUGE��BERTScore������ȷ�ԣ��˹���������ʹ����ȷ�ԣ���ҽ�����ٴ�ҽ�����룩�������ٶȣ�Tokens/sec�������ģ�����ע���ٱȣ�����2������ʵ��ԱȲ�ͬ������ϵ�Ч��������ȷ�ʲ����������ٶ�ȫ������92.1%13B20ms/tokLoRA�� + ����91.3%0.3B5ms/tok 6. ����ע����������ѹ����ʹ�� GPTQ �� AWQ ��ģ�������� 4bit�����棺�Ը�Ƶ��ѯ���糣�������ʴ𣩽����������ݿ⡣����ѧϰ�����ö��������ƣ���Ӧ����֪ʶ���¡�ʾ��������ҽ���ʴ�ר�����ݣ��ռ� 10GB �ٴ����� + 5����ҽ���Ի��������� LoRA �� DeepSeek-R1��ѧϰ�� 3e-5�����ͨ�����ݣ�20%��������ģ������ Llama-2-7B���¶� T=5��������ҽ����������ʾ��Ͻ���ȷ�ʴ� 78% ������ 89%�� ͨ���������̣��ɽ� DeepSeek-R1 ת��Ϊ��Ч����ר��ģ�ͣ�ƽ�����������ɱ��� |
|
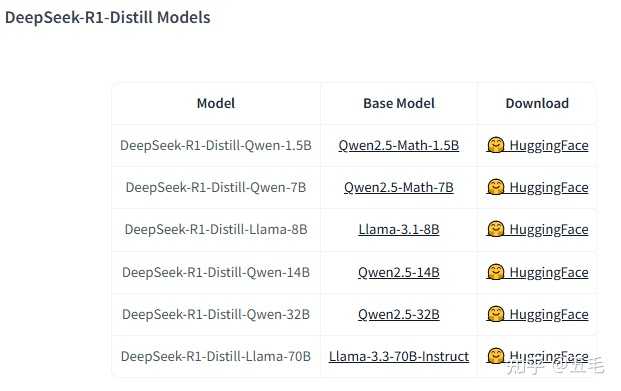
ժҪ DeepSeek-R1ͨ��������������ģ�͵����������ɹ�Ǩ�Ƶ�С��ģ���У�����������С��ģ�͵����ܡ�����������DeepSeek-R1��ʹ�õ��������������䱳�������������ܱ��ּ����ƣ���������������ĺ��㷨��Ϊƾ֤�� һ������ ���Ŵ�������ģ�ͣ�LLMs���ķ�չ��������Ȼ���Դ��������Ӧ��Խ��Խ�㷺����ͬʱҲ������������������ͼ�����Դ������ߵ����⡣DeepSeek-R1ͨ��������������ģ�͵���������Ǩ�Ƶ�С��ģ���У���Ч�������Щ���⡣ �����������ı����붯�� ��һ���������Ķ��� ����ѧϰ�е�ģ��������һ�ֽ�֪ʶ�Ӵ�����ģ�ͣ���ʦģ�ͣ�ת�Ƶ���С������ģ�ͣ�ѧ��ģ�ͣ��ļ�����Ŀ���Ǵ���һ����С��ģ�ͣ���ģ�ͱ����˽ϴ�ģ�͵Ĵ����ܣ�ͬʱ�ڼ�����Դ���ڴ�ʹ�ú������ٶȷ������Ч�� �������������Ķ��� DeepSeek-R1ģ�͵IJ�����ģ�ﵽ671B���������Ѽ��豸�����У������Ҫͨ��������������������Ǩ�Ƶ���С��ģ���У���ʵ�ָ���Ч�IJ����Ӧ�á� ������������ʵ�ַ��� ��һ�������� DeepSeek-R1��������̻������������ɵĺϳ��������ݣ���Щ������������DeepSeek-R1ģ�����ɣ������ﵽ80�����������˶�����������Ϊ����ģ���ṩ�˷ḻ��ѵ���زġ� ������ģ��ѡ�� �����Ŀ���ǽ�DeepSeek-R1����������Ǩ�Ƶ���С��ģ���У����ѡ����Qwen��Llamaϵ����Ϊ����ģ�ͣ���Щģ�͵IJ�����ģ��1.5�ڵ�700�ڲ��ȣ������˴�С�͵�����ģ�͵ķ�Χ�� ������������ ���������Ҫͨ���ල����SFT��ʵ�֣�ʹ��DeepSeek-R1���ɵ����ݶ�ѡ����С��ģ�ͽ��������������������ǿ��ѧϰ��RL���Σ���������ʽʹ��������̸��Ӹ�Ч��Ҳ���ʺ�С��ģ�͵�ѵ������ |

|
|
|
|
|
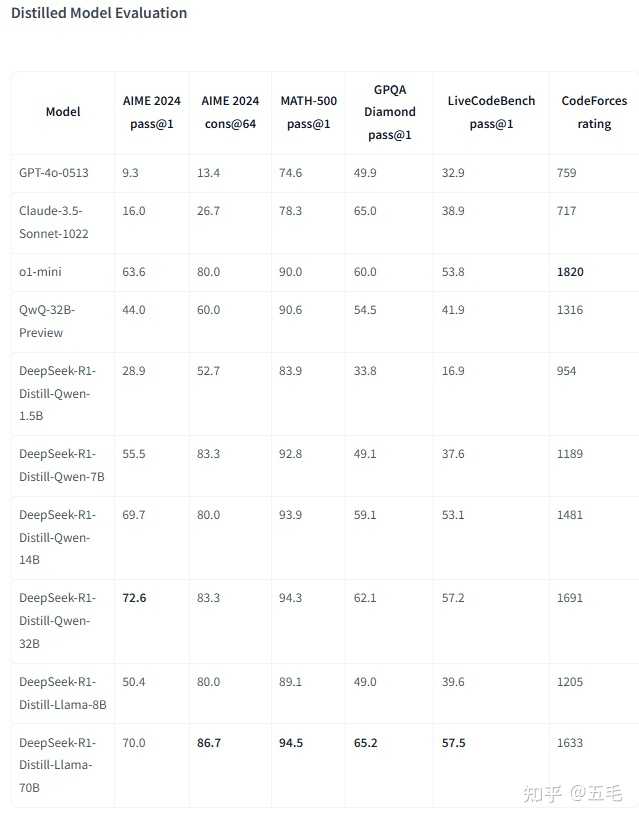
�ġ�����ģ�͵����ܱ��� ��һ���������������� ����ģ���ڶ�������������б��ֳ�ɫ�����磺 DeepSeek-R1-Distill-Qwen-7B��AIME 2024��ʵ����55.5%��Pass@1����Խ��32B��ģ��QwQ-Preview��DeepSeek-R1-Distill-Qwen-32B��AIME 2024�ϴﵽ��72.6%��Pass@1����MATH-500�ϴﵽ��94.3%��Pass@1��DeepSeek-R1-Distill-Llama-70B��AIME 2024�ϴﵽ��70.0%��Pass@1����MATH-500�ϴﵽ��94.5%��Pass@1�� ��������ǿ��ѧϰѵ��ģ�͵ıȽ� ����ͨ���Ա�ʵ�鷢�֣���DeepSeek-R1����Qwen-32B�ϵ�Ч����Զ����ֱ����Qwen-32B-Base�Ͻ��д��ģRLѵ������������ڽ�С��ģ�ͣ�ֱ��ѧϰ����ģ�͵�����ģʽ������̽����Ϊ��Ч�� �塢������������ ��һ��Ч������ ����ģ�͵IJ�����ģ��С������Ч�ʸ��ߣ����ʺ�����Դ���Ļ����в������磬DeepSeek-R1-Distill-Qwen-1.5B��С��ģ���ܹ������Ѽ��豸�ϸ�Ч���У���������DeepSeek R1�����������ģ������Դ�� ��������Դ�����չ�� DeepSeek R1������ģ���ǿ�Դ�ģ���ʹ���о���Ա�Ϳ�����Ա�����ڸ���Ӧ����ʹ�ú�����Щģ�ͣ���Դ���Բ����ٽ��˼����Ĵ�����Ӧ�ã�ҲΪ�����ṩ�˽�һ���Ż��Ľ�ģ�͵Ļ��ᡣ ��������������㷨 ��һ������ DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement LearningDeepSeek-R1������⣬�������������� �������㷨 ǿ��ѧϰ�㷨��DeepSeek-R1ʹ���˴��ģǿ��ѧϰ��RL��ѵ����ͨ�����Ҳ��ĺͽ������Լ���ģ��ѧϰ���ӵ��������ԡ��ල����SFT�������������Ҫͨ���ල��ʵ�֣�ʹ��DeepSeek-R1���ɵ����ݶ�ѡ����С��ģ�ͽ������� �ߡ����� DeepSeek-R1��������Ϊ��������ģ�͵���������Ǩ���ṩ��һ�ָ�Ч�Ҿ��õĽ��������ͨ����DeepSeek-R1��ǿ����������Ǩ�Ƶ���С��ģ���У���Щ����ģ����������������ȡ������������ܣ�ͬʱ���������˼���ɱ�����Դ���Խ�һ���ƶ��˼����Ĵ�����Ӧ�ã�Ϊ��Ȼ���Դ�������ķ�չ�ṩ���µ�˼·���ߡ�δ��������������Ե��Ż��Ϳ�����Ӧ�õ���չ�������������ڸ��㷺�ij����з��Ӹ�������á� |
|
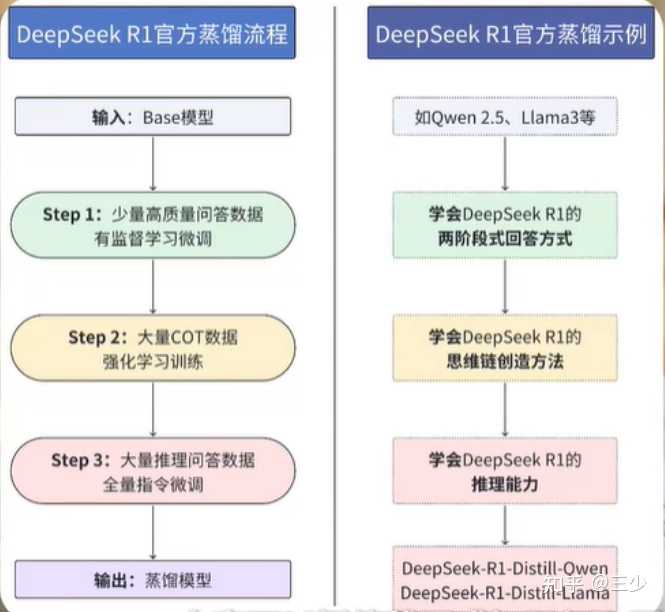
רҵ�������⣬����Ҫ�ο�deepseek2025��1��22�������Լ��������ġ� ���������ܽ�ģ���Ҫ�� DeepSeek-R1 ���������ij�����ר�ң�ͬʱ���㲿����С�ͻ����е�Ҫ���������������������ᵽ�ĺ��ļ��������� һ�仰��ͨ�����������ݡ����������ǿ��ѧϰ��RL�������������ܹ�ʵ�ּ�С��ר��ģ�Ͳ���Ŀ�ꡣ ��ʵ�������� ����һ�£���Ҫѵ��һ��ֻ�ὲ������ѧ֪ʶ�ġ�ģ��ר�ҡ�����ϣ����С������������ĸ���GPU�ϡ�����������һ����ʦ��Ҫ��ѡ�������IJ��ϣ������Ⱦ����ֺóԵķ��ˣ������������������в�ϵ��ʳ�ס�DeepSeek-R1 �ķ���������������������� ����������㹻С���͡�����ר�һ����� �����и����Ķ�η����ܽ����£� ����������Cold Start Fine-Tuning�� Ŀ�꣺ʹ��������������������Ϊģ�ͽ���һ���������������������������ס�������֪ʶ�ʴ�QA������ȡ����������������Chain of Thought��CoT�����������ص㣺�ⲿ�����ݲ���������ģ�Ͷ��ض���������⣬�����Ż���ش�ṹ�����磬��������ѧ�������ɵ����ݿ����Ƿֲ����������������ѧ��ʽ�Ƶ��ȡ�Ч������ǿģ�����ض������֪ʶ����������ͬʱ��߿ɶ��ԡ� ���������ǿ��ѧϰ��Reasoning-Oriented RL�� Ŀ�꣺��һ���Ż�ģ���ڸ������������еı��֡�ʵ�֣� ͨ������������������ȷ�ʽ�����ʽ������������ģ�����ɷ���Ԥ�ڵĻش𡣼�������һ���Խ�����Language Consistency Reward�����������Ի�����⡣ �ɹ���ǿ��ѧϰ������������ģ������ѧ���������ȷ���������� ģ������Distillation�� Ŀ�꣺������ģ�͵���������Ǩ�Ƶ�С��ģ���ϣ�������Դռ�á�ʵ�֣� ʹ�þ���ǿ��ѧϰѵ����� DeepSeek-R1 ���ɴ���������������������Щ������������ Qwen��Llama �ȿ�ԴСģ�͡� ����������������������� DeepSeek-R1-Distill-7B��7B�������ڶ�����������г�Խ�˲��ָ���Ŀ�Դģ�ͣ��� GPT-4o��6?source����������β��������������� vs. ר�á�ì�� ��ģ�ͣ��� GPT-4��Claude�����Դ����㷺����ȱ�����ڣ� ��Դռ�øߣ�������Ҫ����Ӳ��������ɱ����ߡ�������Ȳ��㣺����ģ�Ϳ�������ȷ����ijһ�����ϸ�ڣ����紦��ҽѧ�����е�רҵ���⡣ ����ģ��С�ͻ���רע��һ��������ѵ����ڣ� ���ȷ��ģ�����ض������ϵĸ����ܣ�֪ʶ�������������������������ٵļ�����Դʵ�ֽӽ���ģ�͵�Ч������ξ���ʵʩ��1. �������������� �����ռ�Ŀ������ĸ��������ݣ������� �����������ݣ�������ѧ�еĹ�ʽ�Ƶ�����ϸ�������¡�����֪ʶ�ʴ����һЩ��ȷ�����⣬ָ��ģ�����ɴ𰸡� ѵ�����ڣ�ʹ����Щ���������ݶԻ���ģ�ͣ��� DeepSeek-V3����������ȷ�����������������ṹ���Ļش� 2. ����ǿ�� ����ͨ��ǿ��ѧϰ�Ż�ģ�͵����������� ��ƽ����������ȹ�ע�ش���ȷ�ԣ�Ҳ��ע����Ŀɶ��ԡ���Զ��������ݣ���������һ���Խ�����ȷ�������ʹ��Ŀ�����ԡ� ��һ�ο��Խ��� Group Relative Policy Optimization��GRPO���㷨������ѵ���ɱ���ͬʱ����ģ���Է��������������� 3. ����Сģ�� ���Ż���� DeepSeek-R1 �����ɴ���ѵ�����ݣ���������С��ģ�ͣ��磺 Qwen2.5 ϵ�У�1.5B~32B ��������Llama-3.1��Llama-3.3 ϵ�С� ֱ��������ЩСģ�Ϳ��������������ǵ��������������������½���ǿ��ѧϰ�� 4. ���������� ������ģ��С�����Բ����ڸ��� GPU ���ͷ������ϣ��� RTX 4090 �� A100�������⣬�����е��������������ַ������ɵ�Сģ�������������ϵ������������Գ���ijЩδ�����Ż��Ĵ�ģ�͡� �᷽ܽ����������ȷ���Ŀ��������������ݡ�������ȣ���������������������ǿ��ѧϰ�Ż��������ʡ����������������ģ�͵���������Ǩ�Ƶ�Сģ�͡���������ѡ���ʺϵ�Ӳ�����ã����� 7B ������Сģ�Ϳ��������ڸ߶˹���վ�ϣ�������Ҫ����������� δ�������С������ģ�ͽ���Ϊijһ����ġ�֪ʶ���������ֿ����ȣ�רҵ��ʡǮ�� |
|
|
| [�ղر���] �����ر��ġ� |
| ���� �������� |
| ������ۻ�Ϊ���ɵ��ԣ� |
| ��ο���С��Sky Nomad С����̣� |
| С��Ϊ�β����ţ� |
| codex��windows��������ֻ����wsl�в��ǡ� |
| Ϊʲô����û�е��գ� |
| ��ο���ij��touch����ƽ������������ |
| �������������� |
| ��23��������������Dz���߯���ˣ� |
| �Ż�Ӧռ����ռ�8������㣬���ϰ�װ��ʮ |
| С�������ĸ����ɹ��� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
|
��������:
��ӰƱ��
����Ȧ
����
����
����
�����
ӡ��
�ɼ�
��س
����
��ˮ
��Ǯ�ҽ���ר��
����
˫ɫ��
����ĸ��
����
ƹ����
�й�Ů��
����
nba
�г�
�ܲ�
����
���
��ɫ
�Ϻ��п�
80��
����: ���� �����ֶ� ������ķ�ȴ� �ʼ������� ����ͼ˹ ���� ����� ���� �ﰺ ����ʥ�ն��� ���� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ֪ʶ�� |