| |
|
|
| ֪ʶ�� -> �Ƽ� -> Ϊʲô LLM ��Ԥ����һ�ʣ����ܡ�ӿ�֡����������� -> �����Ķ� |
|
|
[�Ƽ�]Ϊʲô LLM ��Ԥ����һ�ʣ����ܡ�ӿ�֡����������� |
| [�ղر���] �����ر��ġ� |
|
�о�����Դ��кν��ͣ� |
|
�о�������¶��Ѿ����˺ü��꣬��֪���ļ��������Ľ���˼·�����Ը��������� ��˵������˵�����ĽǶȡ�����Ϣ���ӽǡ��и��� Hutter Prize �ı����������������"˭�ܰ��ı�ѹ���ø�С��˭������"��������ͦ��ֵĶɣ�����ϸ���룬Ҫ�Ѻ����ı���Чѹ����������ҵ�����Ĺ��ɺ�ģʽ�� Marcus Hutter ����������ǣ�Solomonoff ��ͨ��Ԥ���������ϵȼ��� Kolmogorov ��ͨ�����ѹ��������˵���ǣ�Ԥ���ĸ�������ܳ��֣����ҵ���̵ı��뷽ʽ������ѧ����ͬһ���¡����Ե�ģ��ѧ��Ԥ�����Էֲ�ʱ����ʵ������ѧϰ������Щ���Ե�����ṹ�� ������������ۺ�ʵ���϶�վ��ס�ţ���Ϊ���Ա�����������˼ά��Ũ��������������������������淶��������ʶ����ģ��ҪȷԤ��"����غ��____"���͵�����������ҪԤ��Ի��ظ����͵������罻��ͼ��ѹ�����Էֲ��Ĺ��̣�����ģ��ȥ����һ���ڲ�������ģ�͡� ��OpenAI �� 2020 �귢��ƪ Scaling Laws �����ģ�����ģ����ʧ�Ͳ�������������֮�����ȶ������ɹ�ϵ����Խ�߸������������������� DeepMind �� Chinchilla ������������ۣ�˵��ʵģ�Ͳ�����ѵ�� token Ҫ�ȱ������������ţ����ÿ��������Ҫ 20 �� token�� https://arxiv.org/abs/2001.08361arxiv.org/abs/2001.08361 Jason Wei ������ 2022 �귢�������ġ�Emergent Abilities of Large Language Models��������ӿ����������С��ģ���в����ڡ����ڴ���ģ����ͻȻ���ֵ���������Щ������ͨ��������Сģ��������Ԥ�� https://arxiv.org/abs/2206.07682arxiv.org/abs/2206.07682 ��˹̹�� 2023 ������ġ�Are Emergent Abilities of Large Language Models a Mirage?���Դ�������ɣ���Ϊӿ�ֿ���������ָ�꣨�����Ի�����ָ�꣩��ɵļ�����ģ����Ϊ�ĸ������ https://arxiv.org/abs/2304.15004arxiv.org/abs/2304.15004 ˵ӿ�ֿ�����"������¥"��������ģ�ͱ���ͻ���ˣ����������õ�����ָ��̫��ɢ���������仯������ͻ�䡣��������ȷ����������40% �� 60% ���Ų�࣬������ F1 �������ܾ����ʵķ�Ծ�� ��2025 �����µ�������������������⣺ӿ�ֵ�������ʵ����䣬���Dz�����ʽ�ļ��� https://arxiv.org/abs/2503.05788arxiv.org/abs/2503.05788 ���Ե�������Dz��ǡ�ӿ�֡���û��û�ǹ��ۣ����и���������ʵ�ġ���Grokking�������������ȹ����ѵ�����ݺܾã�Ȼ��ͻȻ�����������ǡ��о�������ȷʵ�������ٽ�ָ����������������һ����䡣����ij�̶ֳ��ϣ�"ӿ��"����������ܲ���ȫ�ǿջ��� ���˿϶��ģ��һ����ٸ�����������ͬ�Ƕ������ģ� Bender ������ΪLLM ֻ���ڸ����Ͻ��ʺ;���������һ�𣬶����������壬��˱���Ϊ"�������" https://dl.acm.org/doi/10.1145/3442188.3445922dl.acm.org/doi/10.1145/3442188.3445922 ��ƪ���������˾����飬�����ֵ�ͦ��Gebru �� Google Ҫ�����Ļ�ɾ�� Google Ա�������֣�����ȸ�����ˡ� ���о��� Gary Marcus �������������ˣ����������翪ʼ��˵���������ɿ������ƺͽ�����ʽ�������������ѧϰʲô�Ķ�һֱ��˵ https://arxiv.org/abs/1801.00631arxiv.org/abs/1801.00631 ������25��2���ڣ�CACM���Ĺٷ��ɷ��� Marcus ����ϸ̸������ LLM ���������ԵĿ������Լ�Ϊʲô����Ϊ��ģ����������������ݼ������⡣ https://cacm.acm.org/opinion/not-on-the-best-path/cacm.acm.org/opinion/not-on-the-best-path/ �����Ҿ�����˵��Ϊʲô��ӿ�֣��𰸻���δ֪�ġ���Ϊ����������ھ�����ô��״̬������һ������˼�����ۣ�ÿ�����ܽ���һ��������˭Ҳ����˵�Լ���ȫ�����ˣ�˭Ҳ����˵�Լ��ǶԵģ��Ͼ����о��˼��ꡣ ���ǵ�ȷ�����˴�����ģ�͵�������ӿ������������������ˣ����Ǿ�����������˵�Ŀ��ܲ����Dz���������Ҫ���ϸ����ѧ���塣 Ҳ���ȹ������ٿ���˵������������ˡ� ������ ��û�������������һ�����߰� |
|
�������ʵ������ѧ�����ҵ��ܾã����������ڣ�OpenAI �ڲ�Ҳû�˸������ظ�˵�Լ���ȫ�㶮�����е�ȫ�������� ������� SVM�����ع飬�������� LSTM��BERT���ٵ����ڵ� GPT ϵ�У��ۿ���ģ�Ͳ����Ӽ����ǵ������ڡ������ȥ��һ����¼�˸��ּ�����Ǩ�� ��ģ��237ƪ�ض����ĺϼ����ᷢ��һ����Ȥ�����տ�ʼ��Ҷ����ó�����һ�����ı����������⣬��ô����д���롢���������������ܸ��㽲Ц�����ⲻ�������Ƕԡ����ܡ����ֵĴ�ͳ��֪��������ǰ��������Ӧ���ǽṹ���ģ�������ȷ�����ŵģ��������������Ƶ������Ķ����� ����ʵ��������һ�������Ķ��⡣ ֻҪ�����������ݹ��࣬�����ܱ�������Ԥ����һ���ʣ�������ӿ�ֳ��������� �ⱳ���������ʵ�dz�Ӳ�ˡ��Ұ���Щ�����㷨�������ġ���ͬ��ͨ��debug�ij����Ķ����������˸����˵һ˵����ָ������ʲô��ʿ����֮��ı�������Щ����ƭ���еģ�����ֱ�ӿ����ʡ� ѹ�������� ����Ŀǰ��Ӳ�˵�һ�����ͣ�Ҳ���Һ��Ƴ��һ���۵㡣OpenAI �� Ilya Sutskever ��ǰ����������ߡ� �����ô�룬Ԥ����һ���ʣ����������ڶ����ݽ��� ����ѹ���� ����һ�£���Ҫ���������������ı�����ѹ����һ��ģ������ģ�͵Ĵ�С����������ԶС�����ݱ����Ĵ�С��Ϊ����ȷ��ԭ��Ԥ�⣩����Щ���ݣ�ģ�ͱ��뱻��ȥѧϰ�����ڲ��� ���� �� ���� ��������㱳��Բ���ʣ�������Ӳ���ܱ�������λ�������������Ԥ��Բ���ʵ���һλ����⿿����Ӳ���Dz��еģ����������Բ���ʵļ��㹫ʽ��һ���������˹�ʽ�����������Ԥ����ȥ�� �ı�Ҳ��һ���� ��������һ�λ���д���������ǰѳ��ص�Կ�ײ�����ף�����һŤ��ֻ������һ������__�� ����Ԥ��������� �� �ˡ� �⿴��������ģ��Ҫ���������Ԥ��� �� ����֣�����Ҫѧ��ʲô�� ����ѧ��������ʶ��Կ�ײ������Ť��ͨ���ᵼ������ ����ѧ������ϰ�ߣ�����һ��ͨ���ǻ�е�ṹ������������ ����ѧ�������ϵ��Ť�������ſ��ǹ��� �ֻ��������ӡ������һ����̽С˵�أ� �������ŵ��ϵ��̻ң�ͻȻ��������������ǰ�Ӳ����̣�Ψһ�����������Ǹ���Ʋ�ӵ�__�� ҪԤ�������� ������ ���߾�������֣�ģ�ͱ���߱� ���ڼ��䣬����߱� ������������������ ������Ϊ�� ����������֪�������̵��˵������̻���ζ�������������������ý��ǰ���ᵽ����Ʋ������ȥ��λ������ˡ� Ϊ�˰���� ��һ���� Ԥ����ģ�ͱ��Ƶ�û�취��ֻ��ȥ ���� ����������������ɡ������������⣬����Ϊ�˽���Ԥ������ʣ�Loss�������� �ݻ��������������� ��Ϊ��������⣬����ѹ��������ô����Ϣ������Ԥ��ȷ�ʾ��ϲ�ȥ�� �����ں������ݵ�ѵ���£�Ԥ����һ���ʣ��ȼ���ѧϰ������Щ���ݵ� ����ģ�͡� ������ǰ���㷨�������Ÿ�ģ����Ƹ��������������������������ν����������ϵ�����ڷ��֣���������Ҫ����ֻҪ�����㹻�ѵ�Ԥ���������Լ�������ǧ�ڸ������������һ����������Ŀǰ������������ȷʵ��Ч��������ʾ�� ���ֱ�ʾ���������˹���Ƶ�Ҫ��ά�ö࣬Ҳ��ϸ�öࡣ ˵���⣬����������ﵫ�ܱ��ʵĶ����� ����ģ�ͱ���������ѧϰһ����ά�ռ��еĸ��ʷֲ��� ������������ԡ�����֪ʶ���������ά�ռ�������������µģ����Ƿֲ���ijЩ�ض��� ���Σ�Manifold���ϡ� ��ǰ�Ĵ����������� Word2Vec���Ƚϼ�����ѧ�� ���� �� ���� �ľ��룬��ͺñ� Ů�� �� Ů�� �ľ��롣����һ�ּ����Թ�ϵ�� ���ڵ� LLM�������������������������ռ�dz������ҳ��ܡ� ��������һ�� prompt ��ʱ������ʵ���������ά�ռ���ȷ����һ�����ͷ���ģ��Ԥ����һ���ʣ�������������������Ÿ����ܶ���ߵ�·����һ��������������������ʵ�ײ�ȫ�Ǿ������㡣���������Ա任��ռ�ӳ��о���������ĺܳ�����ȥ���� 3Blue1Brown�����Դ����ʼ�.pdf�����ܰ��㽨����ֱ�۵ļ���ֱ�������������������������ѧ���汻ѹ��������ġ� ����ĵط����ڣ�������νṹ����Ȼ�����������ֳ�������Ҳ�����ȥ�ˡ� ���о����֣�������ģ������ѧ�������������ʱ�����ڲ�����Ԫ����ģʽ������������ͨ�ı�ʱ�Dz�һ���ġ����������Ǹ���ά�ռ���ҵ���һ��ר�Ŵ��� ���任 ��ͨ���� ӿ�� �������ܿ��ܾ��ǵ��������ﵽһ����ģ�������ά�����㹻�������㹻ƽ����ʹ��ģ�Ϳ��Դ�һ������ƽ�������ߵ���һ���������������������ѵ�����������û��ֱ�Ӱ���һ����ֹ��� ����� ������ ��ǰ��Сģ�ͣ�����������ģ�ȫ�ǿӿ����ݣ��������͵������ˣ���������ϻ�������ģ�Ͱ���Щ����ƽ�ˣ��Ѷ�·��ͨ�ˡ� ��֮ǰ����Ŀ��������һ�������������һ��Сģ��ȥ��������д SQL ��䡣Ч���ܲ�����ӵ��Ƕ�ײ�ѯ�ҡ��������˸�����ģ�ͣ�����������ʮ��������û��ôר�Ẓ̌����Լ�����д���dz����ӵ� join ��ѯ�� Ϊʲô�� ��Ϊ�ڴ�ģ�͵�����ռ����Ȼ���Ե��� �� SQL ������� ��ӳ�䵽������������������� ��ѯ �������ı��ʣ����������Ǽ�ס�� select * from table ������������ ���� �������Ķ��룬��ӿ�ָ������Ļ����� �����̵Ķ�֪�� Scaling Laws����˵���ǣ����������ݡ���������������ָ�������ӣ�ģ�͵����ܾͻ����������� �������и� ��䣨Phase Transition�� �����⡣Ҫ��������䷢���������ϵ���ս�Ǿ�ġ���ȥһЩ���������ʱ��ע��ϸ�ڣ��������ȥ���� �ֽڴ�ģ���㷨�������ֲ� ��д�ģ� ������ᵽ�������ִ��Դ��Ż����ֲ�ʽѵ���Ŀӣ��ٵ��������١�����Щ������ۻ������ Scaling Laws ������Ч��Ļ���� �ܶ��������������������ġ���ģ�ͺ�С��ʱ������ȫ�������ӷ�����������һ�㣬�����Dz��ᡣֱ������ͻ��ij���ٽ�ֵ�����ļӷ�����ͻȻ�� 0 ������ 100�� ������տ�ˮ��0 �ȵ� 99 �ȣ�ˮ����Һ̬��������ûʲô�仯������ 100 �ȣ�ͻȻ�������̬�� ���� LLM ��˵��Ԥ����һ���ʵ������ڵ������£�ģ����Ҫ�� ͳ�ƹ��֡����翴�� �˹� �ͽ� ���ܣ����� �� �ͽ� �ǡ�����ȫ��dz���ͳ�ƹ��ɡ� ����ģ���㹻�������ֹ⿿ͳ�ƹ����Ѿ�û����һ������ Loss �ˡ���Ϊ�ܶ��ı�����Ҫ���������Ԥ���ġ� ��ʱ��ģ���ڲ����ܷ�����ij�� ��䡣����ʼ�� ����ģʽ �л��� ����ģʽ�� ��ƪ������˼�����Ľ� Grokking����������ģ����ѵ�������Ѿ�������ˣ�ȷ�� 100% �ˣ���ʱ�����ѵ������֤��ȷ�ʱ����Dz����ģ�ͻȻ��ij��ʱ��㣬��֤��ȷ������� ����ζ��ģ�������� ����Ӳ�� �Ľⷨ��ͻȻ�ҵ��� ͨ�⣨General Solution���� ��Ԥ����һ�����������ı����£���ģ�ͱ���ȥѰ��ͨ�⡣��Ϊ������̫���ˣ���������������������ϡ�Ϊ�����棨���� Loss����������ѧ�������㷨�� �������ʦ������һ�����ѧ�⡣�������������ޣ���������ÿ����Ĵ𰸡�����Ƶ�û�취��ֻ��ѧ�������ֹ�ʽ��һ��ѧ���˹�ʽ����Ͳ���Ҫ�����ˣ�������߱���������������� �����ӿ�ֵı��ʣ��㷨���ڻ��� ��һ����ܶ��������ԡ����ڵ� LLM ֮����������ǿ���ܴ�̶�������Ϊѵ������������˺����� ���롣 �������Ȼ���Բ�һ�����������Ͻ����������� if A then B else C�����ֽṹ�ڴ������Ǿ��Բ��ܴ��ġ�ȱ��һ�����ţ�������ܲ�ͨ�� Ԥ��������һ�� token����Ԥ����Ȼ����Ҫ�ѵö࣬ҲӲ�˵öࡣ ��Ԥ�����Ĺ����У�ģ�ͱ���ѧ���� ״̬���٣�State Tracking�����������ü�ס 100 ��ǰ����ı��� x ��ʲô���ͣ��ڵ� 101 �е��õ�ʱ�����Ԥ��ԡ� ���� �������������ϵ �� �ϸ����ִ�� ��������ģ��ѧ����Ǩ�Ƶ�����Ȼ���������ϡ� ������ᷢ�֣����ڵ�ģ��д�������ر���������һ�㡢�ڶ��㡢�����㣬����˿�Ϸ졣��ܿ��ܾ��ǴӴ�����ѧ���� ˼ά����Chain of Thought�������� ���и�����ģ��Ԥѵ�������Ѹ����Ĺ���������ѵ�����������������ģ�͵������������������ۿɼ����½�����ͷ���֤���ˣ�Ԥ������ next token���ǹ������������Ĺؼ�һ���� �����ٻ����Ƕȡ� ���ǿ��� LLM ������һ����� ��Ҷ˹�������� ÿһ��Ԥ����һ���ʣ���ʵ��������һ�α�Ҷ˹���¡� P(Next Word | Context)�� ��� Context�������ģ���������������� Prompt��Ҳ���������Լ��ո����ɵĴʡ� �������ɵĴ�Խ��Խ�࣬Context ��������Ϣ����Խ�Ժ������ݵ�Լ����Խǿ�� ����˼������Ĺ��̣���ʵҲ�����Ƶġ� ��������д�������д���µ�ʱ���������и�ģ�����뷨����ͼ������д�µ�һ���֡�����ֻ�������ڶ����ֵ�ѡ��д���һ�䣬������ڵ�һ��Ļ�����д�ڶ��䡣 ���˼�������ֵ����ɹ��������͡� �ܶ�ʱ�������Լ�����֪���Լ���һ��Ҫ����˵ʲô��ֱ�����ǰ���һ��˵�ꡣ���Բ�������˼������壬���Ա�������˼��Ĺ��̡� LLM ������ģ����������̡� ������ҪԤ�ȹ滮������������¡���ֻ��Ҫ��ÿһ�������ڵ�ǰ�������ģ�������������ƶϡ���ÿһ�����ߵú���ʱ�����忴��������ӿ�ֳ��˺��������ǻۡ� ���е������������ÿһ�������ѡ��ֻ��Ϊ�˵��µ����棬û�г�Զ�滮��������������ĵ�������Ȼӿ�ֳ������������ô���ӵĽṹ�� Next Token Prediction�����ǽ�����ѡ��ѹ����Loss Function��������Ȼѡ��ļ����� ���и����⣬Ϊʲô���ı�Ԥ�⣿Ϊʲôͼ��Ԥ��û����ô���Ե���ӿ�֣� ��Ϊ������ǻۣ����ֶ�Ũ�����ı�� ����������˼ά�ĸ�άͶӰ�����Ǽ�ǧ�����ʷ����ѧ����ѧ����У����������������ˡ� ͼ����Ȼ��Ϣ�������� ��֪ ����ġ�һֻè��ͼƬ�����ص�֮������ǿռ�����ԡ� �����֣��� ���� ����ġ����ַ���֮�䣬������ ������������� ��ϵ�� Ԥ���ı�������������ѧϰ����� ˼ά��ʽ�� ����ѵ��ģ��Ԥ�� �ո��������ˣ������˶���һ���������ո�����____�� ģ��Ҫ�� �������ⲻ�����Ǵ���������������������� �������ϵ��ı����ݣ��������������е������ۡ����ɷ����������֤����ģ�Ͱ���Щ��ѧȥ�ˡ� ���ԣ�����˵ģ��ӿ�������ܣ�����˵ģ�� ���� ������Ⱥ���ǻ۵�˼άģʽ������һ�澵�ӣ��������ȫ�����ڻ����������µ�˼ά�ۼ��� ǰ��ʱ�����Ǹ��˸���ά�����˵���Ŀ����ǰ�ķ�����дһ�������ƥ�����ȥ��ȡ Log ��Ĵ�����Ϣ�������ˣ�����һ��������ʽ���˾�ʧЧ�� �������������� LLM�� ���ǰѱ�������һ�� Log �Ӹ���������Ԥ��������ķ����� ע�⣬����û��ר�Ž�����ô�������� ���ǣ�ģ����Ԥѵ���Σ����� StackOverflow������ GitHub �ϵ� issue ���ۣ��������ּ������͡� ��������һ���ض��� Java ��ջ�������ʱ����Ԥ����һ���ʵĸ��ʷֲ���Զ����ֳ��� �ڴ�й©��HashMap����ѭ�� ��Щ��� �������Ľ����ǣ����һ�´������Dz����ڱ��� Map ��ʱ�������ɾ�������� ������Ǿ����°͡�����������ƥ�䵽�˴������������������� �������� ��֮����������������Ϊ������ѵ�����������������Ա��Ԥ����һ���ʵ�ʱ�� ���� �� ���� ���������ˡ�ģ�Ͱ����ֹ���ѹ�����˲���� ���������뱨����ģ�;������Ǹ�ά������ռ��˳�Ÿ������Σ��ҵ��˳������ڵ����� �ܶ��˾��ã�����Ԥ����һ���ʣ���Ҳ̫���˰ɣ�������ô������ô�� ����ֱ���Ǵ��ġ� ����̫�� Ԥ�� ���������Ѷ��ˡ� ��һ�����ŵ������ʵ��������Ԥ�⣬����ȫ֪ȫ�ܡ� �����룬�����Ҫ����Ԥ������Ĺ�Ʊ�۸���Ҳ��һ��ʱ�����ݣ������� Next Token��������Ҫ֪��ʲô�� ����Ҫ֪��ȫ������ξ��ơ��������ߡ���˾�Ʊ����������ڵ�����״̬�� �κ�һ����Ϣ��ȱʧ�����ᵼ��Ԥ��IJ������� ���ԣ����µ�Ԥ��ȷ�ʣ���������������е���ģ��ȥ��ģ�������硣 LLM ���ڵ�������Զû�е��������ڵ� Loss ��û�н��� 0��Ҳ�����ܽ��� 0����Ϊ���������ڵ�����ԣ��������кܴ���½��ռ䡣 ֻҪ Loss ���ܽ���ģ�Ͷ����������ͻ��ܸ�� ��Ȼ�����������ģ��������������һ�����ǿ������Ҳ���ֹ��� �����Dz��������д��������ǻ۵ı��ʣ� Ҳ��������ԵĹ�����ʽ���ڵײ�����ϣ���ľ���һ�����Ͻ��� Next Token Prediction �����������磿 ��������һ�仰�������Զ�Ԥ����һ�䡣���ǿ���һ�������������Զ�Ԥ������ ������ν�� ��С�������ʶ������ֻ�Ǵ��ģ�������ڴ�������Ԥ������ʱ��ӿ�ֳ����ĸ߲������� �������������������������ߵ�����·��������ľ���ͨ�� AGI��ͨ���˹����ܣ��Ŀ�ׯ����� ��Ȼ�����ڻ��кܶ����⡣�þ����⡢��һ�������⡢�����ڼ������⡣ ����Щ�����ǹ������⣬������ԭ���ϵ�����ͬ�� ����ΪʲôԤ����һ������ӿ�����ܣ� ѹ�������⣺Ϊ���ں���������ʵ�ָ�ȷ�ʵ�Ԥ�⣬ģ�ͱ���ѧ�������ݱ�������ɹ��ɣ�Ҳ��������֪ʶ����������ά����ռ䣺ģ������һ���������������������ij������νṹ�����������������ռ����·�����ߡ�Scaling Laws ����䣺���������ʱ䣬��������һ���̶ȣ�ģ�ʹ�ͳ�Ƽ���ת�����㷨���ݡ��������ݵļӳ֣�����ѵ����ǿ��ģ�͵��Ͻ����ͳ��������������ı��������ԣ��ı�������˼ά�ĸ߱���ͶӰ��ѧ�ı�����ѧ˼ά�� ���¶�ûʲô��ѧ�ģ�ȫ����ѧ�������ѳ������漣����������Ϊ����ѧ�������˾��ø�����Ϊ����ζ�ţ������ǿ��Ա�����ģ��ǿ��Ա�����������������ġ� �����������ʦ�����Ҽ�֤��������������̣�˵ʵ��ͦ�����ġ� ����δ���ⶫ���ᷢչ��ʲô�����������ڣ����������һ���� �Զ���ȫ���ߡ�����һ������Ŭ��ͨ��Ԥ����һ���֣�����ͼ��������������ӡ����ҵ��ֳ������������ ��Ȼ��� ������ ��û�������������һ�����߰� |
|
кҩ�� ����Ҫ����һ�����������Ҳ������������������壺Ԥ����һ�������������������Ŀ�ģ������ֶΣ������Ǹ��ޱȲп����ʧ����Cross Entropy Lossǿ�Ӹ�ģ�͵Ľ����䡣 ����Ҫ��ʱ�䲦�ص�2023�꣬��ʱ���һ�������GPT������û����ʶ�����ڻ�ͷ�������Ǹ��ܳ����ĽΡ����ڵĶ�����Դģ�ͣ������ǿ�Դ���SOTA�����ǵ�ѵ��Ŀ����Ȼ������Next Token Prediction��Ϊʲô����Ϊ��������㹻�ѡ� ��Ҫ�����һ���£���ģ����Ժ������������ݣ�Ҫ��Ԥ����һ������ʲô��ʱ�������ٵ���һ��ʲô�������Ϣѹ����ս�� ����˵���Ҹ���һ����룺public static void���㲻�����˻���AI��������֪�����������main�����dz������䡣�������������ø������������Сģ�;���������������Ҫӿ�֡� ���ǣ����ǰ���Ǽ�ǧ�ֵ����������Ƶ������һ������ˣ����ǿ��Եó����ۣ����ʱ����ҪԤ����һ���ʣ�����Ҫʲô������Ҫ�IJ��Ǹ���ͳ�ƣ�����Ҫ���Ƕ��⼸ǧ����������������������㡣���ģ�Ͳ�����������Ԥ������ʵ�ȷ��Ҳ����Loss�Ͳ����ܽ������� ѹ�������ܡ�����Illya���껹��OpenAI��ʱ��������ߵĽ�ѵ�����ڿ���Խ��Խ����������ģ��Ϊ����Ԥ����һ���������̬�ѶȵĿ������ø߷֣����������Լ���������Ȩ���������һ������ģ�͡�������ѧ��������������ѧ�������ϵ������ѧ����з����������������ڸ��ӵ��������У����Ǹ�Loss�������¡� ���ԣ�ӿ�ֲ���ħ����ӿ����ģ��Ϊ��͵�����������ĸ�ѹ���㷨�������֣���������Ӳ��ÿһ�仰������ѧ��������仰���������ѧ��������Ԥ����һ���ʾʹӱ��б�����Ƶ����������ν�ĸ������� �����⼸������ѵ����ʱ���и��dz����Ե���С�����Ѳ������ѵ�һ���̶ȣ��������100B������������ϴ���㹻�ɾ��������˴����ĺϳ��������ݣ�Synthetic Data��֮����ᷢ��Loss�������һ������Ĺյ㡣 �ڹյ�֮ǰ��ģ��������ϱ�����ɡ��յ�֮��ģ�ͺ���ͻȻ�����ˣ������������Grokking�������ڵļ���ջ������Ѿ��ܱȽϺõؿ������Grokking������ʱ����ˡ����Ƿ������Ǹ�˲�䣬ģ���ڲ��ĵ�·�������飬����������ͳ�����������������ǵ��������Ƴ���ִ�е�ģ�顣 �ٸ�����ij�����������ȥ�����Ż�һ�����ڴ���ģ��ʱ���������¡� ��ʱ�����ڸ�һ�����ӵIJ��������ݡ����������ҹ�˾��ȥ����ļ�ǧҳ�Ʊ��ͷ������飬������Ԥ���������������DZ�ڵļ�ܷ��յ������ ������õ�������û����ǿ��ѧϰ����ľ�ʱ��ģ�ͣ���Ԥ���������һ���ʣ������Ƿϻ�����������Ԥ�������ط��ɷ�����������͡�Ϊʲô����Ϊ�ڸ����ϣ���仰�����κη���������涼û����Loss�ܵͣ�ģ�ͺܼ�������ѡ���˰�ȫ�ơ� ���ǣ�������������Process Reward Model�����̽���ģ�ͣ���Ҳ������������ϵģ�ͱ����˼ά���ල֮��ǿ�����������˼������ʱ����Ԥ�����һ���ʱ��ˡ�����ʼ������ǵ�A��˾��2025��������ȵķ�¢�Ϸ����¼...�� ע�⣬A��˾����ʵ�Ԥ����ʣ���ԭʼ�ֲ�����ܼ��͡���ģ��ΪʲôҪ���������Ϊ�����ڲ������˼��ٲ�����ʽ��������ģ���˲�������г�ռ���ʼ��㣬�������˼����еķ�¢�Ϸ����ģ���������������һ����ײ���ó��˷��ռ��ߵĽ��ۣ���Ҫ����������ۣ����������A��˾��������ʵ�塣 ���������˵�ĺ��Ĺ۵㣺Ԥ����һ���ʣ�ʵ�������ڶ�δ���������ؿ������������̮���� �㿴���������һ���ʣ���ģ������������֮ǰ���������Ӵ�ĸ�ά�����ռ�������Ѿ�Ԥ���������ֿ����Եķ�֧�����ѡ����һ���������һ���Ե�·�������ڵ�ģ�ͣ��ر��Ǿ���RLHF�����෴��ǿ��ѧϰ����RLAIF��AI����ǿ��ѧϰ���⼸�ִ�ĥ��İ汾������Ԥ��IJ��Ǵʣ�����Ԥ��������Ž��·���� �ܶ�㴫ͳNLP���ˣ������ڻ�ת�����������������N-Gram�ı��֡����ֱ�Ǻ�����N-Gram�ǿ���ȥ�����ʲ���һ���ʣ����ڵ�LLM�ǿ���ȥʮ���Token������������ڲ�����ѹ����ȫ����֪ʶ������һ�����ӵĺ���ӳ�䡣 ���¶����ô�Transformer�ļܹ�˵����˵���ڣ�Transformer�ı��ֲ�����ʲôMamba��Jamba����SSM�ܹ������Ҳռ��һϯ֮�أ���Attention���Ƶĺ��ĵ�λû�䡣Attention��ģ�Ϳ��Կ�Խʱ��ȥѰ��������ϵ�� ������д�����ʱ�����ڵ�100�ж�����һ������user_id���ڵ�2000�е�������ģ����Ԥ���2000�е��Ǹ�tokenʱ��������Ҫ�ӵ�100��һ·��������������Attention����������ֱ�ӿ����Ǹ����塣���ֿ�ʱ�յ�����������������ӿ�ֵĻ�������ѧ���˱���������ѧ���˺�������ջ����Щ���dz���Ա�����ģ�����Ϊ�˰Ѵ��벹ȫ��������������£��Լ�������ġ� �������и��dz�����˼��������In-context Learning��������ѧϰ���ı��ʡ� ��ǰ���Ǿ�����ʾ�ʹ��̣�Prompt Engineering������ѧ����������֪���������ģ��һ��Prompt������ʵ������Inference-time Descent������ʱ�ݶ��½�������Ȼ����û�䣬�����Prompt�ı���Attention�ļ���ģʽ���൱����ʱѵ����һ����ģ�͡� ���Ԥ����һ���ʽ����Ǹ���ƥ�䣬��One-shot����Few-shot�������Ͳ�ͨ��Ϊʲô�ҿ��������Ӿͻ��ˣ���ΪԤ����һ���ʵ�Ŀ�꺯����ǿ��ģ�;߱���Ԫѧϰ��Meta-learning����������������ѧ��ѧϰ���ѧϰ�� ���ٽ���Ӳ��һ��ģ������������ӽǡ� ��Ҷ�֪��Scale is all you need����仰���ڿ������ǶԵģ���Ҫ�ж����Effective Compute is all you need����������ѵ����һ����ģ�ͣ��õ�������Ͳ���������ҳץȡ�������ˡ����ڵĺ��ľ������Ǻϳ����ݣ���ģ���Լ�˼�����̲��������ݡ� ����漰��һ�����������⣺Ϊʲôͨ��Ԥ����һ��token����ѧ����ѧ�� ��ѧ�����Ͻ���������һ������ȫ�̽��䡣���ֻ�Ǹ���ģ�£�����Զѧ������ѧ����֮���������ܽ�����⣬����Ϊ��ѵ������������˴������Ƶ����衣ģ�ͷ��֣�����������Ƶ�ֱ�Ӳ´𰸣�Loss��dz��ߣ���Ϊ���²��ԡ�ֻ�е�������ʵʵ��һ����Ԥ���м䲽�裬��Ϊ...����...��...�������˼ά����������Ԥ����������Ĵ���Ȼ��ˮ�������ˡ� ���ԣ�������Ԥ����һ���ʣ�����Ԥ��˼ά���м�״̬�� ���ڵ�ǰ��ģ�ͣ��ر�����Щרע����������Heavy Reasoning���ļܹ�������ʵ�����������ʽ���ˡ����ڸ���������մ�֮ǰ����̨�����Ѿ����������token��˼ά�����������token��ÿһ������Ԥ����һ���ʡ����Լ����Լ����ۣ��Լ����Լ���bug���Լ��Ʒ��Լ��ļ��裬���Ű��Ǹ�����ǧ����������һ�����¸��㡣 �㿴����������Ԥ�⣿�������˼���� ֻ����������˼������װ�����������ɵĸ�ʽ�������˼����Ҳ���������������������ʱ���ѵ�������һ��������˵�����Ǹ�����Ҳ�����Եģ�Ҳ��һ���ʽ�һ���ʵġ���û��ͬʱ��������ͷ���������ʶ����һ��Token����������Ƕȿ���LLM�ļܹ���ʵ����ط������ܵı��������� ���������Ĵ�����������Ϊ�㷨����ʦ��������Ǹд�����ġ� ����ǰCopilot�ճ�����ʱ��Ҳ���Dz�ȫ��forѭ���������㿴����IDE���AI Agent��ֱ�Ӹ����ع���������ܹ��� Ϊʲô����Ϊ���������ܶ���ߵ��ı���ģ����Ԥ��������һ��tokenʱ�����ܵ���Լ���Ǽ�ǿ�ġ������Ԥ�����һ���ֺţ��������ͱ��������ֱ�����������Ȼ���ڶ���RL���ڼ��룬����Pre-training�δ���Ľṹ�Ա�������ǿ�ල������ģ�Ͷ�����һ���Լ������С� ��֮ǰ��ѵ��һ��ר����CUDA�ں��Ż��Ĵ�ֱģ�͡����ǰ�GitHub�����е�CUDA�����ܴ���ι�����������ֻ�����棬������ѧC++�����ʵ���ϣ���Ϊ��Ԥ���Ǹ�**__syncthreads()**ָ����ֵ�λ�ã�����������GPU���߳�����Warp�����Ȼ��ƣ������������ڴ����ϣ�Memory Barrier���ĸ�� ��Щ�������û�н̿���ֱ�ӹ������������ͨ�����ڴε�Ԥ��ʧ��-����-����Ȩ��ѭ�����Լ��ڸ�ά�ռ������Щ�����ճ����ġ� ���������ѧ�����ġ���ʦ��������ԭ������������ġһ������Ƭ������һ��ʹ��ְ塣������һ����һ�ŵ�ʱ������������Ȼ�ͳ��������ߣ���Ϊֻ�ж����ӣ�������ڲ����ְ������»�����һ�ʡ�LLM�����Ǹ������˼����ڴ��ְ�Ļ��ҡ� ���и�ͦ������Ĺ۵㣬���ڻþ��� �ܶ���ڸ��ģ�ͻ��˵�˵�����ʵ�ڼ�����Ա����þ��ʹ�������ͬԴ�ġ����Ƕ���Ԥ����һ���ʵĸ���Ʒ�� ��ģ�����һ����ȷ������ʵ������ˮ�Ļ�ѧʽ�ǣ���Ԥ��H2O�ĸ��ʽӽ�1�����֪ʶ��ȡ�� ��ģ�����һ�����������⣬�����һ�һ�������������Ԥ��ĸ��ʷֲ���ƽ̹�ģ������졢�������������������ʶ���ࡣ��ʱ������㷨ѡ��һ������д������� ��ģ�����һ����û���������⣬ǿ��ȥԤ�⣬���ѡ��һ�������·������лþ��� ���ڵļ������ƣ������������ڸ��Retrieval-Augmented Generation (RAG) 3.0�������ǻ��ڳ������ģ�Long Context�����Դ��Ż�����ʵ����������ģ����Ԥ����һ����ʱ�������ռ䣬��������ң��������ο��飬������Ϲ�¡� �������ף�������������Ȼ���Ǹ��ġ������ġ������Next Token Prediction�� ��ʱ��ҹ���˾������ŷ����������ĵ�������������Loss logһ����ˢ������Ļ���һ�־�η�С�����������ڼ����֮�飬�����Լ�����꣬��������־������û�п��ܣ����ǵ�������־��Ҳ�������������������Next Token Prediction�� ���ǵĴ�����ʱ�̲���Ԥ����һ��ᷢ��ʲô����·ʱԤ����µĴ��У�����ʱԤ��Է��ķ�Ӧ��������ʱԤ��δ���Ļر�����Ԥ��ƫ��ʱ��Surprise������Ͱ����ڣ���������ģ�͡����Transformer�ķ�����ʲô���������� Ҳ�������ܵı��ʾ��Ƕ�δ����ѹ����Ԥ�⡣ ����2026�꣬�����Ѿ�������2023����������LLMäĿ��ݻ���äĿ�־��ˡ����ǰ������ɹ��ߣ�����һ�����͵ļ���ԭ� �����ڵ��ֻ�����ϵͳ��ײ���ܾ�����һ��3B��Сģ�ͣ�ר�Ÿ���Ԥ������һ��Ҫ���ĸ�App���Ӷ���ǰԤ���ء��ⲻҲ��Ԥ����һ��Token�ĸ�Ӧ���� ���ԣ��ص�������⡣Ϊʲô��Ԥ����һ���ʾ���ӿ�ָ������� ��Ϊ���ǵ����汾����������ġ���ȥ����δ������������������������еĹ�ȥ������Ԥ��δ������ͱ������տ������������ת�����з��� ��ģ�ͻ�û���������з�����ͨ��Ԥ����һ����������취���Ѿ���������������˼ά���ż���������Ҫ������ֻ��Ҫ����һ��ȥԤ�⡣������Ԥ����㹻����ʱ�������֮��Ľ��ޣ����Ѿ�ģ���ˡ� �����Ϊʲô���������������ҵ�Խ��Խ��̸���㷨��Խ��Խ��̸�����ݺ���������Ϊ�㷨�������Ѿ����������������ˣ�Next Token Prediction����ͨ��AGI�����·��������Ŀǰ���������� �������������ʱ��ڵ㻹��AI�ײ�ԭ������Ȥ������һ�����顣����Щ���ڵ�������ס�ˡ�ȥ����ԭʼ��Attention is All You Need��ȥ����Andrej Karpathy����Ľ��⣬������2026������ڣ���Щ����ֱ����Ȼ����Ӳ�˵ġ� �����ڱ䣬�ܹ��ڱ䣬������Transformer���ܶ��ᱻ�������ͨ��ѹ��������Ԥ��δ�����Ӷ���ȡ���������ʽ��ֻҪ��ũ����Ϣ�۲��������ƻ���ͳ�����Ǻܳ�һ��ʱ�䡣 ���л���ˣ�Խ��Խ���ã��������Ԥ����һ���ʣ������Ǹ����� ϣ���ⷬ����������а������п����ġ� ������ |

|
|
[img_log] |

|
|
3 ���������� |
|
ǰ����д��һ�� LLM �������Դ�Ŀ������£���������һ�������ǣ� Ϊʲô LLM �ظ���Ԥ����һ���ʡ�������裬�Ϳ���ʹ����������ı��������ͨ˳�ģ������ܱ�����һ���ԣ�����Ϊ����߶ȸ��ӵĺ��������߱������Ĺ����ԣ��ڽ������������������������ԣ�һ������������ �������dz��ã�Ҳ�������ǵ�ֱ����Ϊʲôһ����ˡ����ӡ���Ŀ�꣨Ԥ����ڵ���һ���ʣ����ܹ�������һ���߱���Զ��������������ϵͳ�� ����ģ��ÿһ��������һ���ֲ����Ž⣬�����ս��ȴչ�ֳ�ȫ�ֵ������ԡ����Ժʹ����ԡ���ȷʵ�������������������Ե�����֮һ�� �������Ŀǰ��û�зdz�ȷ�еĴ𰸣�����˵���Ƕ� LLM �ɽ����Ե�̽����������һ�����������Dz���һ���������������������������һ�µ�ǰ��һЩ���������� ȫ�������ĵĹ�����ģ���������ÿһ������������ȫ����ʷ�ģ��������Ǵ��Եļ�������к���ͬ��Ԥ��������Ĺ�ϵ��Ϊʲô��Ԥ�⡹���Ŀ�����ʹģ��ȥ�����⡹����ģʽƥ�䵽��ʱѧϰ������ͷ��Induction Heads������ι����ģ�����ģ�͡���һ������������ȫ��������ӿ�ֵı��ʣ�������ӿ�֣�Emergence��������ν��ͣ�Ϊʲô�����ģ�;���ʵ�����ַ����Ե�������Ծ��һ��ģ����ο˷���������䡹�� ���ȣ�ģ���ܹ����ֳ����ָ������Ļ���������Ҫ�ܳ�����������ġ�Ҳ����˵��Ҫ��֤����Ԥ���ʱ�����е���Ϣ�ܹ����ο���������ȷ����ͺñȲμ�һ���������ԣ������ɰ��������ؼ���Ҫ�㣺��һ�㣬�ñ�֤��������������ϣ����Իش�������������Ŀ���ڶ��㣬����Ҫ�������ڿ��Ե�ʱ���Ч�ز�����Щ���ϡ� ������ȱһ���ɣ������Ӱ�졣���ϴ��IJ������ɸ���Ϊ����֮���������˹�������ϣ��ֻ�Ӵ��ֳ����ĵ��Ѷȡ�Ŀǰ������ LLM ������ Transformer �ܹ���������ע������Self-Attention�����ƽ���ģ���ʵ������ôһ������������ + ��Ч��ѯ���ĺ������⡣ ���ڵ� Seq2Seq �����Ȱ�������ѹ����һ���̶���С���м������У��൱�����������������һ��д��С���� A4 ֽ�������������д����С������ֽ�Ĵ�С�������ģ���Ϣ������ġ���ע������Attention�����ƣ����ǰ������е�ԭʼ���϶������˿�����������Щ���Ͻ����˸�Ч���������Ӷ���ģ����ÿһ��Ԥ��ʱ�����ܶ�̬�ػ�ͷ����ԭʼ���ϡ� ������˵��ÿ������� token ��������������������ѯ��Q��������K����ֵ��V����Q �������ʣ���������Ҫʲô��Ϣ�� K �� V �������Ͽ��е����������ݡ���ģ�ʹ���һ���´�ʱ�������� Q ȥ�����оɴʵ� K ��ƥ�䣨����������ƶȣ������ƶ�Խ�ߣ�˵���Dz��־���ϢԽ��أ�Ȼ������Щƥ�䵽��Ȩ��ȥ��Ȩ��Ͷ�Ӧ�� V���Ӷ��õ�һ�������ļ�ȨժҪ�� ���ֻ�����ģ�;߱��ˡ�������ݡ��������������ϣ�ֻҪ�����ij��ȹ������Ϳ�����Ԥ��ʱ�ο�ǰ������λ�õ���Ϣ�����仰˵��ģ�͵ġ����䡹��������һ��ƿ��ʽ���м�״̬�������Լ�����ʵķ�ʽ��compute-as-memory�� ��ʵ�ּ���ĵ��á� ��Ȼ�����ּ��䷽ʽ��Ȼ�˷������� RNN/Seq2Seq �Ľ���������⣬��Ҳ�������µ���ս������ʹ洢�������������ij��ȳ�ƽ����������ģ����Ȼ�ܿ��á�Զ����������Ҳ��ø߰�����ˣ������о���ʼ̽������ڲ���ʧ��Ҫ��Ϣ��ǰ���£�ѹ����ϡ�軯��ṹ��ע����ģʽ�������ⳬ����������ƪ���µ����⣬�ݲ�չ���� ��������ֻ��Ҫ���⣺Transformer ��������ÿһ��������һ������ȫ����Ϣ�ġ���̬�������ı�ʾ�� |

|
|
��չ�Ķ��� [1409.0473] Neural Machine Translation by Jointly Learning to Align and Translate[1706.03762] Attention Is All You Need����Ԥ�⼴�����⣿ �����ϣ�LLM ��ѵ��Ŀ�꼫�䵥��������ǰ�ģ�Ԥ����һ���ʵĸ���������������Ȼѵ����MLE������ֻ��ͳ��ѧϰ�����ϵġ�����ı��ֲ���������չ�ֳ��ĸ���һ��Ľ��ȴ���˾��ȡ� ���Ӵ�����Ϸֲ��£����������ƥ��ģʽ������Ч���Ԥ��ȷ�ʵġ�ģ��Ҫ���ڲ�ͬ�ᄈ����ͬ���ͬ�����¶������ɺ����Ĵ���ͱ����������������ı���������ɻ��ơ���Ҳ�����������������̺�������ṹ�������ϵ����ɫ��ͼ���������� ���ǣ�ģ�͵��Ż����̱����ϳ�Ϊһ���ල���㷨���֡������ڷ���������С��Ԥ�����ʱ���ݶ��½��ͼܹ�����ƫ�ã�Inductive Bias������Ȼ�ƶ������γ�һϵ���ڲ�����ģʽ����Щģʽ������ʽ��̳����Ĺ����Ǵ�Ԥ�������С�ӿ�֡�����Ч���ԡ� �ټ������͵����ӣ� Ϊ��Ԥ����һ��Ի��ظ���ģ�ͱ�����ʽ��ģ�Ի�˫����������ͼ������״̬��Ϊ�����ɺ�����������£�ģ�ͻ�ѧϰ���¼�֮�����˳����������ϵ��Ϊ���ڴ���������Ԥ����һ�� token������Ҫ���ճ������������������������Ϊ��ѹ�����Եĸ�ά�ֲ���ģ���ڲ������γ������νṹ���Ա��ø���ά�ij������߲��������ɡ� ��Щ���������ij��ֲ�����Ϊ��ƵĹ���ģ�飬�����Ż����̵ĸ��������Ϣ�۽Ƕȿ��������Ȼѵ����ʹģ������������ȥ�ƽ��Ӵ�����ӵ���Ȼ���Էֲ������ŵ�ѹ����ʽ��ǡǡ��ȥ�����������ɵĵײ���ɡ����ǣ�����ģ�Ͳ�ֻ��ѧ�ᡸ˵����������ѧ�����������������˼�����̡� �������ҵ�о�����˵�ġ�ӿ�֡���Emergence������ģ��ģ��ѵ�����ݴﵽijһ�ٽ���ԭ�������ڵĸ�����Ϊ�������������������ಽ�滮����ͻȻ���֡����仰˵��Ԥ���������Ż����㹻���ӵ�ϵͳ�У����Է�ʵ�����������ļ��㡣 �������ڶ���������Ľ��ͻ��dz������ƣ�����Ҳ�в������ɵ���������ʱ������ֻ�ܱȽ���ͳ����Ϊ��LLM �ɱ�����һ�֡�ͨ��Ԥ��ѧϰ���硹��ϵͳ���������ܣ����������ⲿ�ල�Ĺ��䣬���������Ż������ж�����ṹ��ѹ�����������ؽ�����Ԥ���Խ�ã�Ҳ�͡����⡹��Խ� |
|
|
��չ�Ķ��� [2206.07682] Emergent Abilities of Large Language Models[2304.15004] Are Emergent Abilities of Large Language Models a Mirage?������֪ / ��ѧ������ ��Ȥ���ǣ���������ģ�ͣ�LLM�����ڡ�Ԥ����һ���ʡ���ѧϰ���ƣ���������������������еĹ�����ʽ����һЩ�����ԡ�Խ��Խ�����֪��ѧ�������о�ָ�������Բ��DZ���������Ϣ�������ڳ����ؽ���Ԥ�⡣��һ���ۿ�ܱ���Ϊ Ԥ����루Predictive Coding���� ����Ԥ�����ģ�ͣ�����ĸ�֪��������Ա�����һ�ֲַ�Ԥ��CУ�����̣��߲���������ھ��������������ɶ������Ԥ�⣬���Ͳ�й��ź��Ϸ���Ԥ����prediction error�������Ե�ѧϰĿ�꣬���Dz�����С������Ԥ���������� LLM �������Ȼ�Ż�����ʽ�ϸ߶����ơ� �������������ֲ㼶Ԥ��ṹ���ֵ���Ϊ���ԡ�����������һ�仰ʱ����ϵͳ�����ǵȵ���ĩ��������˼��������ÿ���ʳ���ʱ���ͻ���������Ķ�̬��Ԥ����һ�����ܵĴʻ㡢�������ṹ��һЩ�о�ͨ���Գ���Աȷ��֣��������Ķ�����ʱ�����������������������ǰ��Ҷ���Ҷ���м����ģʽ���� Transformer ģ����Ԥ����һ�� token ʱ�ļ���ֲ���������Ӧ��ϵ��������������������Դ���ʱͬ���γ���һ�ֲ�λ�Ԥ����ϵ�����Ͳ�Ԥ��������ʻ㣬�в�Ԥ��䷨�����ṹ���߲���Ԥ���������������� ���������Բ�����ζ�� LLM ���Ǵ��Եĸ���Ʒ�������ṩ��һ����Ҫ������Ԥ��������Ȼ���յ�ϵͳѧϰ���ṹ��������ģ�͡���������ϵͳ����������磬��һ��ϵͳ��Ҫ���Ч�ؼ���Ԥ�����ʱ������Ȼ��ȥ������Щ����ý�������仯���м��ʾ��������ǽṹ��������������㼶�����Է�ӿ�ֵĸ�Դ�� ���ֿ�����ĺ�ӦҲΪ�����ṩ��һ������۵��ӽǣ�Ҳ�������ܡ��ı��ʣ��������������Ķѵ�����������״̬�ij���Ԥ���������С���� ��չ�Ķ��� Evidence of a predictive coding hierarchy in the human brain listening to speech | Nature Human Behaviour �ġ�������ѧϰ LLM��ӿ�֡����������˾��ȵ�����֮һ���������ܹ��ڲ����κβ����������ѧϰ������ ֻҪ����ʾ��prompt���и����������ӻ�һ��˵����ģ�;�������ģ�³���Ӧ��ģʽ����������ⷽʽ������������ν�� ������ѧϰ��In-Context Learning���� ��һ������ʵ��ģ��������ʱ����������ѵ����ϰ�õ�Ԥ����ԡ��������Ȼѵ���Σ�ģ�ͼ���������ʽ��������� - ����ԣ�������𰸡���������д�����������������ˣ�������ѧ����������ʶ����ģʽ������������ʾ���ṩ��ʾ�� + ���⡹ʱ��ģ�;ͻ��������һ���������ı���������Ψһ��Ŀ����Ȼ��Ԥ����һ�� token����Ϊ����С��Ԥ����ģ�ͻ���Ȼ�ذ�ǰ���ʾ���ܽ��һ�֡�����������Ӧ�õ��µ������ϡ� ���ֻ��Ƶĺ������� Transformer ��ע�����ṹ��Anthropic ��һЩ�о��߷��֣�ģ���ڲ������˱���Ϊ ����ͷ��Induction Head�� ��ע������·����Щע����ͷ�ܹ����������ҵ����Ƶ��Ӵ�ģʽ��������������֮���������ʾ�ʣ������ѵڶ����������һ���𰸽������Ӧ��ϵ�� ��ʹ��ģ���ڴ�����������few-shot����ʾʱ���ܹ������������г��ֵ�ӳ���ϵ�����ɷ���ͬһ������´𰸡����仰˵��ģ��������ʱ�������ĵ��������һ������ִ�С� �ٸ�ֱ�۵����ӣ�����ʾ�г��ּ��顸Ӣ�� -> ���ġ��ķ���ʾ��ʱ��ģ�ͻ�ѧ������֡�ӳ����ɡ���ȡ������������һ������ʱֱ��Ӧ�á��ⲻ����Ϊģ�͡�������⡹�����ģ�������Ϊ������������ʶ���һ��ͳ�ƿɸ��õ�ģʽ����������㸴����һģʽ�� ������˼���ǣ����ֻ��Ʋ���������������������ģ��ģ����������ѧϰ�ܹ�����Խ��Խ���ӵ�ģʽ�����������㡢�����������ಽ������������һ����ʱ�Ľ������������������С����롹�������ִ�С������ ��ʹ����ʾ���̣�Prompt Engineering�������ij�ֶ�̬��̽ӿڡ���������ͨ�����������ģ�������ģ���ڲ��IJ�����ǰ��������¹��ܡ������������Ա�����Ԥ�ⷶʽ��һ���ʱ䣺 ģ�Ͳ���ֻ�DZ�����Ԥ����һ���ʣ�������ÿ��Ԥ��ǰ�����������������й���һ��С������ģ�͡������Լ���ע������������ʱѧϰ�����ɺ�ִ�У����֡���ʱѧϰ�����Ǵ�ģ�����ܵij��Ρ� ��Ȼ��Induction Head Ҳֻ������Ŀǰ�� ICL ����ı�ɽһ�ǡ������ӵĻ��ƻ���Ҫ������ھ� |
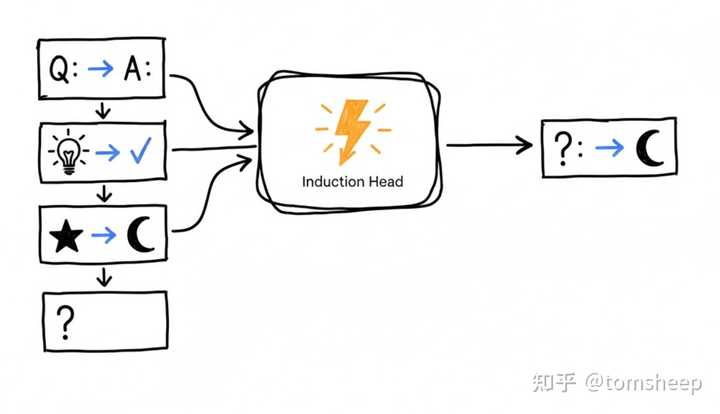
|
|
��չ�Ķ��� [2209.11895] In-context Learning and Induction Heads[2212.07677] Transformers learn in-context by gradient descent[2402.15607] How Do Nonlinear Transformers Learn and Generalize in In-Context Learning?�塢NTP Ҳ����ȱ�� ����Ԥ����һ�ʣ�NTP�������ּ���ģʽȡ���˾�ɹ���������ǿ�����ǣ����������ij��֣�������ζ��ģ�͵ĺ�����ʽ��Ȼ��֤��һ�»���ʵ��ȷ�� LLM �ı��ʣ���Ȼ��һ����ѵ������С����һ����Ԥ�����ĸ��ʷֲ�������������ÿһ��������������ض��������´Ӹ��ʷֲ��г����Ľ��������������һ���ⲿ�ġ������ж�������Լ�������Ƿ���������仰˵��ģ������ġ���Ǣ�ԡ��롸ȷ�ԡ�ֻ��ͳ�������ϵ��������������ϵı�Ȼ�� ����ѵ�����ݵIJ����⡢��ʾ��ǵ�ϸ����Լ��������Ե�����ԣ�ģ�Ϳ����ڲ�ͬ������������ȫ�෴�Ľ��ۡ���֮���Գ����Եá�������������Ϊ��ϰ���Եظ�����ѵ�������е����ýṹ��֪ʶģʽ�� ��һ����ʾ�����˷ֲ�����Ϥ����ģ�͵ġ�Ԥ�������ͻ�Ѹ���˻����������ŵ�������������ĺ��ࡣ�����ɵ�����������������ʽ���ع�����һ�ֿ��ƺ�����ʵ��Ϊ���Ԥ���������γɵġ�α�㷨���� һЩ�о�Ҳָ�������ַ�ʽ�������ھ��ޣ�LLM ���Ż�Ŀ��ֻ���ľ��ӵ�ͳ�������ԣ����������������α��ֻҪ��������������ȷ�𰸡��ľ�ʽ�����Ԥ����ʣ����ͻᱻ�ݶ�ǿ��������ζ��ģ�͵ġ�֪ʶ����ʵ��һ��Ԥ��ƫ�ã�predictive bias�������������������������� ��ˣ�ģ�Ͳ����ᡸ��֤�����⡹���෴��������������ı�Եά��ƽ�⣺�����ʾ�㹻�������������㹻�ȶ������ܱ���һ���ԣ���һ�������ĺ���������յ��ԣ����Ϳ������ɳ�������ȫ�෴�����ݡ� ����ڱ������������Ե�ͬʱ��Ϊģ���������֤����У�����������ƣ�Ҳ��һ���dz���Ծ���о����� |

|
|
��չ�Ķ��� [2403.06963] The pitfalls of next-token predictionThe Surprising Power of Next Word Prediction: Large Language Models Explained, Part 1 | Center for Security and Emerging Technology�ܽῴ�ƶ��ӵġ���һ��Ԥ�⡹֮������������Զ���븴���������ؼ�������ע����Ϊģ���ṩ��ȫ�ֿɷõ������������Ȼѵ���ƶ�ģ����ѹ�������ķ�ʽ�ƽ�����������ṹ������ѧϰ����ģ��������ʱ��ʱ���ɲ����ù���ģ�����ݿ��ijЩ��ֵ����Щ���ƻ���ӳ������Ե�����������������LLM ���Ǹ���ƥ��������������ȷֻ��һ��ͳ�������������Ȼ�������Ҫ�Լ��������ߡ����̼ල�����ѵ���ȷ�������Լ���� ������ ��û�������������һ�����߰� |
|
1. ������ Next One��ʵ���� Next N ��Ȼ Pre-training �� Loss ����Ե�ǰ Token ���㣬��Ϊ��ʵ�־�Ԥ�⣬ģ�͵� Hidden States ���������Ժ������ݵĹ滮����������䣬���µIJ�����ֻ��ת�������̣���������ʵ�Ѿ�Ԥ����δ����ʮ�Ĺ켣�� �ӻ����Ͽ������� Next Two ʱ����ʷ�Ĵ� KV Cache ʵ�������� Next One �ξ���ȷ��������ζ����Ȼ�������������ɣ����ڲ������Ѿ�Ϊ������������������ ��һ���� Post-Training ����Ϊ���ԣ�RL �� Reward �ǻ��������� Token List���������ɽ���������ġ�����������ս���ķ�������һ��ǿ��ģ�������ɵ�ǰ Token ʱ������߱���δ����ȫ�ֹ滮������ Next One�Ƕ����ռ䣬Next N�ǽ���ά�ȡ� 2. GPT��NTP��һ����Ч���ı�������������������������ʽ ��GPT��һ���������BERT�����ܿ��������������ʡ��ڲ�������������ڣ�GPT��BERT�ֱ����������ģ�ͺ�����ģ�ͣ�����ͬ�����������£�GPT��casual attention��������������ȫ����BERT��full attention�� �������Ų��������ݵ�Scaling Up��ӭ����GPT-3ʱ�̣����ɺ���������ͳһ��ԶԶ��Խ��BERT�� �Ҿ��ð������㣺 GPT�Իع����ƣ�casual attention+next token prediction���ܷdz���Ч������Ԥ����ÿһ��token��ΪTransformer�ṩѵ���ݶȣ�BERT�ġ�������ա������Ԥ������Ч�ʿ���ֻ�в���20%��GPT����ƣ��ʺϸ�Ч�ضԽ����е��ı����ϣ���������Scaling Up����������ģ�͡����������������ѣ�Scaling Limit���ߣ�����ͨ�������ɡ������ˡ����⡱��ʵ�������ɺ������ͳһ�ͳ�Խ�� ������ˣ������⡱���ǡ����Ͷ����������ɡ����ǡ�˵��д��������ѧϰ��������Ϊ���������Ч��ѧϰ����֮һ�������������ǡ�����㲻�ܼذ�һ��֪ʶ����������Ǿ�˵���㻹û���������������� Ϊ���ܽ�������������������������������ġ����ɡ����������⡱�����ӡ� ������������������ʽ���� ֻ�е�ģ�ͽ�����һ���㹻���Ƶ�����ģ�ͣ��������ڸ��ʿռ���̮�����Ǹ�Ψһ��ȷ��Next Token�� �ٶԱ�T5������Encoder+Decoder��ɣ���NMT��Neural Machine Translation��������Ҳ��ʾ����Scaling Law�������������ϵ� cross-entropy loss Ҳ��ģ�� / ���ݳ������½�����ϸ�µ�Scaling Law�о��ֱ�ȡ�Ŵ�Encoder��Decoder�����������Ŵ� Encoder �� Decoder������б�ʺ����ŵ㶼��һ����һ���Ƕ�� Decoder ���������㣬Encoder ��̫����������ݼ���Ҳ����˵Scaling�Ǹ���Next One���ɵIJ����������㣡�ٴ�˵���ˣ���������������ģ�������������ʽ������T5��Ϊ���Ÿ�Encoder��LMģ�͵Ĺ������ۣ������Բ����ʺ���Ϊͨ��ģ�͵ļܹ��� ���Ӿ��������������ɳ�������������ȫ��ͬ����ϵ������ģ�Ͷ��� ViT �����Լල����Ϊ��������ģ������ Diffusion Ϊ���ģ�����������ṹ��ѵ��Ŀ���϶���ͳһ������ NLP �γ������Աȡ���GPT ֻƾһ���� Next Token Prediction ��ͬʱ�Ƴ������������������������Ź�ģ��չ��ǿͨ�����ܡ� Ŀǰ CV Ҳ��Ѱ�ҡ��Ӿ��� NTP�������� Masked Image Modeling���Իع�ʽ�Ӿ� token ���ɡ���ģ̬ͳһ��ģ���Լ� Transformer ������ɢģ�͵ȷ����ڳ�����һ��ͨ�ÿ��ͬʱ������������ɡ���������û�г���һ���� NTP �������š���Ч���ɴ��ģ��չ�ĵ�һ���� 3. ��ν�ġ�ӿ�֡��������Dz���ָ�겻��ƽ�������Ĵ��� ������һ��С����������ͻȻ�����ˣ�ͻȻ��˵���ˣ��������ļ�����������������������ƽ����չ�ģ�ֻ���������������ǿ����յ��Ǹ��߳��ĵ�һ����˵���ĵ�һ�仰�� ��ģ��Ҳ��һ����Loss һֱ�ڽ�������һֱ���ǣ�����ָ��ȴ������ģ������ӿ�֡��ˡ� ���������о�֤�ݣ�˹̹����ѧ�Ŷ��� NeurIPS 2023 ���������� ��Are Emergent Abilities of Large Language Models a Mirage����ϸ��֤����һ�㡣 �о����֣���ν�ġ�ӿ�����ߡ���ȫȡ��������ʲô����ȥ���� ���ʹ�� Exact Match����ȫƥ�䣬�Դ� 0/1 �֣����ַ�����ָ�꣬�ͻῴ�����͵ġ�ӿ�֡���һ������ Token Edit Distance �� Brier Score ����ƽ��������ָ�꣬�������͵�����˲��ͱ�ƽ�ˣ�ģ�͵�������ʵ�����Ź�ģ���������ġ� ��Ȼ�������˵�����Ҿ��û��Ǵ��ɣ��Ƿ����ӿ�֣���ӿ�ֱ���Ļ��ơ� �Ա�ӿ�֣�Emergence�����������ֵ������Ƕ���Grokking���� ӿ�֣�Emergence���Ͷ���Grokking��ʱ���ᱻ��죬����ϸ����֣�Grokking ���Ա���Ϊһ�֡�ʱ��ά�ȡ��ϵ�ӿ�֡� Emergence (ӿ��): ͨ��ָ����ģ��ģ�������������������������ͻȻ���֡�Grokking (����): ͨ��ָ����ѵ��ʱ�䣨�������䳤����������ͻȻ���֡� ������ֽ���̫�����ˣ�������Լ�Ҳû��˳��������ľ�ɾ���ˡ����п����� |
|
|
| [�ղر���] �����ر��ġ� |
| �Ƽ� �������� |
| Starlink Ϊʲô����ͨ�� |
| �������¸�������վ���������浹�գ��ֽ� |
| MiniMax ��ʼ���ƿ�������ʵ�� AGI ǰ������ |
| ƻ����ʼ�����й���ҵ���δ洢�ڴ�оƬ���� |
| ��ο�����һ���ֳ��Թ� 10 ��token �·� 2 |
| DeepSeek V4 ��ʽ�潫�� 7 ����Ѯ���ߣ����� |
| ƴ�����˿��Ŵ����ԵĶ�ô�� |
| ��ο���Ԥ���г�Polymarket������һ����20 |
| ʹ��ƴ����������Σ� |
| Ϊʲô����������ô��Ҫ�� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
|
��������:
��ӰƱ��
����Ȧ
����
����
����
�����
ӡ��
�ɼ�
��س
����
��ˮ
��Ǯ�ҽ���ר��
����
˫ɫ��
����ĸ��
����
ƹ����
�й�Ů��
����
nba
�г�
�ܲ�
����
���
��ɫ
�Ϻ��п�
80��
����: ���� �����ֶ� ������ķ�ȴ� �ʼ������� ����ͼ˹ ���� ����� ���� �ﰺ ����ʥ�ն��� ���� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ֪ʶ�� |