| |
|
|
|
| 知识库 -> 科技 -> 如何看待田渊栋年终总结中对离职 Meta 经历的回顾及对 AI 的思考? -> 正文阅读 |
|
|
[科技]如何看待田渊栋年终总结中对离职 Meta 经历的回顾及对 AI 的思考? |
| [收藏本文] 【下载本文】 |
|
1月4日,前Meta FAIR团队研究总监田渊栋在知乎发布的个人年终总结中,回顾了过去一年其在Meta经历的组织震荡与被迫离职的经历,并透露个人新的就… |
|
看完这篇文章,心有戚戚焉。 今年深度用AI写代码,基本也是10w+级别的入库量。去年这个时候我还觉得AI就是个花活,仅限于文件级别,偶尔写写脚本。结果今年呢?我已经习惯开着好几个CC窗口同时干活了,它写的代码也懒得去细看,只看整体架构、边界接口是否OK。 而且基本更多地去prompt AI,而不是prompt同事。已经事实上个是一个one man company了。 说几点我自己想明白的事吧。 一、未来真正值钱的不是你会什么,而是你想要什么。 遍地神灯的说法很有意思,罗振宇也讲过类似的观点――愿力。 今年想法到实现,路径大大缩短。创造的快感太过于强烈,多巴胺奖励太过密集。 很多想法都是立竿见影的落地,然后大脑里还有一堆idea排着队嗷嗷待哺。 每天不是在电脑前指挥AI,就是在走路洗澡时自己反思,想不明白就拿起手机问一嘴gemini怎么看。AI已经事实上是我的外置推理大脑了。 二,你的认知,决定了你能不能跨过那条线。 费米能级的比喻特别形象。 套用一句流行语,你赚不到认知范围以外的钱。同样地,你只能用AI达到你认知范围以内的水平。 用AI的天花板被认知锁死了。 今年跟朋友交流,大部分人用AI,基本都是烧火棍,只有极少数会用AI的,AI是金箍棒。而且都是在适应这个外星工具,自己去探索这个工具的边界。而且金箍棒的这帮人很少交流,也就Karpathy会发推分享下。 大部分链接来自线下,真是金箍棒线下交流群。这帮人有个共同点:特别擅长跨界。他们能把完全不相关的东西串起来。所以今年很多搞计算机的,都去看脑科学、认知学、心理学、生物学。 所以别只在自己的专业领域里打转。先熟悉自己领域的复杂系统,然后去跨界学习别的领域。大脑的节点多一些、连接密一些。哪天某个灵感突然把两个八竿子打不着的东西串起来了,那可能就是你的护城河。 三,要及其注重critical thinking,不然你会被AI同化成一个空壳。 这点我感受特别深。 田老师文章里也说,AI在快速让人技能退化,这一点Anthropic的洞察报告里也有提到:用好AI的前提是人技能很强,而用多了技能就退化了。 AI生成的东西有个特点,就是特别正确、特别平滑、特别共识。但人的价值恰恰在于能跳出共识,能说出那些反直觉的话。 所以我现在强迫自己:每次看AI的输出,必须挑战它,要强迫自己脑子转起来。强制自己大脑出在我知道{我知道|我不知道},而不是我不知道{我知道|我不知道} 元认知要时刻保持在线,随时跳出来求梯度,不能迷迷糊糊地AI绑架了。 最后说点感性的。 我最近经常想一个问题:我的愿望是什么? 以前觉得这问题太虚了,实现愿望代价很大,先工作赚钱再说。但现在发现,如果你不想明白这个问题,人就跟AI无异了。 但如果你有一个真正想做的事,一个哪怕没人给你发工资你也愿意干的事,那AI对你来说就不是威胁,而是工具。 与其焦虑被取代,不如想清楚自己到底想要什么。 发挥自己的主观能动性,在洪水来临的大时代,乘风破浪吧。 |
|
作为一个完整享受过时代红利,然后即将被时代淘汰的普通AI工程师,来说说自己的感受。 大概从2009年百度推出凤巢系统开始,机器学习成了工业界的香饽饽。2012年AlexNet诞生,直到2019年,机器学习成了市场上最好就业的方向之一。庞大的工作岗位,新奇有趣的工作内容,超高的薪资,使得算法工程师成了最理想的职业。那时候,只要你学历优秀,都能通过快速的自学拿到offer。华为、阿里和腾讯甚至招了很多数学和物理top博士,开着极其优渥的薪资,来做算法研究员。 李航老师的《统计学习方法》作为一本学术专著,本应受众极其有限,却和《5.3高考》一样人尽皆知。一个985硕士,300道leetcode加这本书的全文背诵,再吃透几篇检测的最新论文,成了中大厂的入职捷径(现在不可能了)。吴恩达、李飞飞、李沐、汤晓欧、孙剑等学术大牛,也成了中文互联网上的“知名网红”,其中翘楚者,是MIT的何恺明老师。 然而,随着以CV和NLP为核心的AI1.0时代破灭,大量研究院和AI初创公司灰飞烟灭。就业岗位的急剧缩减,让能参加NIPS的美国机器学习名校博士,也对自己暗淡无光的前途忧心忡忡。以LLM和AIGC为核心的AI2.0兴起,实事求是地讲,已经远远不能提供相对于1.0时代那样巨量的就业机会。 江山代有才人出。研究agent的大牛姚顺雨意气风发地畅谈AI的“下半场”,何恺明、刘壮甚至朱泽园这些上个时代的天才,只能回归高校实现平安落地。 由来只有新人笑,有谁听到旧人哭。工业界从来都是冷酷无情,年轻时在风口上,并且有强悍的即时战力,能享受无限风光;但是年龄大了,丧失了快速学习和极速产出的生理条件,大部分人也只能坦然接受降薪和裁员。 田渊栋博士被裁,是一个单独且特殊的事件,更多是政治斗争因素。以他的资历和能力,更多更高的offer等着他回复。而我,不会惊艳于AI带来的科技进步,只会在意自己的岗位能否保住,能否有更多的就业机会。 田渊栋博士有这么多offer,他仍然选择了创业,也应该是看透了,只有资本和权力是永恒的,技术都是短期、暂时的。这是难能可贵的。毕竟,很多做技术的行业同仁,都是短视、自负的,在被裁之前,都坚持认为自己属于不会被裁的那一批。 |
|
年终总结就是打工人的损失函数(Loss Function)。 干AI这行的都知道损失函数,神经元网络模型训练,根据输入数据X算出预测结果Y_Pred,和实际的结果Y的对比方式,这个方式就是损失函数Loss,也就是说: Loss = J (Y\_Pred, Y) Loss越大,越痛 Loss可以判断模型是准还是不准,因为Loss越大,表示Y_Pred和Y之间的差距越大。 |
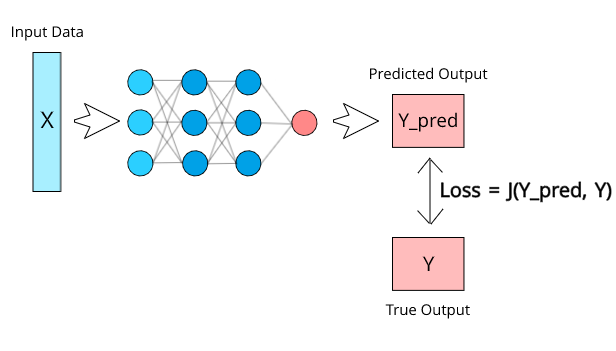
|
|
损失函数(Loss Function) 对应于人生,也就是现实和预想差距越大,越痛苦。 田渊栋展示了可以用年终总结判断人生决策是准还是不准,也展示了预想和现实的差距带来的剧痛。 在年终总结中,田渊栋说到自己被要求给Llama4救火的时候,还花了一个2x2回报矩阵,呵呵,不愧是做AI的专业人士,思维方式非常符合机器学习的脉络。 其实,所有活人(除非是植物人)都是根据回报预期来决策的,只不过大部分行动只是潜意识行为,田渊栋只不过把这种决策过程更明显清晰地表示出来而已。 |
|
|
我想,田渊栋现在也意识到,这样的回报矩阵虽然明显清晰,但是容易只陷入只枚举自己预测到的结果,即便结果未知,那也是『已知的未知』(Known Unknown),而现实世界有很多的『不可知的未知』(Unknonwn Unknown)。 这就让他撞上了,最后的结果是Unknown Unkoown,回报矩阵知外的第五种可能,第五种可能是啥,看他那一小节的标题就知道了――被裁了。 没想到自己一腔热血,最后还要被当成替罪羊。 对田渊栋来说,他本来对2025有预期Y_Pred,而实际结果Y和Y_Pred的偏差很大,这个Loss函数结果也很大,当Loss较小,模型这轮训练只需要微调;当Loss很大,模型这轮训练的权重修改就应该大一些了。 Loss越痛,改变越大。 现在田渊栋从打工人改为自主创业,就是发现Loss函数很大,人生路线要做重大调整。 不过,我觉得还有一个人需要好好修正一下自己的Loss函数。 谁最应该修正自己的Loss函数? 这个人就是田渊栋以前的老板、Meta的CEO马克扎克伯格。 |

|
|
对马扎来说,其实过去几年应该遭受了不少Y_Pred和Y之间差距的重击。 几年前押重注到元宇宙,甚至公司名都从Facebook改成Meta,结果元宇宙黄了,这事可不能只怪时运不济,而是鲁莽的赌博,但凡算一下支持元宇宙世界的电量就知道距离真正元宇宙元年还早。 大模型起步得晚,好歹搞出Llama算是Meta这几年难得的高光时刻,但是起个大早赶个晚集,顶着第一开源大模型的帽子出道,现在开源大模型领域却被中国大模型统治。 如果说Llama没搞好,只能怪技术团队执行得不好,不能怪马扎领导得好,那么,几次AI方面的收购就看得出马扎没从Loss中学到什么。 收购Scale.AI是图个啥?看不懂,数据标注并没有给Meta带来AI的优势,也没让Meta能卡其他竞争对手的脖子,图个啥? 让Alex Wang管理整个AI部门,依据是什么?Alex Wang肯定属于顶级聪明的人,但是聪明不能取代经验,他的经验是管理数据标注的血汗工厂,真能管理好一群技术精英吗? 收购Manus是图个啥?当然,得要恭喜Manus,毕竟对一个创业团队来说被高价收购是好事,但是,从Meta角度来看,Manus对Meta的AI布局有什么意义?Manus没有自身自己的模型,也没有任何技术和商业壁垒,甚至只支持Meta竞争对手Anthropic的模型,Meta收进来干啥? 过去几年,Meta有这么多Y_Pred和Y的巨大差异,马扎就是没从Loss总学到什么。 当然,最让人不理解的就是马扎对Meta的AI部门的『整顿』,去年田渊栋在X上就发帖透露: 真正应该负责解决问题的人并不是被裁员的人 这句话细思极恐,有一些人不应该承担责任的被裁了,而那些真正应该负责人的人却还留下了,也就是说,有问题的人还在,以前踩的坑,将来还要继续踩。 |

|
|
对于马克扎克伯格,焦虑的心情可以理解,毕竟Meta的AI部门一个高管的年薪比DeepSeek训练一个模型的成本还要高,结果这帮货愣是搞不出一个像样的模型出来。 那就清理高层啊,而不是清理技术人员。 公司执行出问题,99%的原因都在组织管理能力上,而不是基层员工的技能上。 也许马克扎克伯格对Loss的感知没问题,但是他根据Loss调整的方法错了,他错误认为是现有技术人员不行,而没意识到(或者不敢承认)是管理组织上出了问题,所以,他就一边裁人,一边超高薪去OpenAI挖人;不相信现有人员的能力,而相信外来的后起之秀能拯救Meta AI。 我只能说这就是――饮鸩止渴。 写在最后 正好新的一年开始,看田渊栋的2025总结,让我就想到现实世界和AI世界其实还是很相似,都可以利用Loss函数来评估自己是否要做人生调整。 有一些Loss是预期中的,但是也完全有可能Loss是预料之外的,没关系,人生就是一个学习和尝试的过程。 和机器学习不同,机器学习的Loss Function往往是固定的,但人是活的,人的Loss Function就应该是动态调整的,灵活永远是人类的优势。 希望大家在新的一年里,都能根据前一年的Loss找到更好的方向。 送礼物 还没有人送礼物,鼓励一下作者吧 |
|
其中两点让老董叔颇有共鸣, 就从对年轻人的启示和纯大模型技术方面、简单说这两点吧: 第一(对年轻人的启示)、 “职级已经没有意义,过去的经验也没有意义。人的价值从按照“本人产出的劳动数量及质量”来评估,变成了是否能提高AI的能力,人加AI要大于AI本身的产出,这样才行。” (引自2025年年终总结(二)) 田老师认识很深刻,这个判断和我之前反复强调的完全一致,即、当前大模型时代、本质上是属于年轻人的时代、不看重你过去多少年的积累、也无关你取得什么样的头衔、更不在乎你具有多么深厚的资历、关键看实实在在的contribution,所以给了年轻人们展露头角提供了莫大的机会(不像过于看重经验和资历的行业那样) ――当然这部分年轻人,是极少数年轻人。 总结起来就是我常讲的那句话“大模型是年轻的事业,更是属于年轻人的事业(见:香港市民董先生 的想法”, ――就像老董叔在那首广为流传的小诗中、写得那样: ==== 你来自哪里? 你年龄多大? 你什么专业? 你是哪个大学? 毕业还是肄业? 你是什么学历? 本科还是博士? ――这些都不重要, 重要的是, 那篇聚光灯下众人津津乐道的technical report上, 有没有你的名字。 你的过去无人在意, 你的功绩永世长存。 ==== 另外在前几天的想法中、我也提到了大模型行业对年轻人的友好:“AI领域非常年轻,年轻到一个人只要读10/20/30篇论文,就能学到整个领域的核心”。Mark Chen给出的一个入门建议:花三到六个月,选一个项目(比如复现DQN),你就能非常快地走到前沿。 不过我觉得其实现在AI coding能力这么强的时代、已经远远用不了这么长时间来复现一个非常basic的RL项目(见 强化学习 Reinforcement Learning 之美在于什么? 和 Priors Really Matter! ―― 兼谈强化学习的前世今生)。 (另外需要简单补充两点:1.mark chen 当年复现DQN的时候强化学习刚火,尤其是应用在游戏场景,比如DOTA2,与现在主流场景不同。所以不要过度纠结于是什么项目,哪怕是能快速上手的AI Agent项目就非常不错、关键是要get your hands dirty. 2. 所谓读十几二十篇paper就能学到整个AI领域核心、在从业者看来确实如此,――但其实又没这么简单、需要大量内化的基础和第一点的项目实践、才能真正谈得上读懂。) ==== 第二(纯技术角度)、 田老师在离职前被安排去救火llama4、负责后训练推理方向。 这篇文章The path not taken提到:“RL则因为用on-policy的数据进行训练,权重的主分量不变,改变的只是次要分量,反而能避免灾难性遗忘的问题,而改变的权重其分布也会较为稀疏”(引自2025年年终总结(一)) 从权重的主分量和次要分量角度、对比了LLM post-training 中SFT和RL。这篇结论和前段时间Thinking Machines Lab 的blog Lora without regret结论异曲同工、只是角度略有不同、非常有意思。 RL 训练每个rollout 的奖励很稀疏、john schulman 从信息论角度分析只有大概1 bit 反馈信号(特别是2025年火热的RLVR、GRPO 系列拿掉了value function / critic model)、于是可以在Lora训练RL adapter时、大幅降低rank,――这与田老师从模型权重角度的分析完全对应。 送礼物 还没有人送礼物,鼓励一下作者吧 |
|
高赞说大模型对年轻人友好。我想说,这并不是核心。应该说什么技术对年轻人不友好?年轻人天然脑子活络,学什么都快。我10年前,20多岁的时候,学东西,思维能力,比我现在快多了。但是大模型还没复杂到说我一个30多岁的人,甚至比我更大的,40多岁的人就学不会的地步。因为本质上他并没有脱出深度学习框架太远,和以前的知识是一脉相承的。譬如transformers,我很早就用来处理过数据,ViT也都是老东西。甚至我本来是搞CV的,花了几个月也转到了LLM,甚至现在VLM的方向。 大模型现在最大的护城河,是显卡。因此技术开始往大企业进行集中。现在最优秀的大模型研究者并不在高校,而在互联网公司,因为这些人有大量的操作经验,也有大量的显卡支持他们。因此现在对大模型最熟悉的人反而不是最年轻的那一批(就是22-27岁,还在学校读书的),现在对大模型最熟悉的,反而是28-32岁的人,就是在大公司工作了几年的。 这点其实我老早就意识到了,我从23年初就开始到处讲,显卡才是核心资产,抢什么都不如抢显卡。那会儿阿里云上甚至还有一堆A100没人要。 DL从很早开始就是一个经验工程。譬如我们做CV,有很多知识都是我们在训练中学习的,论文里也不会写(因为高校做的toy example他遇不到这些问题),我们就算知道的也不会和你讲。现在LLM同样是这样。譬如RLVR,你实际上手做,就会发现门道很多,问题很多,并不是直接跑就可以的,尤其是如果你的任务不是AIME那些。但是如果你没有足够的资源,你就了解不了这些门道,这些门道论文里也不会有,因此这和以前我们搞AI其实是类似的,都是“护城河”。很多时候为什么互联网企业会给AI算法工程师很高的薪水?因为相比较他们的薪水,显卡价格更贵,贵得多。找个啥都不懂的人过来折腾两个月浪费的显卡和机器的钱,远多于多花几十万甚至几百万请个有经验的人来直接弄。 |
|
|
| [收藏本文] 【下载本文】 |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
|
娱乐生活:
电影票房
娱乐圈
娱乐
弱智
火研
中华城市
印度
仙家
六爻
佛门
风水
古钱币交流专用
钓鱼
双色球
航空母舰
网球
乒乓球
中国女排
足球
nba
中超
跑步
象棋
体操
戒色
上海男科
80后
足球: 曼城 利物浦队 托特纳姆热刺 皇家马德里 尤文图斯 罗马 拉齐奥 米兰 里昂 巴黎圣日尔曼 曼联 |
| 网站联系: qq:121756557 email:121756557@qq.com 知识库 |